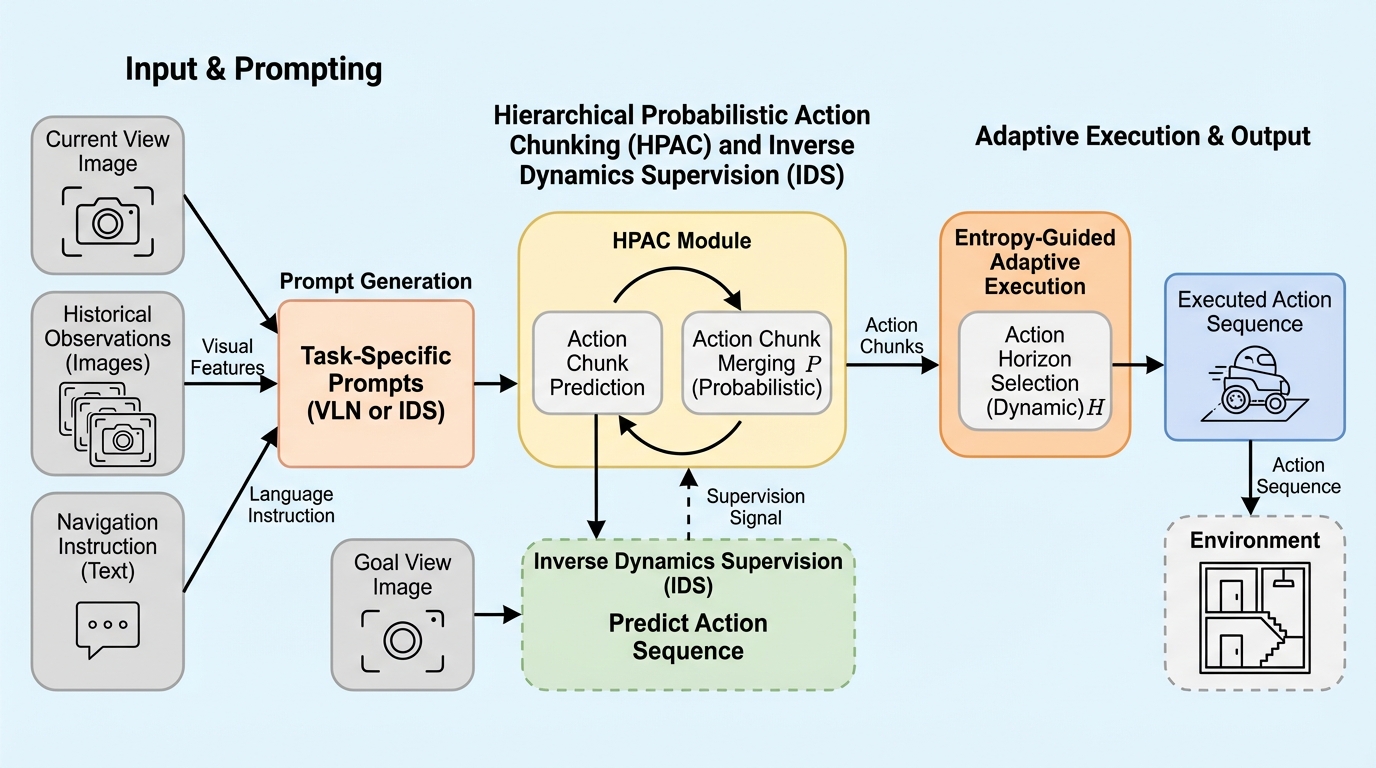
NaVIDA:逆動力学による拡張を用いた視覚言語ナビゲーション
視覚と言語を用いたナビゲーション(VLN)において、行動が視覚的な変化にどのように影響するかという因果関係を明示的にモデル化する新しいフレームワーク「NaVIDA」を提案し、従来のリアクティブな手法が抱えていた不安定な挙動や誤差の蓄積という課題を解決した。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
視覚と言語を用いたナビゲーション(VLN)において、行動が視覚的な変化にどのように影響するかという因果関係を明示的にモデル化する新しいフレームワーク「NaVIDA」を提案し、従来のリアクティブな手法が抱えていた不安定な挙動や誤差の蓄積という課題を解決した。
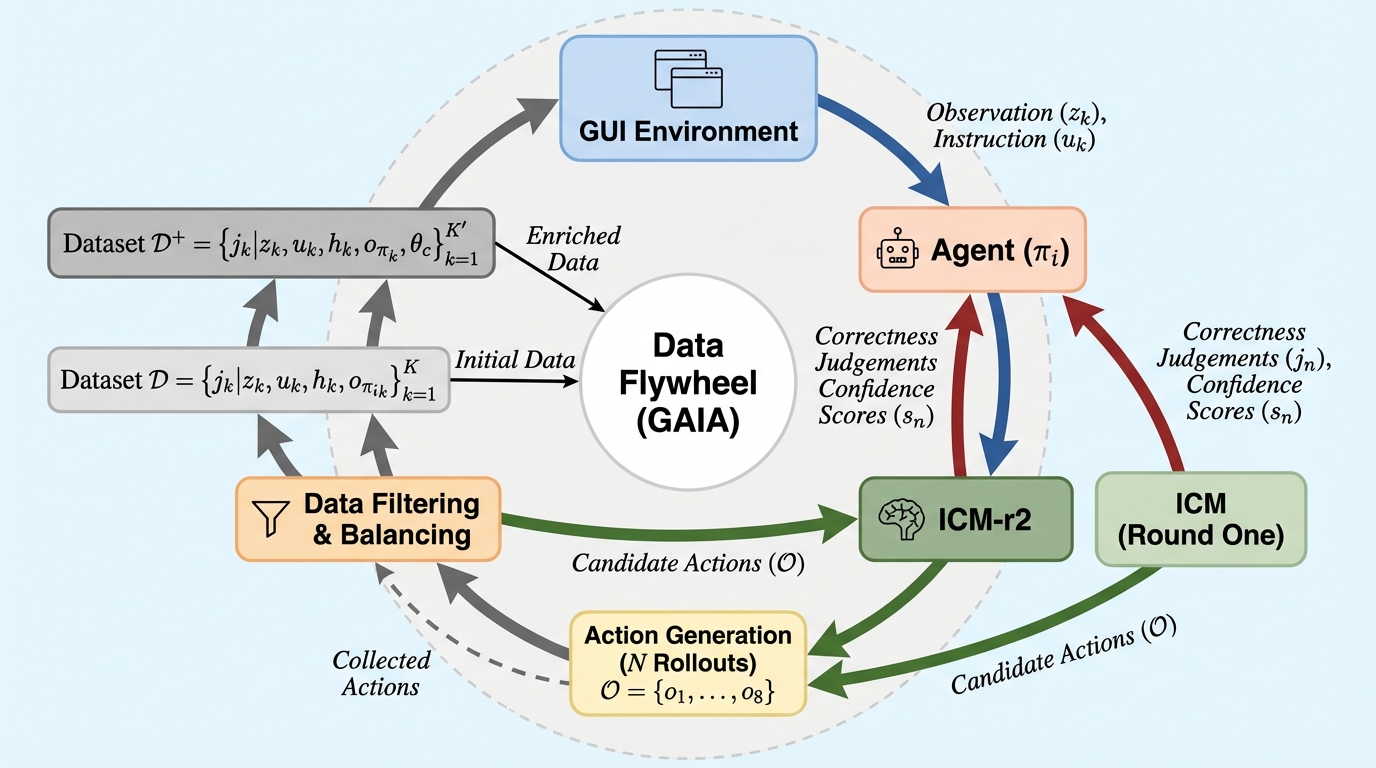
GUIエージェントの操作は一度の誤りが致命的な失敗を招く不可逆性を持つため、実行前にアクションの妥当性を評価する「直感的クリティックモデル(ICM)」と、その精度を継続的に向上させる学習フレームワーク「GAIA」を提案しました。
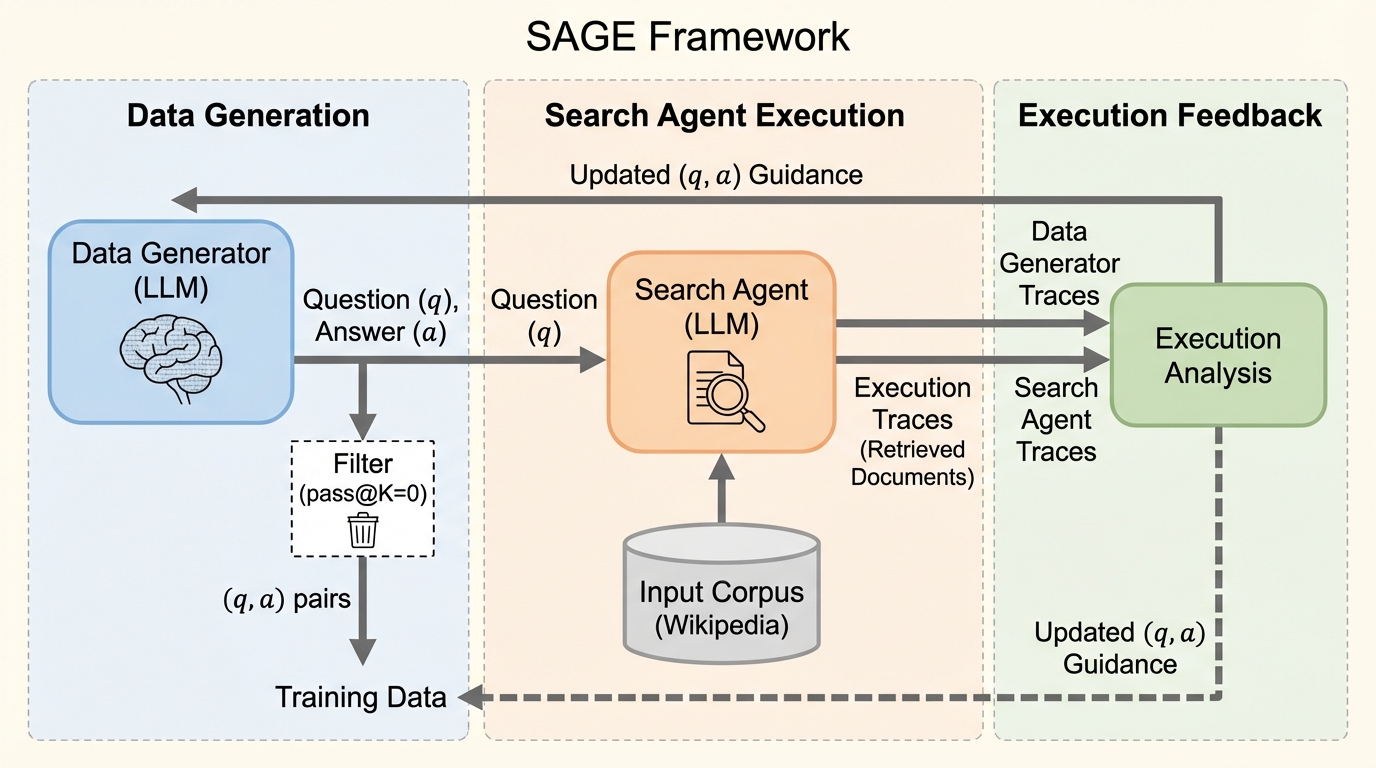
SAGEは、複数の文書を横断して推論を行うディープサーチエージェントの訓練を目的とした、難易度制御が可能な自律型データ生成パイプラインである。