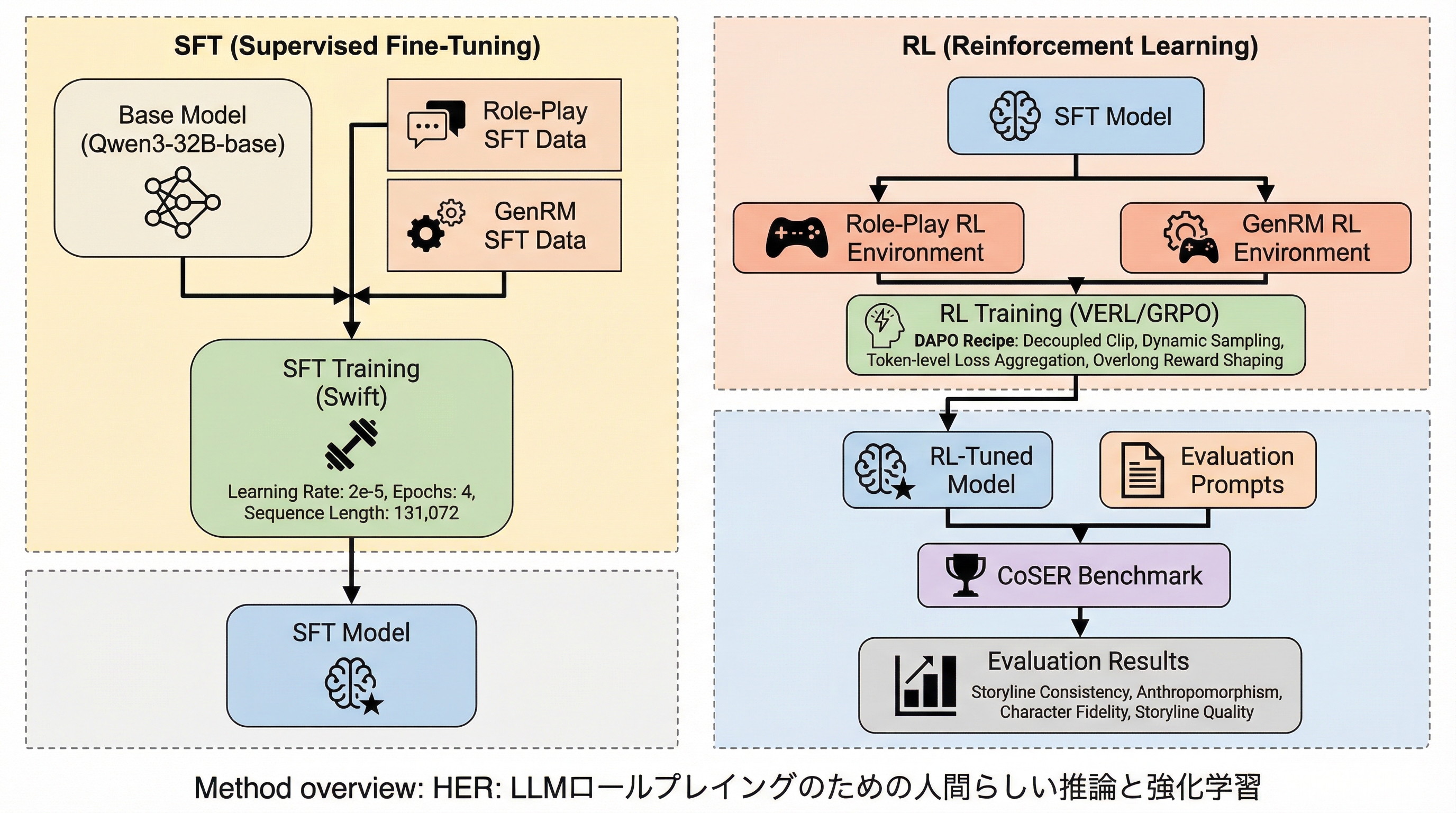
HER: LLMロールプレイングのための人間らしい推論と強化学習
HER(Human Emulation Reasoning)は、LLMのロールプレイングにおいてキャラクターの内面的な思考を高度にシミュレートするための統合フレームワークであり、隠された三人称視点の「システム思考」と、公開される一人称視点の「ロール思考」を分離した二層構造の思考プロセスを導入しています。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
HER(Human Emulation Reasoning)は、LLMのロールプレイングにおいてキャラクターの内面的な思考を高度にシミュレートするための統合フレームワークであり、隠された三人称視点の「システム思考」と、公開される一人称視点の「ロール思考」を分離した二層構造の思考プロセスを導入しています。
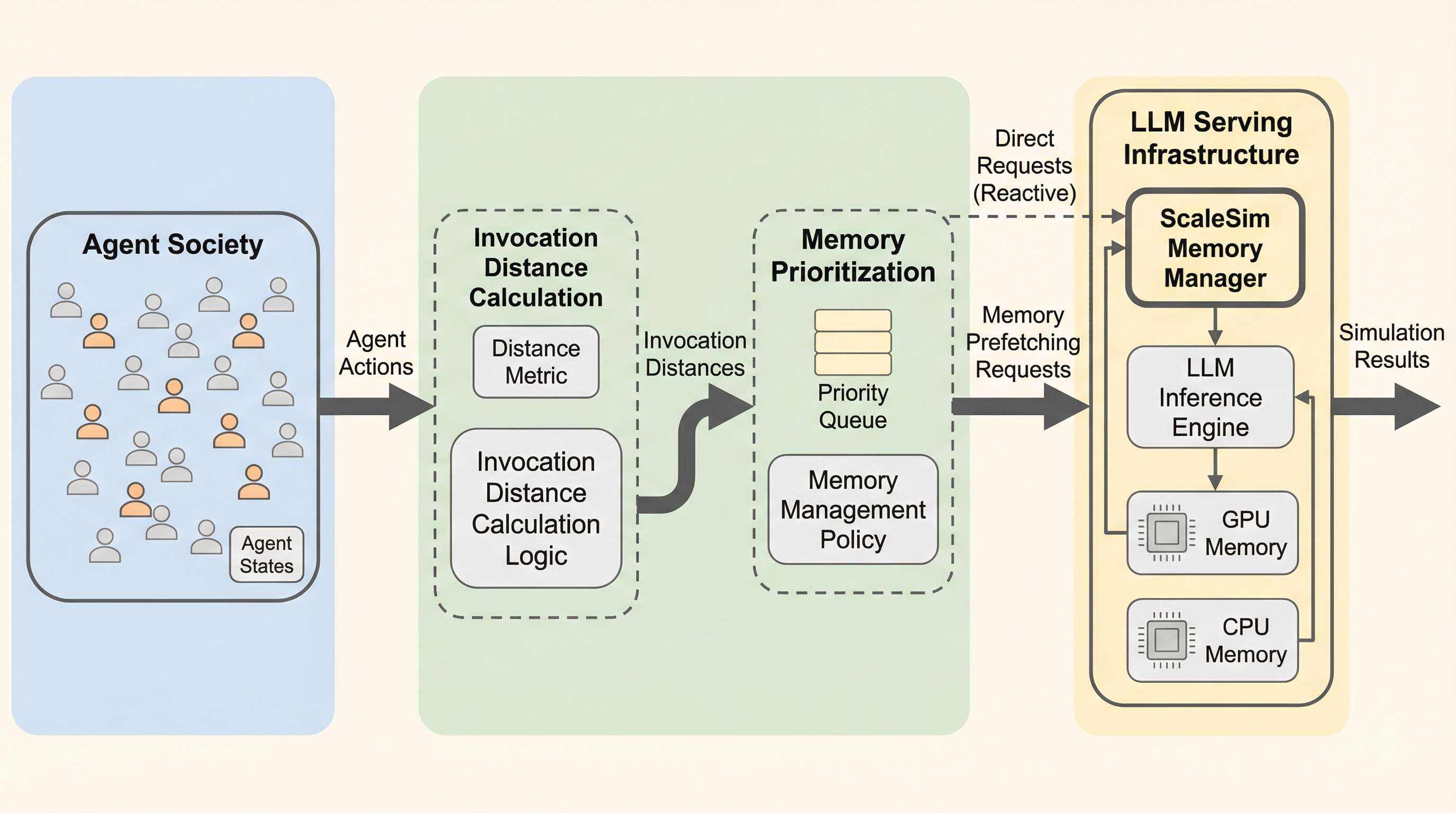
大規模なマルチエージェント・シミュレーションにおいて、各エージェントが個別に保持するLoRAアダプタやキャッシュなどの膨大なメモリ消費がGPUの物理容量を超え、頻繁なデータ転送による深刻な遅延が発生している。
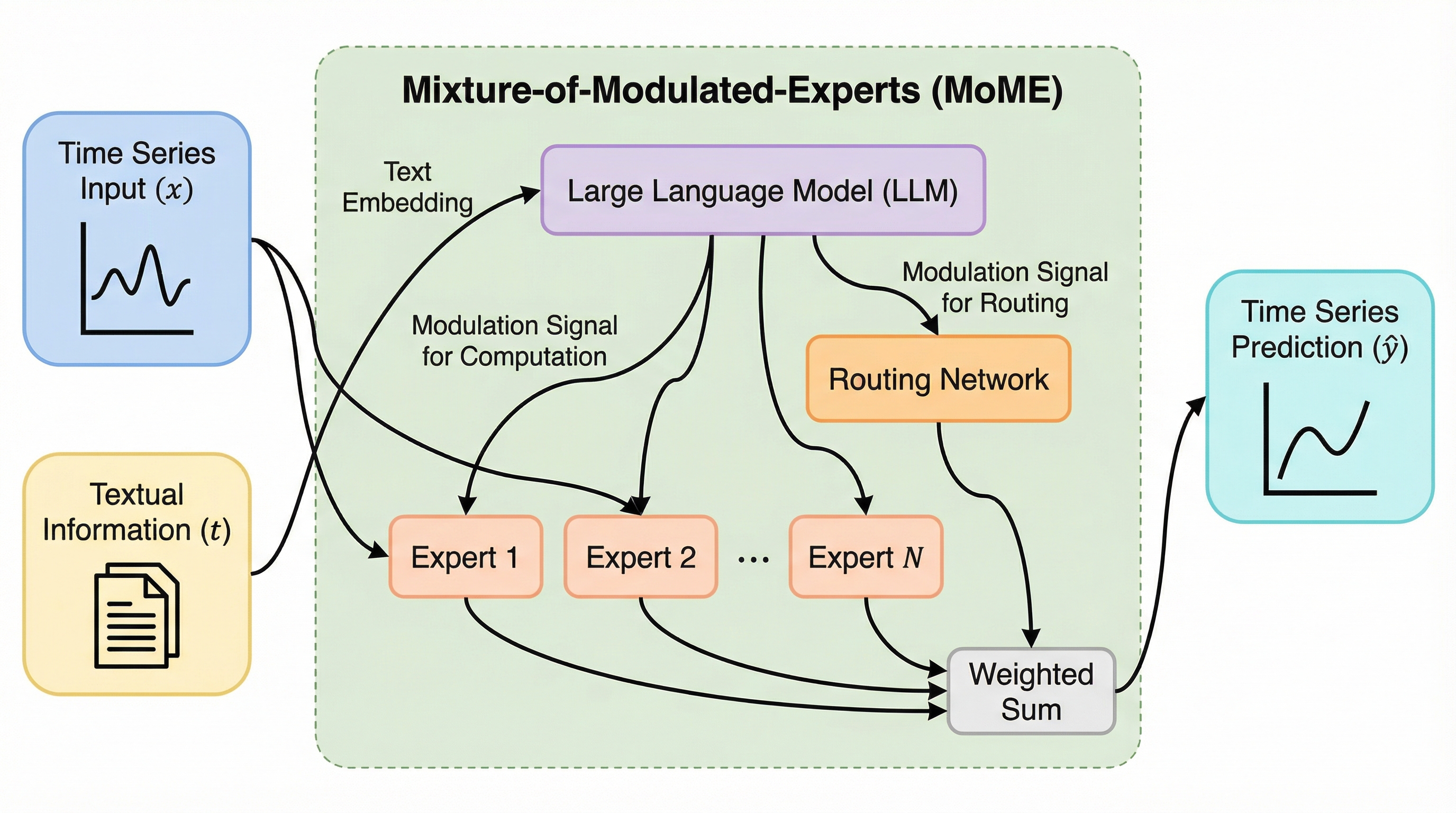
