クロスモーダル・ファインチューニングの再考:特徴アライメントとターゲット適合の相互作用の最適化
事前学習済みモデルを未知のデータモダリティに適応させるクロスモーダル・ファインチューニングにおいて、特徴量のアライメントとターゲットへの適合の間の理論的な相互作用を解明し、汎化誤差の境界を定義する新しい原理的フレームワーク「RECRAFT」を提案した。
TL;DR(結論)
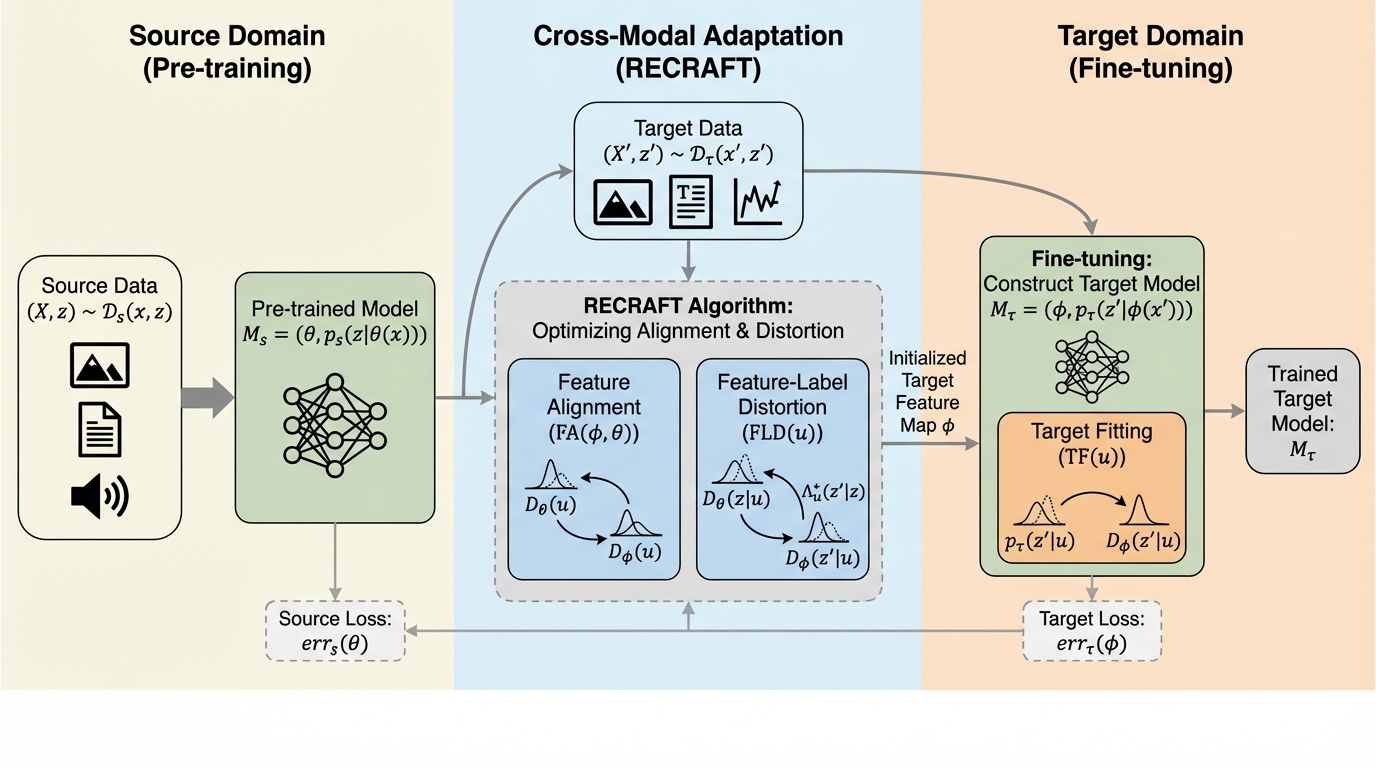
事前学習済みモデルを未知のデータモダリティに適応させるクロスモーダル・ファインチューニングにおいて、特徴量のアライメントとターゲットへの適合の間の理論的な相互作用を解明し、汎化誤差の境界を定義する新しい原理的フレームワーク「RECRAFT」を提案した。 新概念である「特徴ラベル歪み(Feature-Label Distortion)」を導入することで、ソースとターゲットの間の転送可能性を定量化し、特徴量のアライメントのみを追求する従来手法で発生していた負の転送や過学習を抑制し、セマンティックな構造の不一致を解消する理論的根拠を確立した。 特徴マップの学習と予測器の最適化を分離した二段階のアルゴリズムを設計し、NAS-Bench-360やPDEBenchといった広範なベンチマークにおいて、既存の最先端手法であるORCAやMoNAを上回る高い汎化性能と、多様なモダリティに対する安定した適応能力を実証することに成功した。
なぜこの問題か
現代のAI応用において、広範なデータで事前学習された基盤モデル(Foundation Models)の知識を、学習時には存在しなかった新しいデータモダリティへと転送するニーズが急速に高まっている。例えば、ゲノム解析における遺伝子発現プロファイルを組織画像データの表現に活用したり、画像や言語、音声で学習されたモデルをタンパク質構造や宇宙線信号、人間のジェスチャーといった未知の領域へ適応させたりする試みが進んでいる。しかし、事前学習済みモデルは元の表現空間内で最も予測的なパターンを抽出するように最適化されているため、新しいモダリティを効果的に統合するには、そのデータを既存の表現空間の適切な領域へと正確にマッピングする必要がある。このプロセスにおいて、ソースとターゲットのデータ分布が統計的に異なる構造を持つことが根本的な課題となる。たとえ特徴量の次元数が同じであっても、共分散構造や共変量間の高次相互作用、モードの幾何学的形状が異なる場合、事前学習済みモデルがターゲットタスクにおいて無関係なパターンを活性化させてしまうリスクがある。…
核心:何を提案したのか
本研究では、クロスモーダル・ファインチューニングにおける特徴アライメントとターゲット適合の相互作用を最適化するための原理的なフレームワーク「RECRAFT(REthinking CRoss-ModAl Fine-Tuning)」を提案した。このフレームワークの核心は、ターゲット誤差に対する証明可能な汎化境界を確立し、それを「特徴ラベル歪み(Feature-Label Distortion)」という新しい概念を通じて定式化した点にある。特徴ラベル歪みとは、与えられた特徴表現の下で、ソースタスクとターゲットタスクの間の条件付き予測分布を変換する際の確率的輸送マップの複雑さを定量化したものである。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related