データ生成エージェントと検索エージェントが連携し、実際の実行結果をフィードバックとして活用することで、生成側の意図と実際の解法の乖離を解消し、高品質な質問応答ペアを自動構築する。
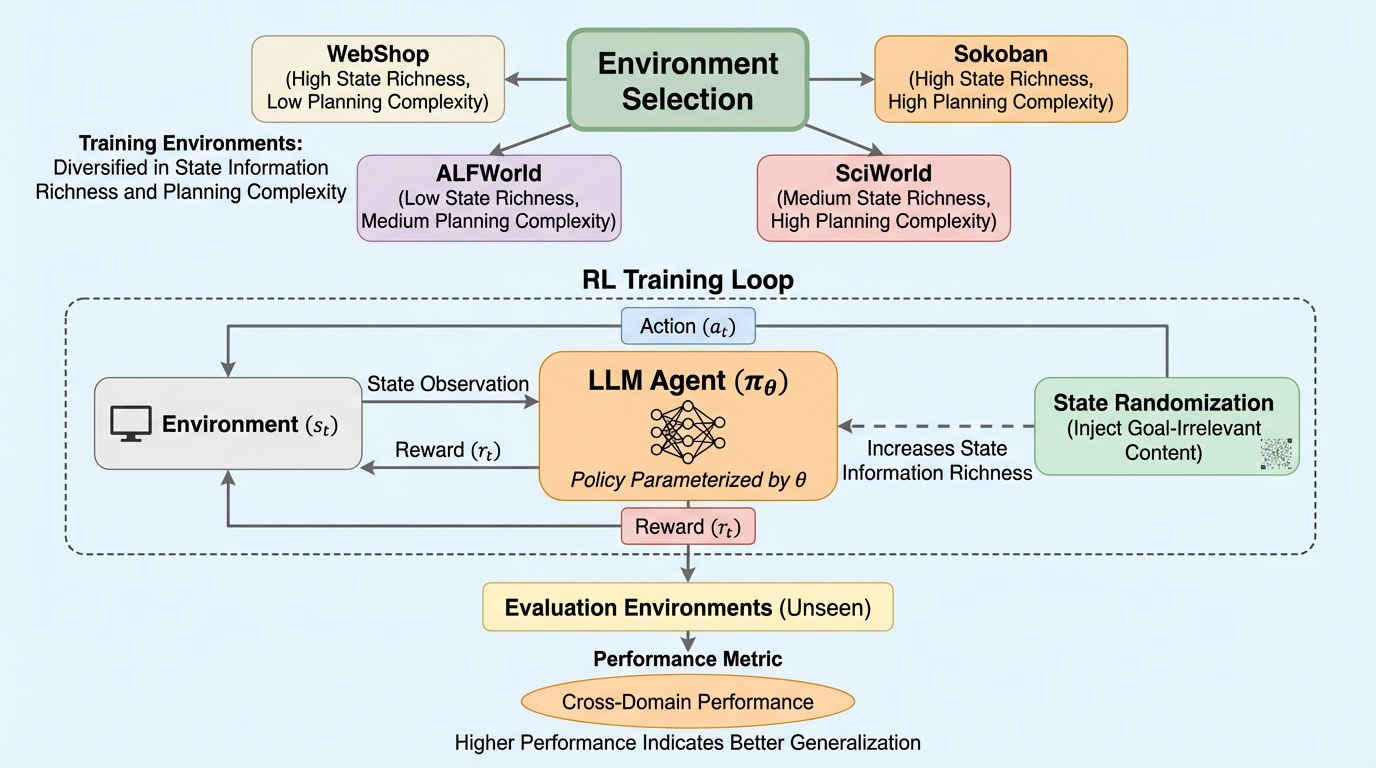
LLMエージェントを強化学習で訓練する際、学習した特定の環境には適応する一方で未知の環境での性能が低下する「汎化税」が大きな課題となっている。本研究では、4つの異なるエージェント環境を用いた詳細な分析を通じて、「状態情報の豊かさ」と「計画の複雑さ」という二つの環境特性が、未知のドメインへの汎化性能と強く相関することを突き止めた。 