マルチエージェント強化学習における局所的報酬と依存グラフを通じた明示的なクレジット割り当て
マルチエージェント強化学習において、全エージェントの報酬を統合するグローバル報酬は協力行動を促すが、各個体の貢献度が不明瞭になるクレジット割り当て問題を引き起こし、学習のノイズを増大させる。 一方で、個別の局所報酬を用いる手法は学習速度に優れるものの、エージェントが自身の利益のみを追求する利己的な振る舞いに陥りやすく、システム全体の最適性を損なう「報酬のジレンマ」が存在する。 本研究が提案する手法は、エージェント間の相互作用を依存グラフとしてモデル化し、影響が及ぶ経路に基づいて不要な報酬信号を遮断することで、協力の維持と効率的な学習を両立させる明示的なクレジット割り当てを実現した。
TL;DR(結論)
マルチエージェント強化学習において、全エージェントの報酬を統合するグローバル報酬は協力行動を促すが、各個体の貢献度が不明瞭になるクレジット割り当て問題を引き起こし、学習のノイズを増大させる。 一方で、個別の局所報酬を用いる手法は学習速度に優れるものの、エージェントが自身の利益のみを追求する利己的な振る舞いに陥りやすく、システム全体の最適性を損なう「報酬のジレンマ」が存在する。 本研究が提案する手法は、エージェント間の相互作用を依存グラフとしてモデル化し、影響が及ぶ経路に基づいて不要な報酬信号を遮断することで、協力の維持と効率的な学習を両立させる明示的なクレジット割り当てを実現した。
なぜこの問題か
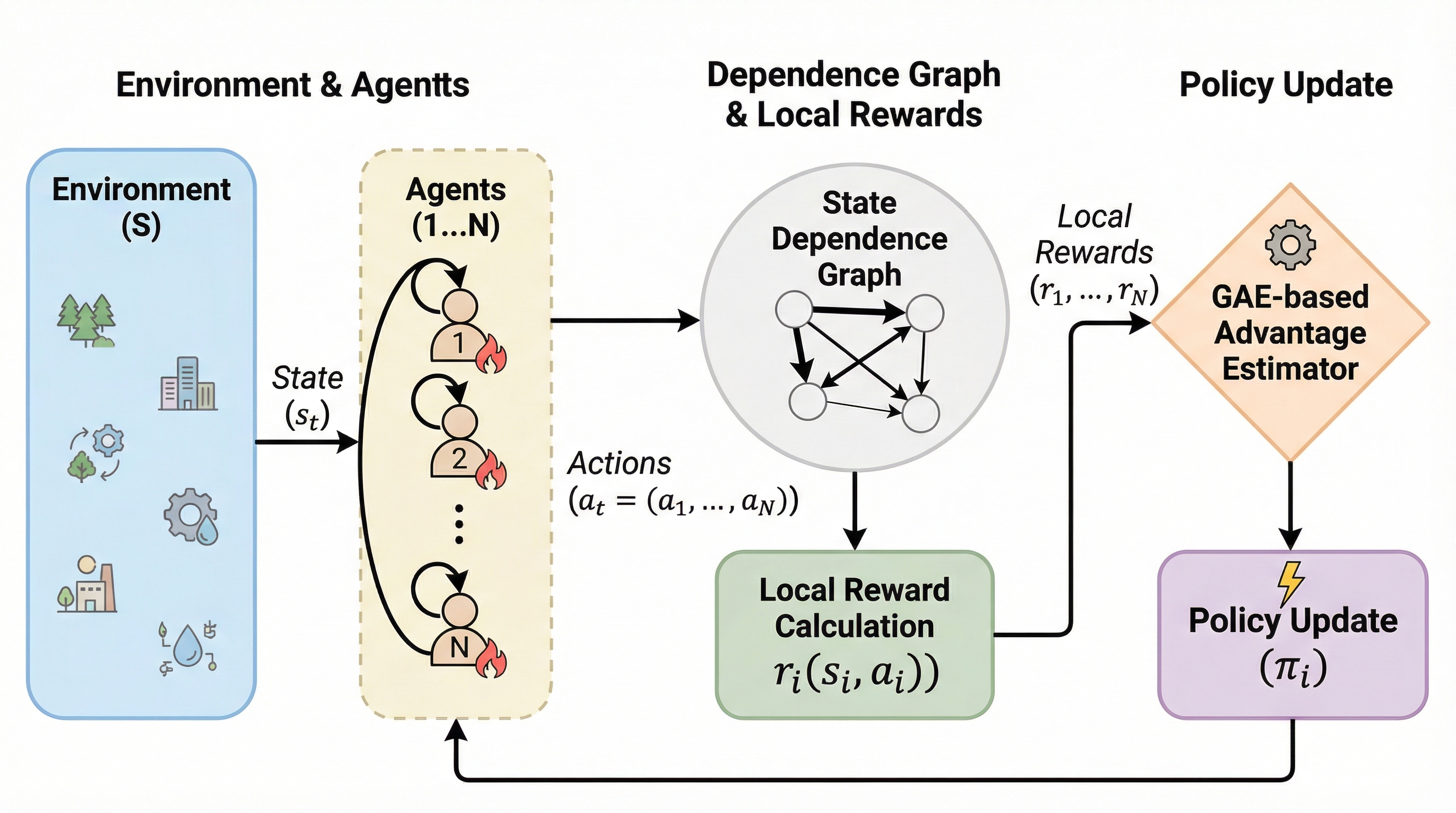
マルチエージェント強化学習(MARL)における協力の促進は、自動運転や分散電圧制御、群制御といった複雑な実世界の課題を解決するために不可欠な要素である。 しかし、複数のエージェントが共通の目標を達成しようとする際、報酬をどのように設計し、各個体に分配するかという問題は極めて困難である。 伝統的な手法の一つである報酬の集約(スカラー化)では、全エージェントの報酬の合計を共通の学習信号として利用するが、これには大きな欠点がある。 集約された報酬には全エージェントの行動の結果が混ざり合っているため、特定のエージェントがどの程度全体の成功に貢献したかを判別することが難しくなる。 これがクレジット割り当て問題であり、エージェント数が増えるほど学習信号に含まれるノイズが増大し、学習の収束が著しく遅れる原因となる。 対照的に、各エージェントが自身の局所的な報酬のみを最適化する独立学習の手法も存在する。 このアプローチは、他者の報酬を考慮しないため計算が単純でスケーラビリティに優れ、クレジット割り当て問題の影響を受けにくいという利点がある。…
核心:何を提案したのか
本研究の核心的な提案は、エージェント間の相互作用を表現する「依存グラフ」を活用し、局所報酬を適切に組み合わせることで明示的なクレジット割り当てを行う新しい方策勾配法である。 具体的には、ネットワーク化されたマルチエージェント・マルコフ決定過程(Networked Multi-Agent MDP)の枠組みを拡張し、状態の依存関係に基づいた報酬の計算を行う。 提案手法の第一の柱は、依存グラフ上の相互作用パスに基づいて、特定のエージェントの方策更新に関係のない局所報酬を切り捨てる「依存グラフ方策勾配」の導出である。 これにより、あるエージェントの行動が将来的に影響を及ぼす可能性のある他者の報酬のみを考慮対象とし、無関係なノイズを排除することが可能になる。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related