現実世界の時系列予測において、数値データとニュース等のテキスト情報を統合する際、従来のトークンレベルの融合ではノイズやデータの異質性が課題となっていたが、本研究ではテキスト信号が専門家(エキスパート)の選択と計算を直接制御する「Expert Modulation」という新しい枠組みを提案した。
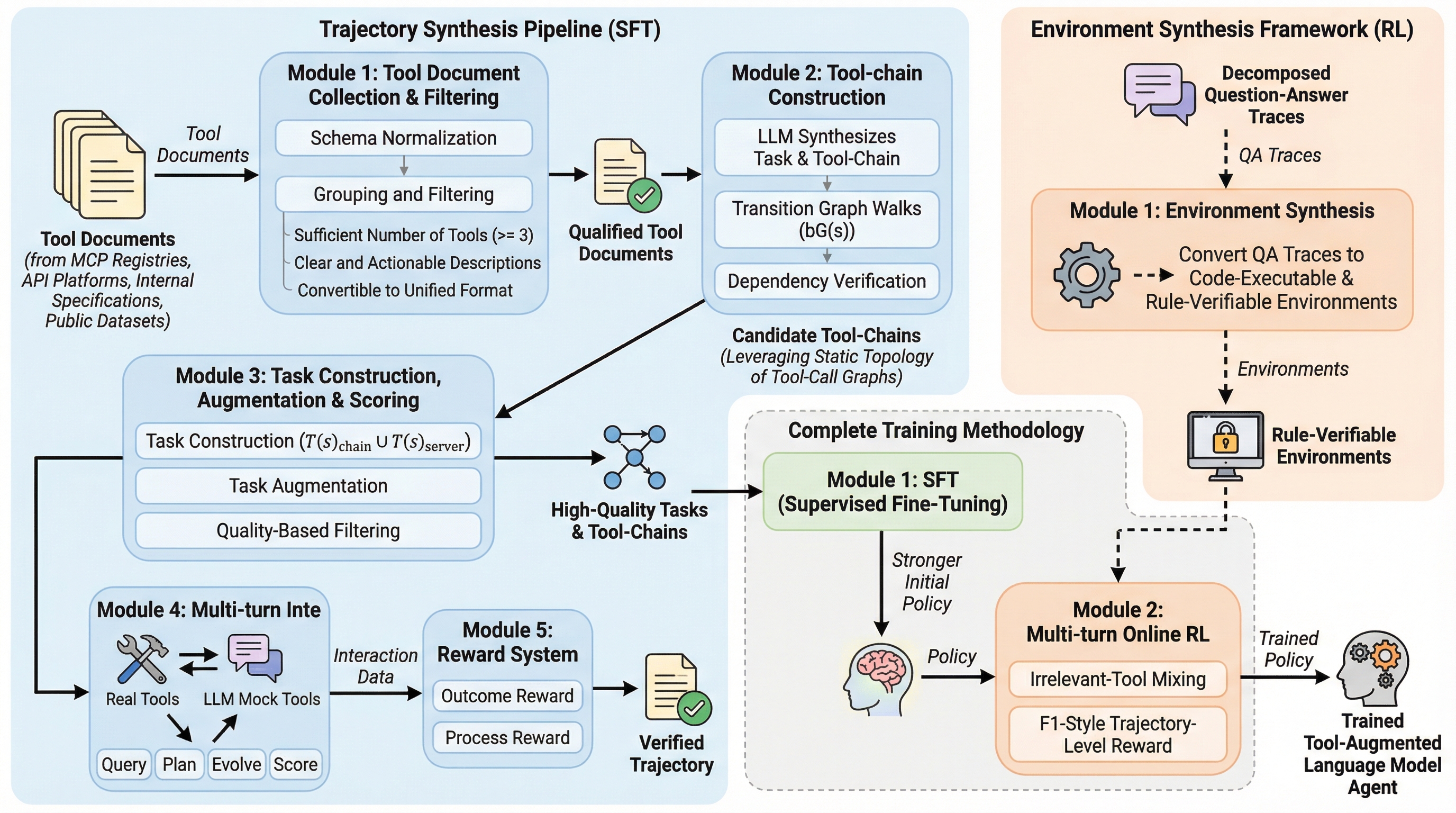
ASTRAは、ツール利用エージェントの訓練を完全に自動化するエンドツーエンドのフレームワークであり、大規模なデータ合成と検証可能な強化学習を統合することで、従来の手動介入や不確実なシミュレーション環境への依存を排除している。