この知見に基づき、タスクの本質を変えずに状態情報へ少量の無関係なノイズを加える「状態ランダム化」手法を提案し、これが知覚的な堅牢性を高めて未知の領域での性能維持に有効であることを実証した。さらに、学習中にステップバイステップの思考を有効にすることが汎化において不可欠な役割を果たす一方で、教師あり微調整(SFT)によるウォームアップが学習ドメインの知識を固定し、未カバーのドメインへの汎化を阻害するというトレードオフを特定した。 最終的に、デプロイ先が不明な汎用エージェントを構築するための具体的な環境選定指針として、情報の密度が高く、長期的な推論を要求する環境での学習を推奨し、モデリング手法として明示的な推論プロセスと軽量な状態ランダム化の組み合わせを提示した。
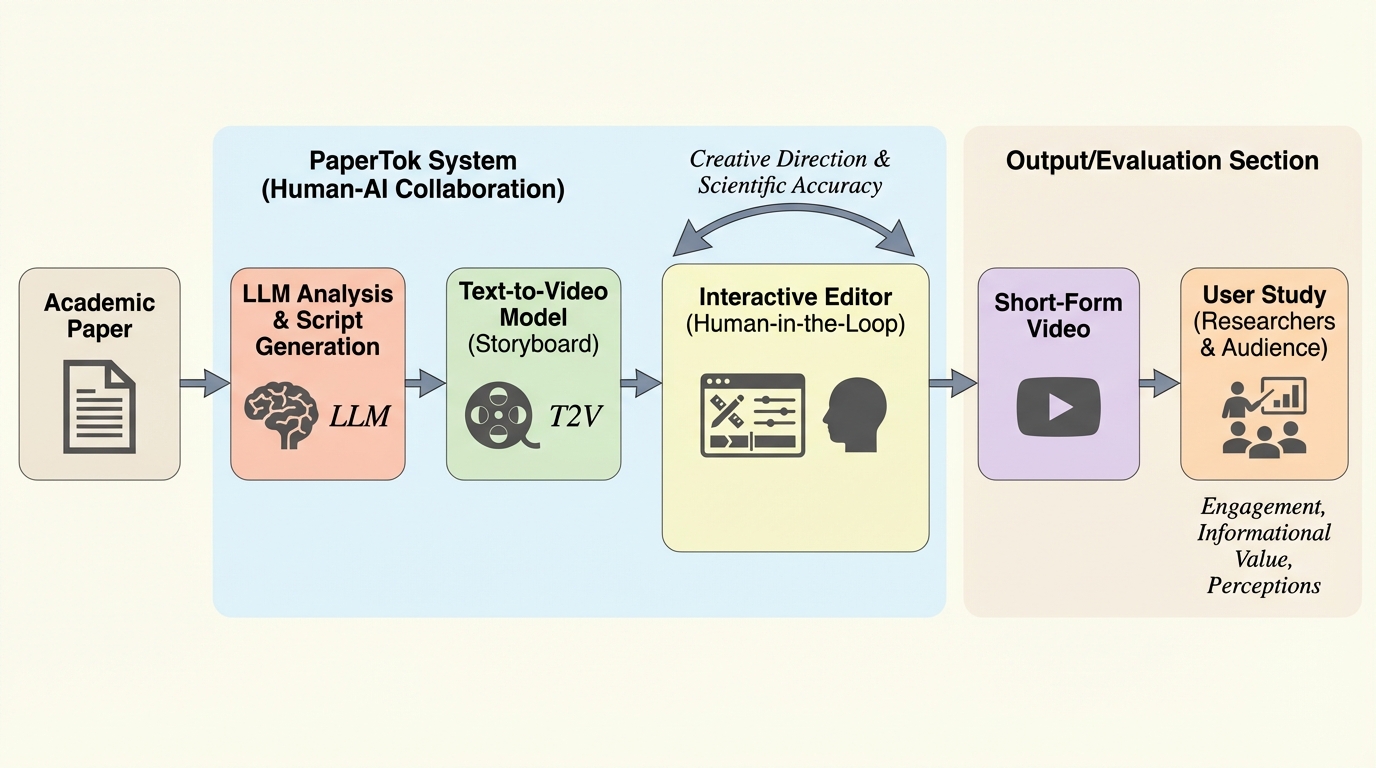
研究者が学術論文の内容をTikTokやInstagram Reelsのような短編動画へ変換する作業を支援するため、生成AIを活用した制作システム「PaperTok」が開発されました。 このシステムは、論文から脚本、音声、視覚的なストーリーボードを自動生成し、研究者が内容の正確性を維持しながら編集できる「人間とAIの協調ワークフロー」を提供することで、制作の負担を大幅に軽減します。 評価実験の結果、PaperTokで作成された動画は既存のツールよりも視聴者の関心を引きやすく、研究者にとっても専門知識を損なわずに魅力的な発信を行うための有効な手段であることが確認されました。
