マルチエージェント強化学習における局所的報酬と依存グラフによる明示的なクレジット割り当て
マルチエージェント強化学習において、全体の報酬を共有する「グローバル報酬」は協力行動を促すが、各エージェントの貢献度が不明確になる「貢献度割当問題」を引き起こし、逆に個別の「ローカル報酬」は学習は早いが、エージェントが利己的になり全体の最適性を損なうというジレンマが存在する。
TL;DR(結論)
マルチエージェント強化学習において、全体の報酬を共有する「グローバル報酬」は協力行動を促すが、各エージェントの貢献度が不明確になる「貢献度割当問題」を引き起こし、逆に個別の「ローカル報酬」は学習は早いが、エージェントが利己的になり全体の最適性を損なうというジレンマが存在する。 本研究は、エージェント間の相互作用を「依存グラフ(Dependence Graph)」としてモデル化し、グラフ上の経路に基づいて無関係な報酬を切り捨てることで、グローバル報酬の協力性とローカル報酬の学習効率を両立させる新しいポリシーグラジエント手法を提案した。 実験では、エージェント数が多い環境において、提案手法が従来のグローバル報酬設定やローカル報酬設定を上回る性能を示し、ノイズを含むグラフ近似の下でも効果的に機能することが確認された。
なぜこの問題か
マルチエージェント強化学習(MARL)における協力行動の促進は、自動運転や分散電圧制御、群れ(スウォーム)の調整といった複雑な実世界の課題を解決するために不可欠である。 しかし、複数のエージェントが共通の目的を追求する際、報酬をどのように設計し、各エージェントに分配するかという点において、大きなトレードオフが存在する。 最も単純な協力の強制方法は、全エージェントの報酬を合計または平均して「グローバル報酬」として共有する「完全協力設定」である。 この設定では、グループ全体の損失が各エージェントの損失となるため、共通の目的を最適化できるが、一方で「貢献度割当(Credit Assignment)」という深刻な問題が発生する。 グローバル報酬には全エージェントの行動の結果が含まれているため、個々のエージェントが自分のどの行動が報酬に寄与したのかを判断することが難しく、エージェント数が増えるほど報酬信号にノイズが混じり、学習が停滞する。 対照的に、各エージェントが自身の「ローカル報酬」のみを最適化する「独立学習」のアプローチは、貢献度が明確であるため学習が非常に速いという利点がある。…
核心:何を提案したのか
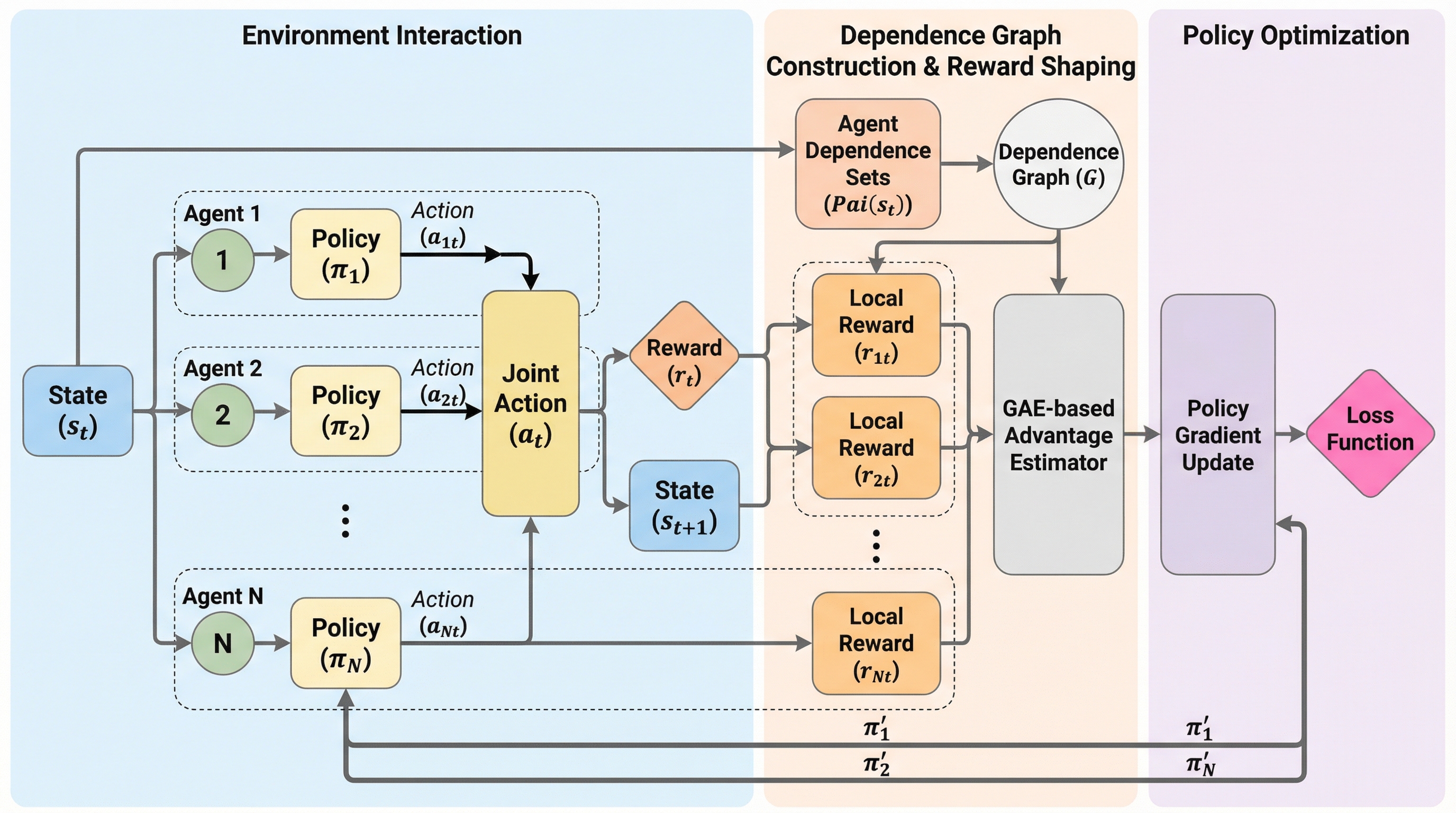
本研究の核心は、エージェント間の相互作用をグラフ構造で捉える「依存グラフ(Dependence Graph)」を導入し、ボトムアップの形式で明示的な貢献度割当を行う手法を提案したことにある。 具体的には、ネットワーク化されたマルチエージェント・マルコフ決定過程(Networked Multi-Agent MDP)の枠組みに基づき、エージェント間の依存関係を考慮した新しいポリシーグラジエント(政策勾配)推定量(Estimator)を開発した。 この手法は、依存グラフ上の相互作用パス(経路)を確認し、あるエージェントの行動が他のエージェントの報酬に影響を与えない時間帯や対象を特定することで、無関係な報酬信号を勾配計算から切り捨てる(Truncate)仕組みを持つ。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related