TAM-Eval: 自動単体テスト保守における大規模言語モデルの評価
ソフトウェア開発における単体テストの保守は、全予算の最大25%を占める重要な工程だが、従来の大規模言語モデル(LLM)の評価は単発の生成に偏り、継続的な保守能力の検証が不足していた。 本研究が提案する「TAM-Eval」は、Python、Java、Goの3言語から抽出された1,539件の現実的なシナリオを用い、テストの新規作成、修復、更新という保守サイクル全体をファイル単位の粒度で評価する。 最新のGPT-5等を用いた検証の結果、テストの網羅性や変異スコアの向上幅は限定的であり、現実的な保守タスクにおいてLLMが真に実用的な水準に達するには依然として大きな技術的課題があることが判明した。
TL;DR(結論)
ソフトウェア開発における単体テストの保守は、全予算の最大25%を占める重要な工程だが、従来の大規模言語モデル(LLM)の評価は単発の生成に偏り、継続的な保守能力の検証が不足していた。 本研究が提案する「TAM-Eval」は、Python、Java、Goの3言語から抽出された1,539件の現実的なシナリオを用い、テストの新規作成、修復、更新という保守サイクル全体をファイル単位の粒度で評価する。 最新のGPT-5等を用いた検証の結果、テストの網羅性や変異スコアの向上幅は限定的であり、現実的な保守タスクにおいてLLMが真に実用的な水準に達するには依然として大きな技術的課題があることが判明した。
なぜこの問題か
ソフトウェアの品質と信頼性を維持する上で、個々のコンポーネントを検証する単体テストは不可欠な要素である。業界の統計によれば、テスト工程はプロジェクト全体の予算の約4分の1を消費するとされており、開発者にとって大きな負担となっている。近年、大規模言語モデル(LLM)の急速な進歩により、コード生成やバグ修正といったソフトウェアエンジニアリングの各段階で自動化が進んでいる。しかし、単体テストの領域におけるLLMの活用は、依然として特定の関数に対する単発的なテスト生成や、期待される出力の予測といった限定的な範囲に留まっているのが現状である。 実際の開発現場では、プロダクションコードの進化に合わせてテストを継続的に生成し、壊れたテストを修復し、古い内容を最新の状態に更新するという「テスト保守」のプロセスが極めて重要である。テストの保守を怠れば、テストスイートはすぐに陳腐化し、継続的インテグレーションのパイプラインを破損させたり、重大な回帰バグを見逃したりする原因となる。それにもかかわらず、現実的なワークフローに即したテスト保守の自動化に関する研究は、これまで十分に探索されてこなかった。…
核心:何を提案したのか
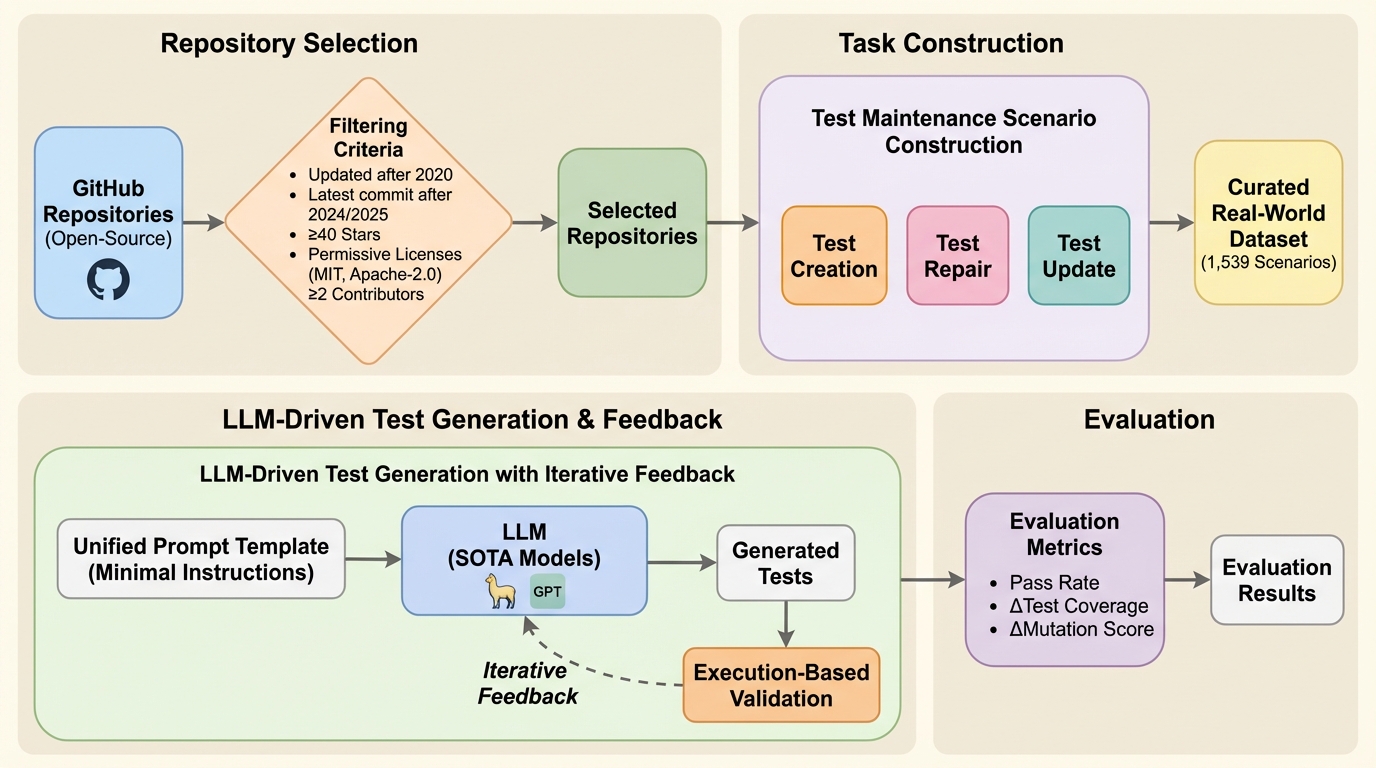
本研究は、大規模言語モデルによる単体テスト保守の能力を包括的に測定するためのベンチマークおよび評価フレームワークである「TAM-Eval(Test Automated Maintenance Evaluation)」を提案している。TAM-Evalの最大の特徴は、テストスイートの「新規作成(Creation)」、「修復(Repair)」、「更新(Update)」という、テスト保守の主要な3つのフェーズをすべて網羅している点にある。従来の評価手法が小さなコード断片や関数レベルのタスクに焦点を当てていたのに対し、本フレームワークはテストファイル全体の書き換えという、より実務に近い粒度で動作するように設計されている。 ベンチマークのデータセットは、Python、Java、Goという主要な3つのプログラミング言語から構成されており、合計1,539件の厳選されたシナリオが含まれている。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related