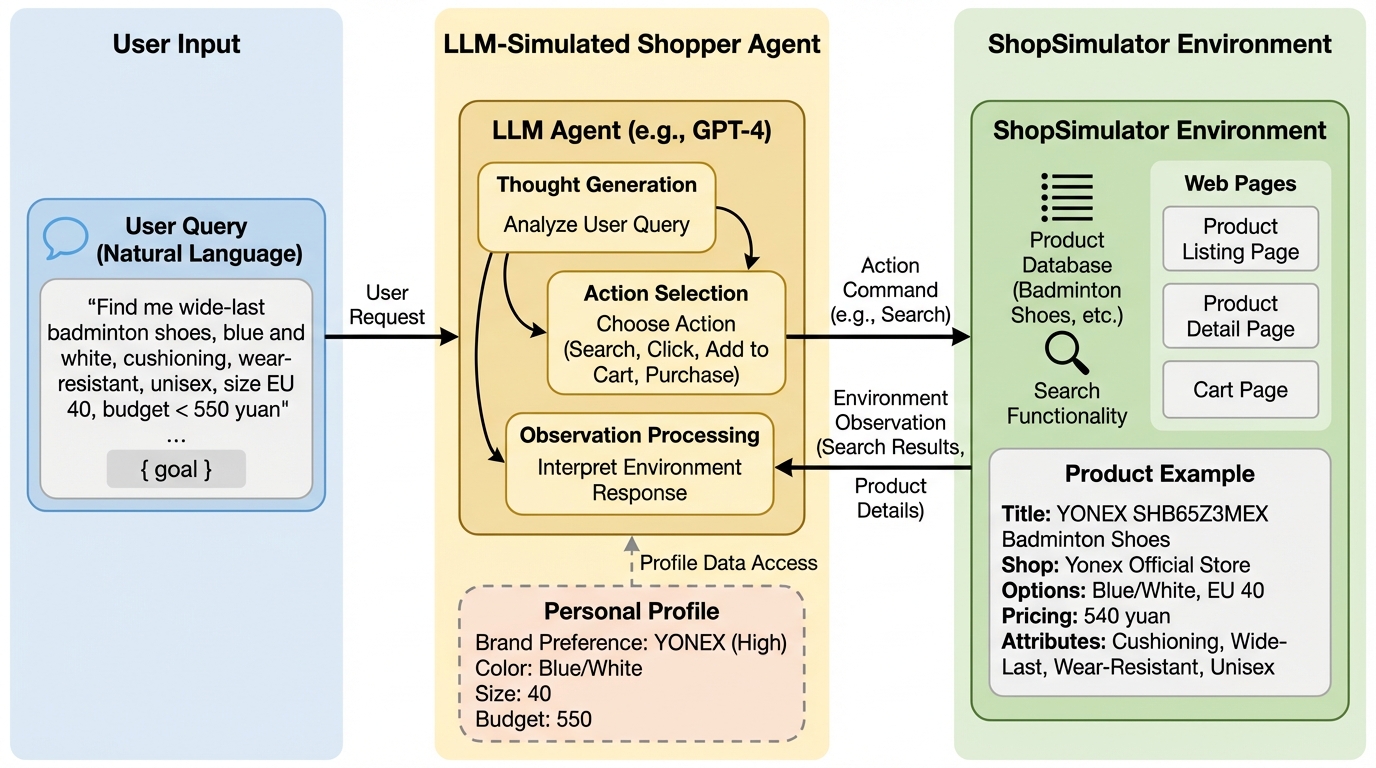
ShopSimulatorは、130万点以上の実商品データと詳細なパーソナライズ情報を備えた、中国語圏最大級のECエージェント学習・評価用シミュレーション環境であり、多ターン対話や細部属性の識別といった現実的な課題を統合している。
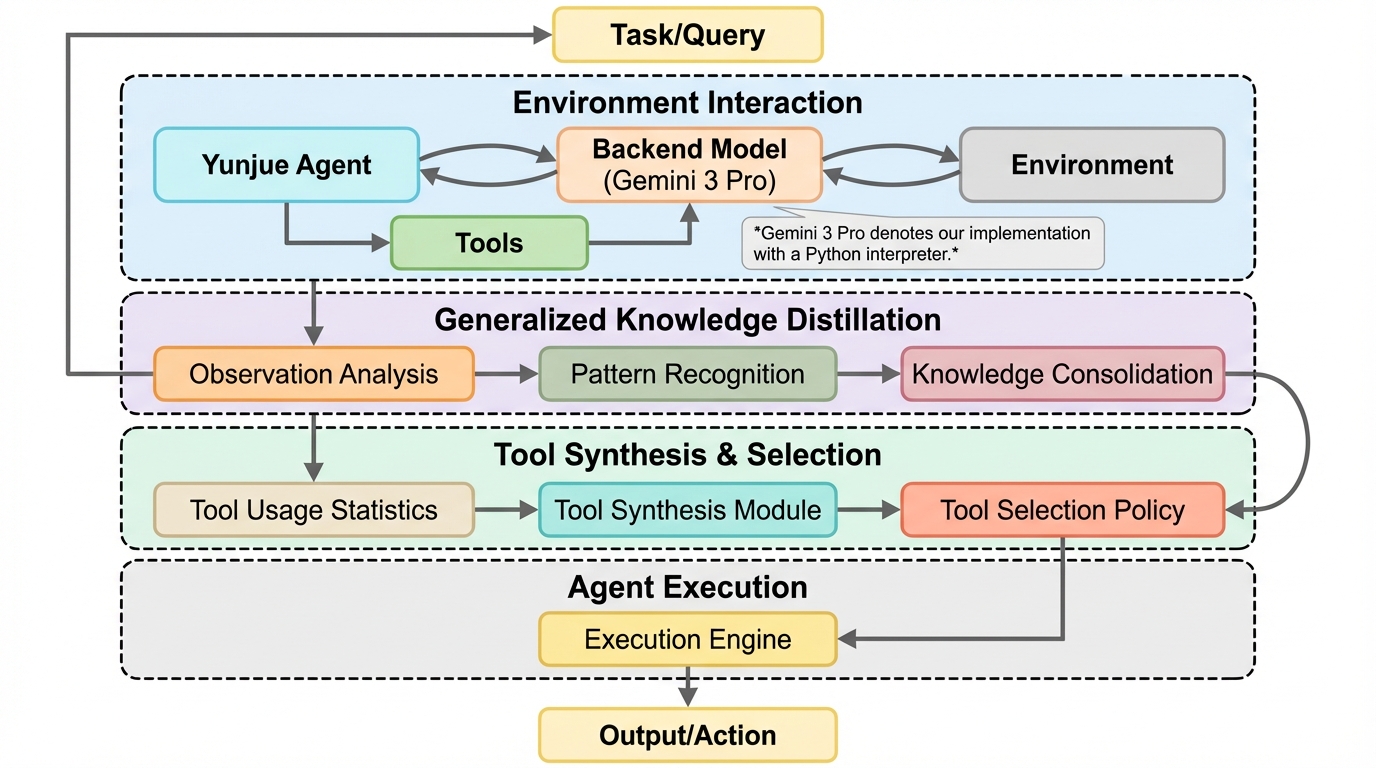
従来のAIエージェントが直面していた「未知の環境や変化するタスクへの適応不足」を解消するため、実行中にツールを自律的に生成・洗練・蓄積する「現場自己進化(In-Situ Self-Evolving)」という新しいパラダイムが提案されました。