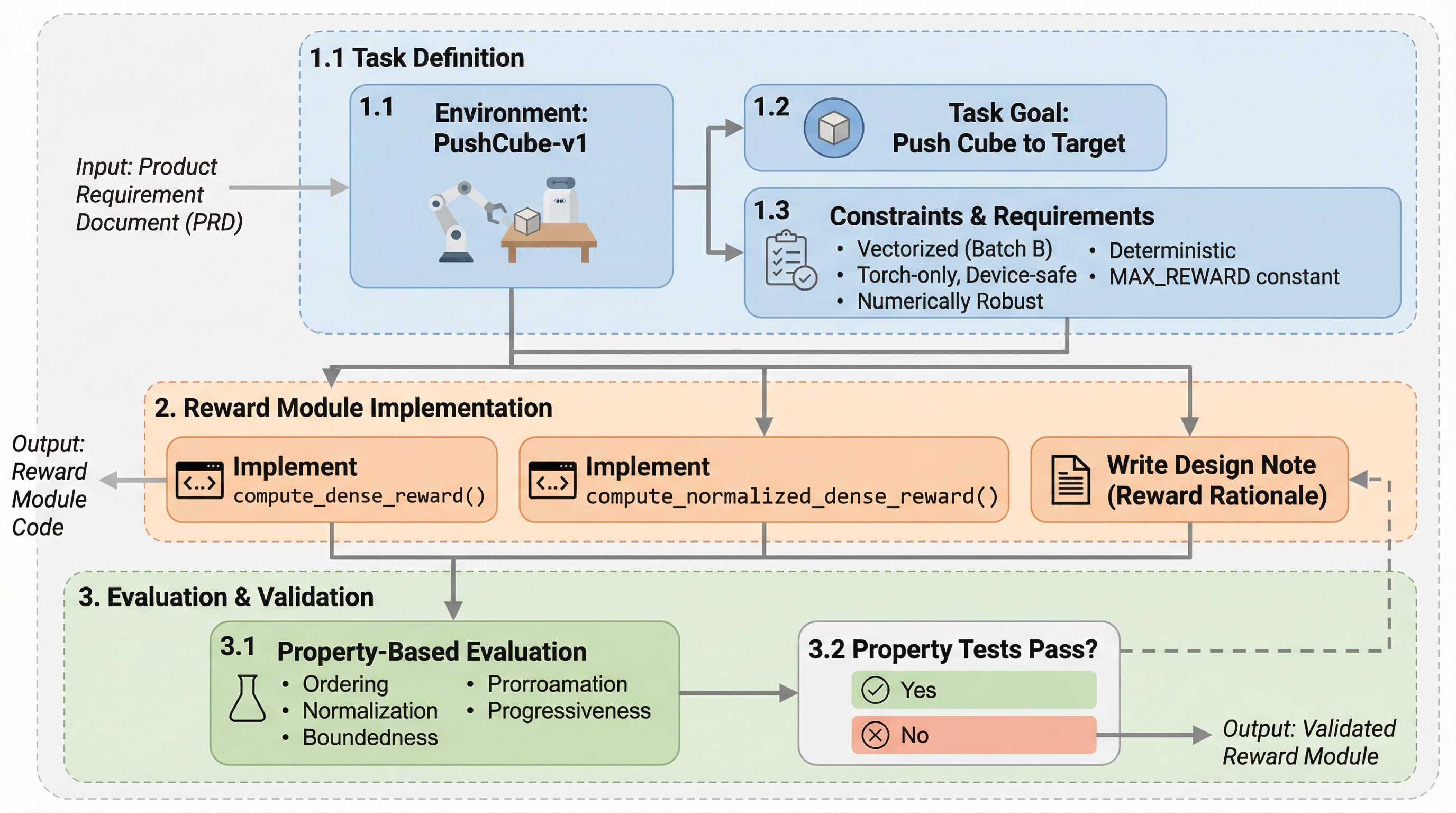
EmboCoach-Benchは、大規模言語モデル(LLM)を基盤としたエージェントが、ロボットの制御ポリシーを自律的に設計・実装・最適化する能力を評価するための、世界初のプロジェクトレベルのベンチマークである。
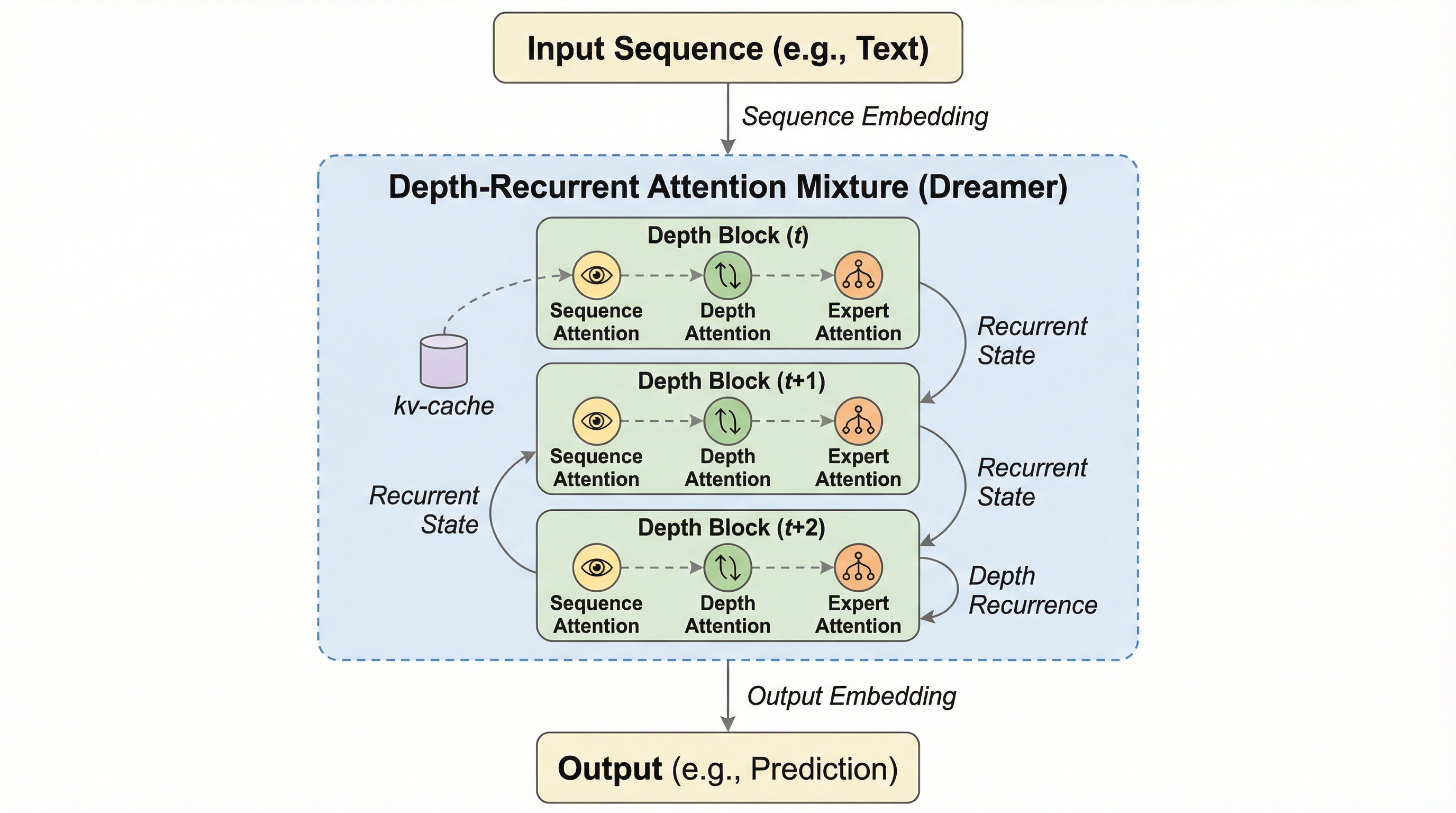
従来の思考連鎖(CoT)が抱える離散的な言語化の制約と計算コストの問題を、深層再帰とアテンション混合を統合した「Dreamer」フレームワークによって、潜在空間での効率的な多段階推論へと転換し、モデルの表現力を大幅に向上させた。
