SAGE:実行フィードバックを用いたディープサーチのための操作可能なエージェント型データ生成
SAGEは、複数の文書を横断して推論を行うディープサーチエージェントの訓練を目的とした、難易度制御が可能な自律型データ生成パイプラインである。データ生成エージェントと検索エージェントが連携し、実際の実行結果をフィードバックとして活用することで、生成側の意図と実際の解法の乖離を解消し、高品質な質問応答ペアを自動構築する。
TL;DR(結論)
SAGEは、複数の文書を横断して推論を行うディープサーチエージェントの訓練を目的とした、難易度制御が可能な自律型データ生成パイプラインである。データ生成エージェントと検索エージェントが連携し、実際の実行結果をフィードバックとして活用することで、生成側の意図と実際の解法の乖離を解消し、高品質な質問応答ペアを自動構築する。 検証の結果、SAGEで生成されたデータを用いた訓練により、既存のベンチマークにおいて最大23%の性能向上を達成し、未知の検索環境やGoogle検索への高い適応能力も実証された。これにより、人手による高コストな注釈作業を介さずに、複雑な推論を必要とする大規模な学習用データセットの構築が可能となった。 本手法は、検索ステップ数を難易度の指標として明示的に制御できるため、エージェントの能力段階に応じたカリキュラム学習などへの応用も期待される。実行トレースに基づく反復的な改善プロセスは、単なるフィルタリングを超えたデータの洗練を実現し、より多様で高度な推論戦略をエージェントに学習させるための強力な基盤を提供する。
なぜこの問題か
大規模言語モデルをエージェントとして活用し、外部の知識源と相互作用しながら複雑な課題を解決する研究が世界的に加速している。特に、膨大な文書群から必要な情報を探し出し、それらを論理的に組み合わせて回答を導き出すディープサーチエージェントは、情報探索の効率を劇的に高める可能性を秘めている。しかし、こうした高度な能力を持つエージェントを構築・評価するためには、複雑な推論ステップを必要とする高品質な質問応答データの存在が前提となる。現在、この分野における最大の障壁は、そのようなデータの入手が極めて困難であるという点にある。ディープサーチのためのデータ作成には、長く複雑な探索の軌跡を正確に記録する必要があり、人間が注釈を付けるには膨大な時間と高い認知負荷が伴うため、大規模なデータセットを構築することは現実的ではない。 既存の検索拡張生成(RAG)向けデータセットの多くは、1回の検索で解決できる単純な質問に偏っており、多段階推論を謳う既存のベンチマークであっても、実際には4ステップ以下の検索で完結してしまうものがほとんどである。…
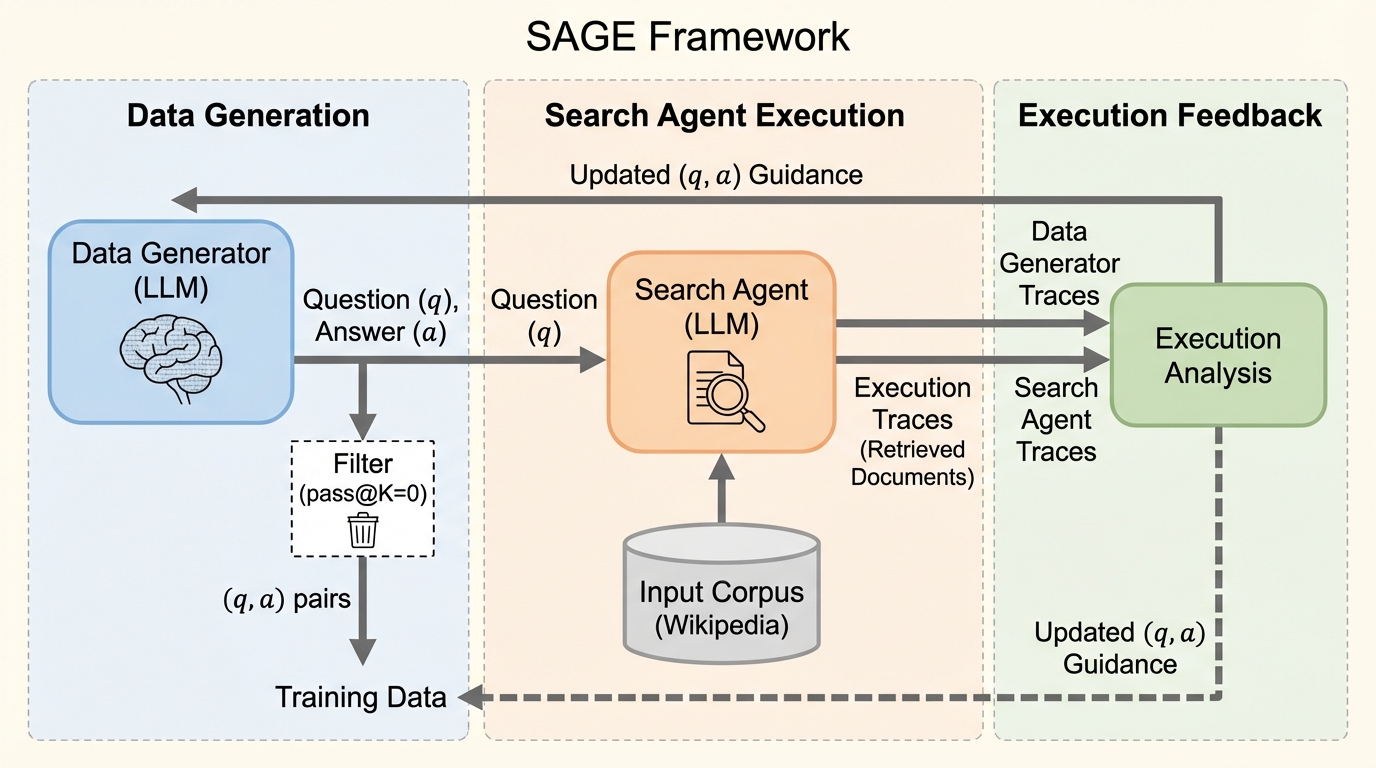
核心:何を提案したのか
本研究では、実行フィードバックを活用することで、難易度を自在に操作可能なエージェント型データ生成パイプラインであるSAGEを提案した。SAGEの核心的なアイデアは、単一のモデルで完結させるのではなく、役割の異なる2つのエージェントを組み合わせたデュアルエージェント・フレームワークを採用した点にある。具体的には、質問と回答のペアを考案するデータ生成エージェントと、その質問を実際に解こうと試みる検索エージェントが相互に作用する仕組みを構築した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related