汎化税をより少なく支払う:LLMエージェントのための強化学習トレーニングのクロスドメイン汎化研究
LLMエージェントを強化学習で訓練する際、学習した特定の環境には適応する一方で未知の環境での性能が低下する「汎化税」が大きな課題となっている。本研究では、4つの異なるエージェント環境を用いた詳細な分析を通じて、「状態情報の豊かさ」と「計画の複雑さ」という二つの環境特性が、未知のドメインへの汎化性能と強く相関することを突き止めた。 この知見に基づき、タスクの本質を変えずに状態情報へ少量の無関係なノイズを加える「状態ランダム化」手法を提案し、これが知覚的な堅牢性を高めて未知の領域での性能維持に有効であることを実証した。さらに、学習中にステップバイステップの思考を有効にすることが汎化において不可欠な役割を果たす一方で、教師あり微調整(SFT)によるウォームアップが学習ドメインの知識を固定し、未カバーのドメインへの汎化を阻害するというトレードオフを特定した。 最終的に、デプロイ先が不明な汎用エージェントを構築するための具体的な環境選定指針として、情報の密度が高く、長期的な推論を要求する環境での学習を推奨し、モデリング手法として明示的な推論プロセスと軽量な状態ランダム化の組み合わせを提示した。
TL;DR(結論)
LLMエージェントを強化学習で訓練する際、学習した特定の環境には適応する一方で未知の環境での性能が低下する「汎化税」が大きな課題となっている。本研究では、4つの異なるエージェント環境を用いた詳細な分析を通じて、「状態情報の豊かさ」と「計画の複雑さ」という二つの環境特性が、未知のドメインへの汎化性能と強く相関することを突き止めた。 この知見に基づき、タスクの本質を変えずに状態情報へ少量の無関係なノイズを加える「状態ランダム化」手法を提案し、これが知覚的な堅牢性を高めて未知の領域での性能維持に有効であることを実証した。さらに、学習中にステップバイステップの思考を有効にすることが汎化において不可欠な役割を果たす一方で、教師あり微調整(SFT)によるウォームアップが学習ドメインの知識を固定し、未カバーのドメインへの汎化を阻害するというトレードオフを特定した。 最終的に、デプロイ先が不明な汎用エージェントを構築するための具体的な環境選定指針として、情報の密度が高く、長期的な推論を要求する環境での学習を推奨し、モデリング手法として明示的な推論プロセスと軽量な状態ランダム化の組み合わせを提示した。
なぜこの問題か
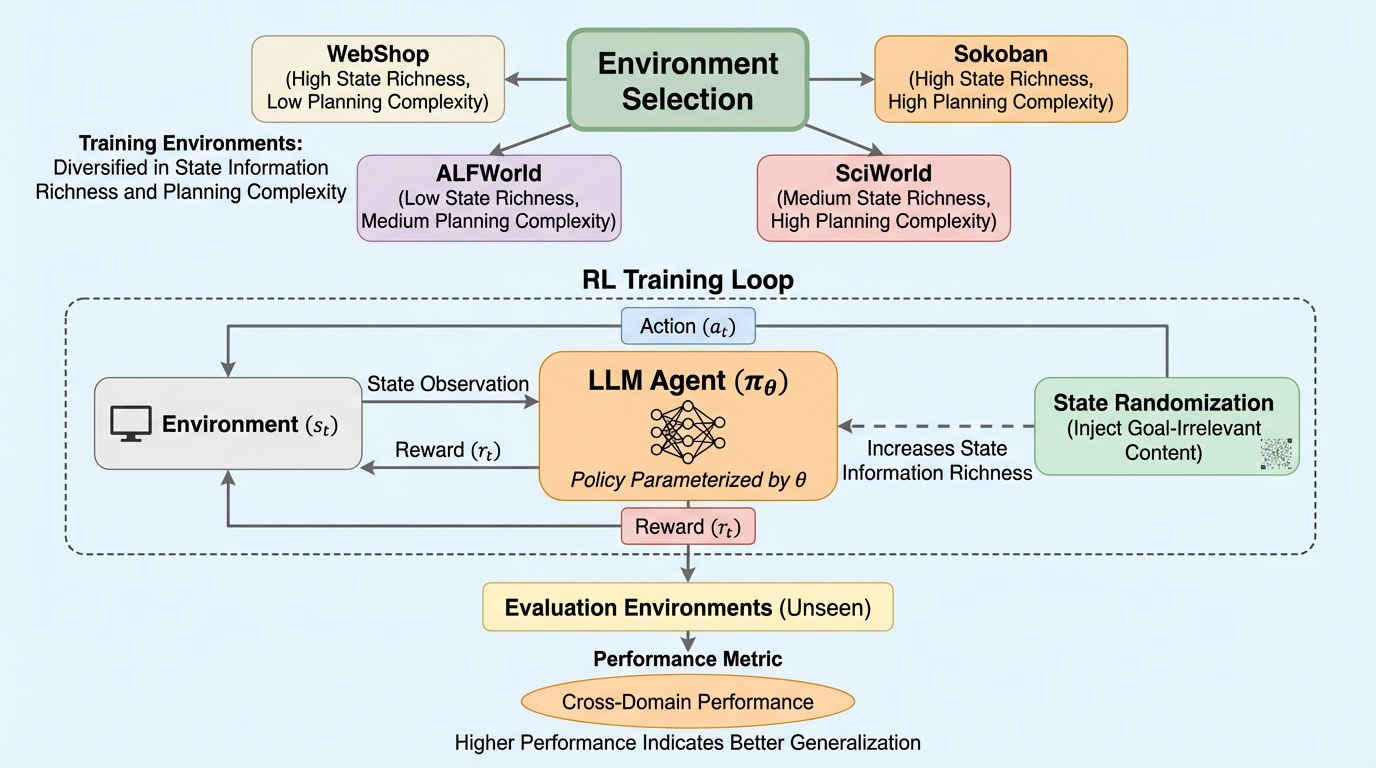
LLMエージェントのポストトレーニングは、通常、限られた数のシミュレーション環境やタスクセットを用いて行われる。しかし、実際にエージェントがデプロイされる環境は、学習時よりもはるかに広範で、かつ未知のドメインを含んでいる。近年の研究では、ベンチマークで高いスコアを記録したモデルであっても、現実世界の複雑なオフィス業務などの未知のタスクに直面すると、その性能が著しく低下することが報告されている。強化学習はエージェントの能力を向上させる強力なツールであるが、特定の環境に過剰に適合してしまうことで、未学習のドメインにおける汎用性が失われる現象、いわゆる「汎化税」が発生する。この問題の背景には、オンライン強化学習に必要なインタラクティブな環境を構築することの難しさがある。 報酬信号を備え、大規模なロールアウトをサポートするシミュレータをあらゆるドメインで構築することは、計算コストや技術的な制約から現実的ではない。また、実際の運用データから得られるフィードバックも、単一のロールアウトに限定されることが多く、強化学習の更新にそのまま活用するには限界がある。…
核心:何を提案したのか
本研究の核心は、強化学習環境のどのような特性が、未知のドメインへの汎化性能を決定づけるのかを体系的に解明した点にある。著者らは、4つの異なるエージェント環境(WebShop、Sokoban、ALFWorld、SciWorld)を用いた詳細な分析を通じて、汎化性能と強く相関する二つの主要な軸を特定した。第一の軸は「状態情報の豊かさ」であり、これはエージェントが状態から知覚し処理しなければならない情報の量を指す。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related