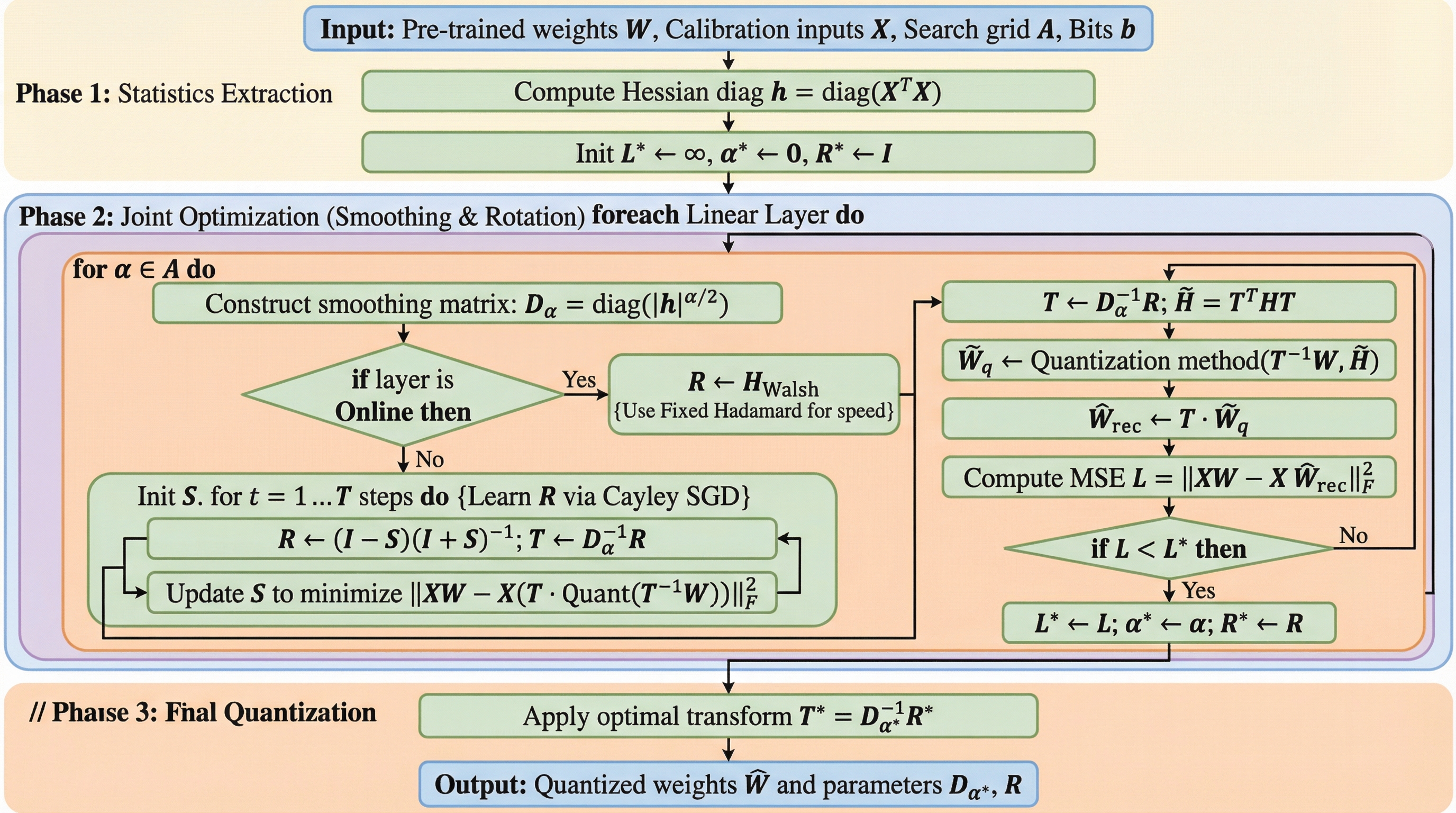
大規模言語モデル(LLM)の量子化において、重みの誤差が小さいにもかかわらず性能が急落する「低誤差・高損失」の矛盾を解決するため、損失曲面の幾何学的構造を改善する新フレームワーク「HeRo-Q」が提案されました。
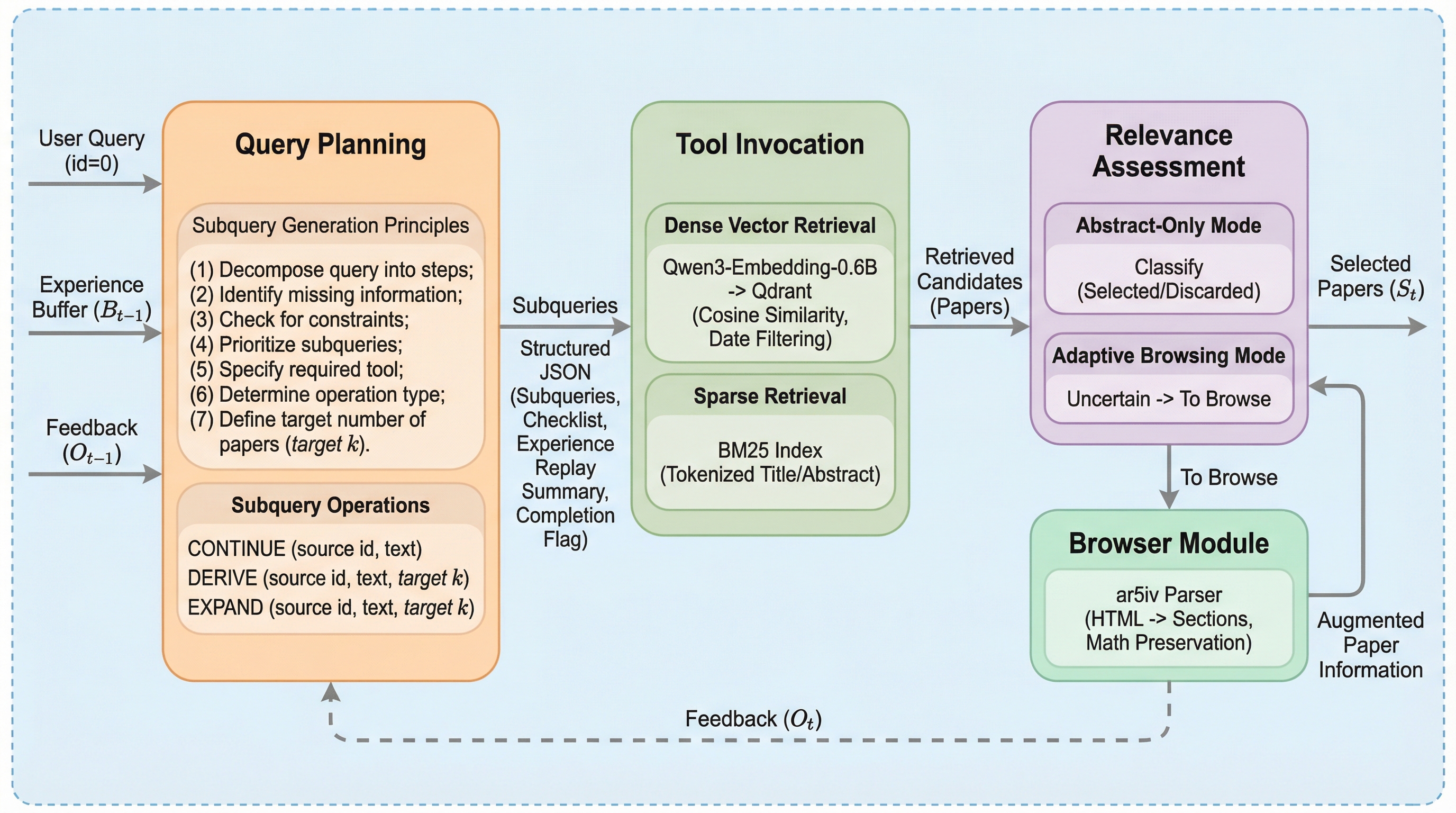
従来の学術文献検索の評価は、Google SearchなどのライブAPIに依存していたため、検索インデックスの更新やレート制限といった外部要因により結果が変動し、再現性が確保できないという根本的な課題がありました。
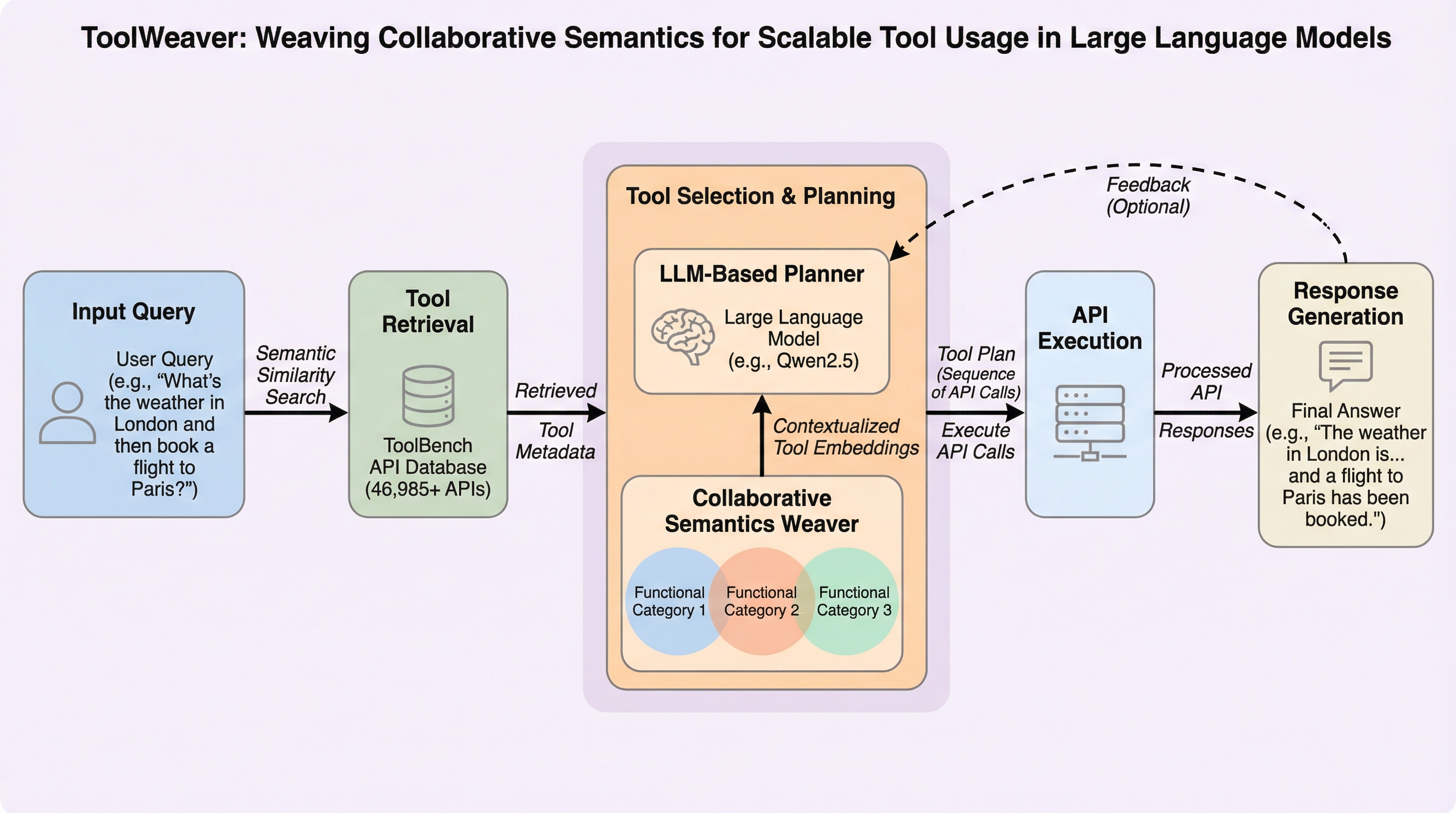