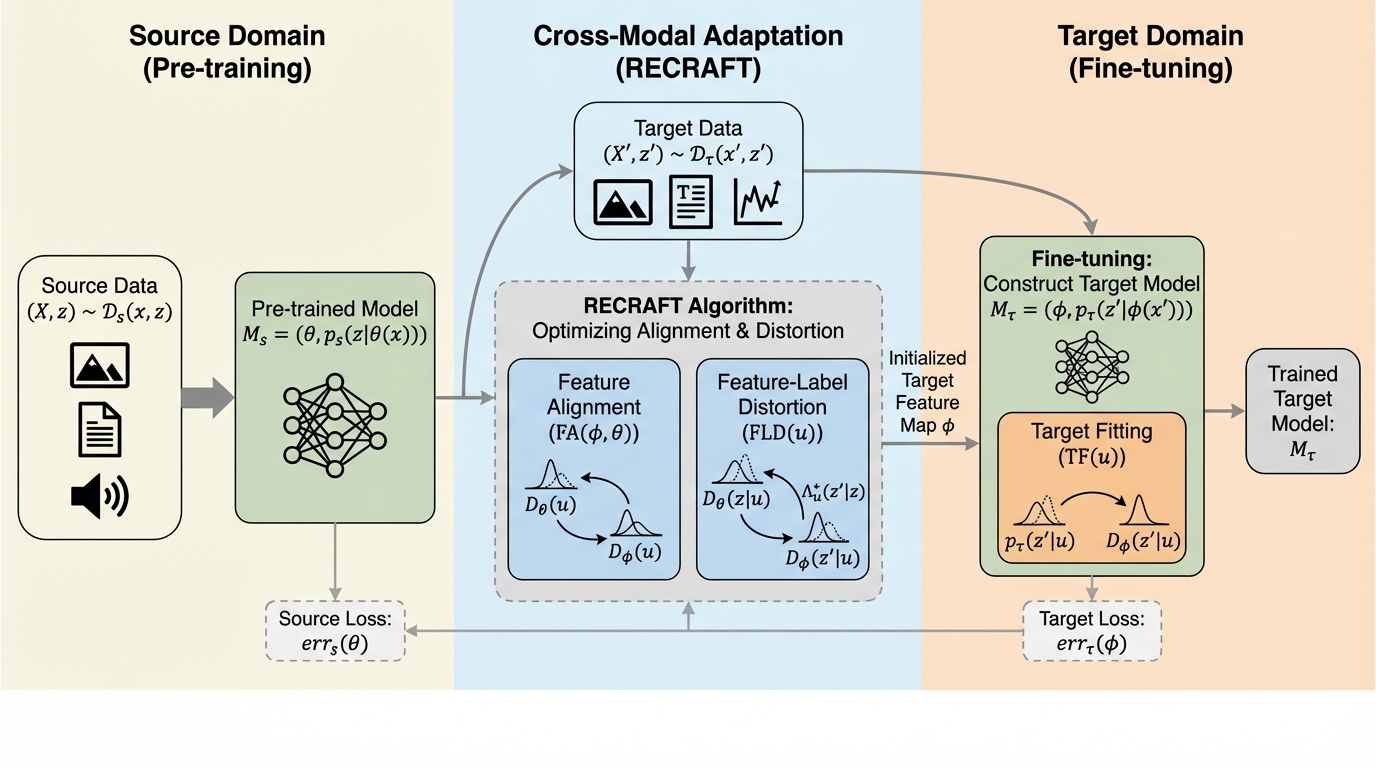
事前学習済みモデルを未知のデータモダリティに適応させるクロスモーダル・ファインチューニングにおいて、特徴量のアライメントとターゲットへの適合の間の理論的な相互作用を解明し、汎化誤差の境界を定義する新しい原理的フレームワーク「RECRAFT」を提案した。
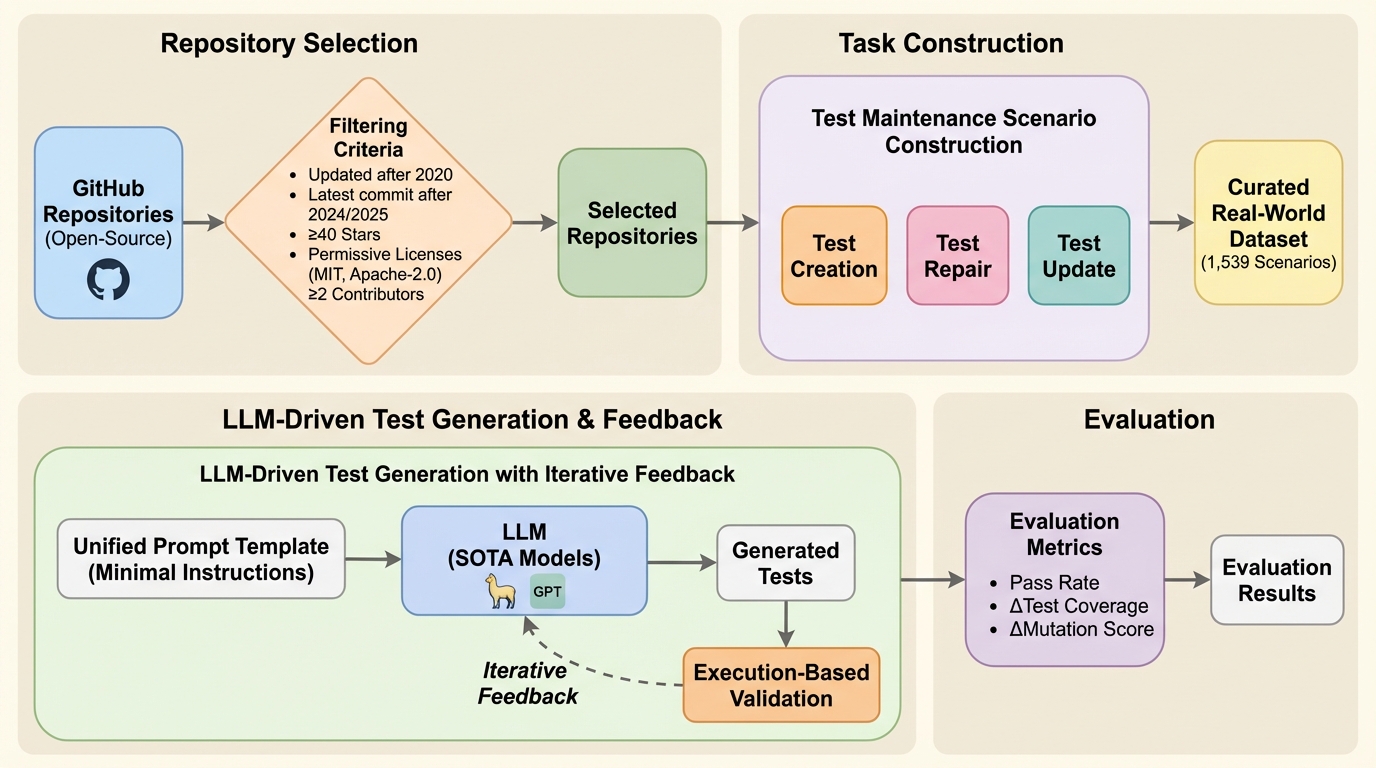
ソフトウェア開発における単体テストの保守は、全予算の最大25%を占める重要な工程だが、従来の大規模言語モデル(LLM)の評価は単発の生成に偏り、継続的な保守能力の検証が不足していた。 