従来の大規模言語モデルにおけるツール利用手法は、ツールごとに固有のトークンを割り当てる方式により、語彙数の膨張とツール間の関連性学習の困難さという課題に直面していました。本研究が提案するToolWeaverは、ツールを階層的なコード配列として表現することで、語彙の拡張を対数スケールに抑制し、ツール間の共起関係を直接学習可能な構造を実現しています。 約47,000個のツールを用いた検証の結果、ToolWeaverは従来手法を大幅に上回る性能を示し、モデルの言語能力を維持しつつ複雑なタスクを完遂できる高い汎用性を証明しました。 具体的には、ツールの内的な機能と外的な共起パターンを結合する「協調認識型ベクトル量子化」を導入し、複数のツールを連携させる必要がある高度な推論タスクにおいて、既存の検索ベースや生成ベースの手法を凌駕する精度を達成しています。
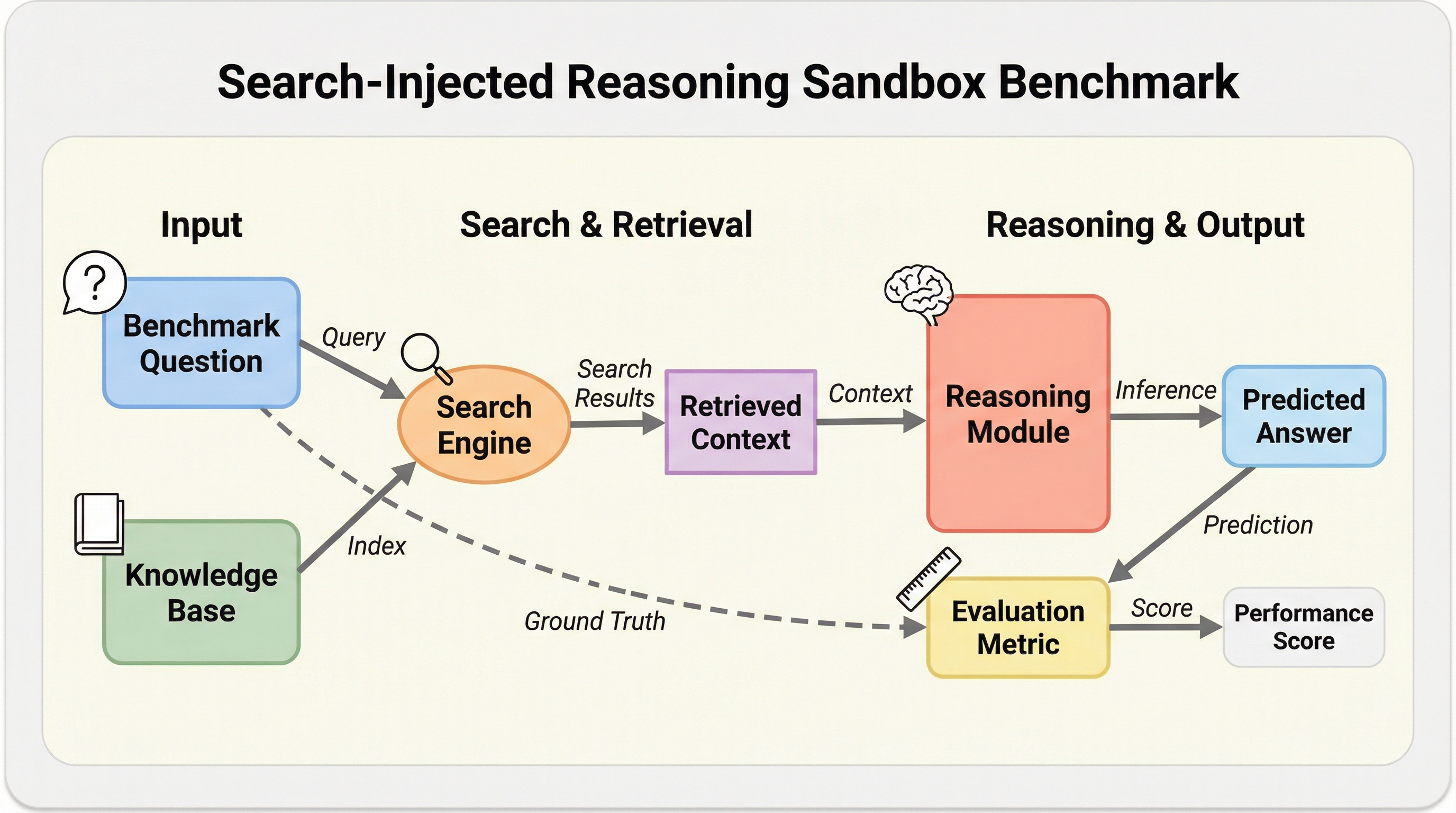
DeR2は、大規模言語モデルが未知の科学的情報に対して推論を行う能力を、検索プロセスから切り離して評価するための新しいベンチマークである。従来の評価手法では検索の失敗か推論の失敗かを判別できなかったが、本手法は2023年から2025年の最新の理論的論文に基づき、情報のアクセスレベルを4段階に分けることでエラーの原因を詳細に特定する。 評価設定として、命令のみ、概念のみ、関連文書のみ、全文書セットの4つのレジームを導入し、モデルがどの段階で性能を低下させているかを「検索損失」と「推論損失」として数値化する。これにより、モデルが学習済みの知識で解いているのか、あるいは提供された証拠を適切に処理して解いているのかを厳密に検証するプロトコルを確立している。 検証の結果、GPT-5.1やGemini-3-Proといった最新モデルでも、文書が与えられると推論モードへの切り替えに失敗する「モード切替の脆弱性」や、概念を正しく認識しても適用できない「構造的な概念の誤用」が明らかになった。このサンドボックスは、検索能力と推論能力の統合における現在の限界を可視化し、次世代AIの開発に向けた重要な指針を提供する。