本研究が提案する「TAM-Eval」は、Python、Java、Goの3言語から抽出された1,539件の現実的なシナリオを用い、テストの新規作成、修復、更新という保守サイクル全体をファイル単位の粒度で評価する。 最新のGPT-5等を用いた検証の結果、テストの網羅性や変異スコアの向上幅は限定的であり、現実的な保守タスクにおいてLLMが真に実用的な水準に達するには依然として大きな技術的課題があることが判明した。
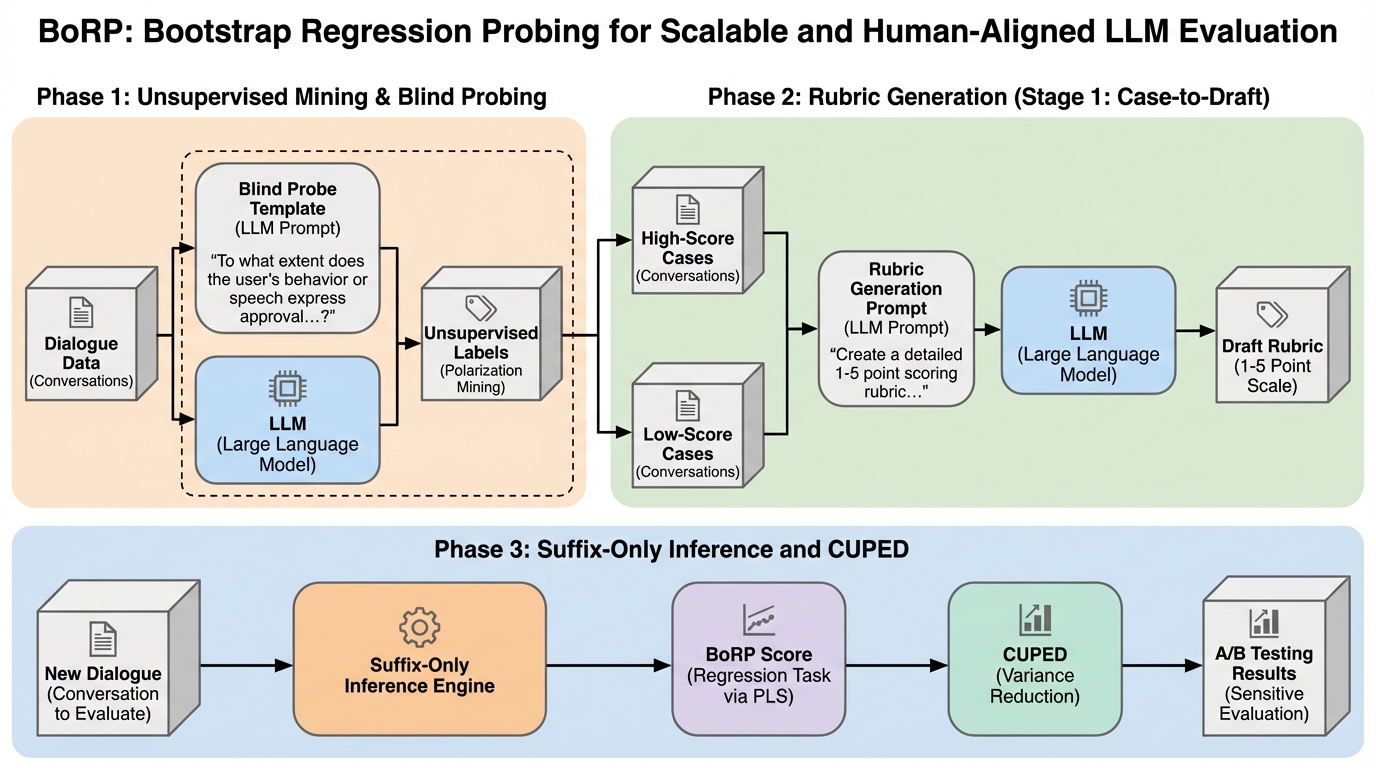
従来のLLMによる評価(LLM-as-a-Judge)が抱える「高コスト・低速・評価の偏り」という課題を解決するため、モデルの内部状態(潜在空間)を直接解析してユーザー満足度を1から5の数値で回帰予測する新手法「BoRP」が提案されました。