BoRP:スケーラブルかつ人間と整合したLLM評価のためのブートストラップ回帰プロービング
従来のLLMによる評価(LLM-as-a-Judge)が抱える「高コスト・低速・評価の偏り」という課題を解決するため、モデルの内部状態(潜在空間)を直接解析してユーザー満足度を1から5の数値で回帰予測する新手法「BoRP」が提案されました。
TL;DR(結論)
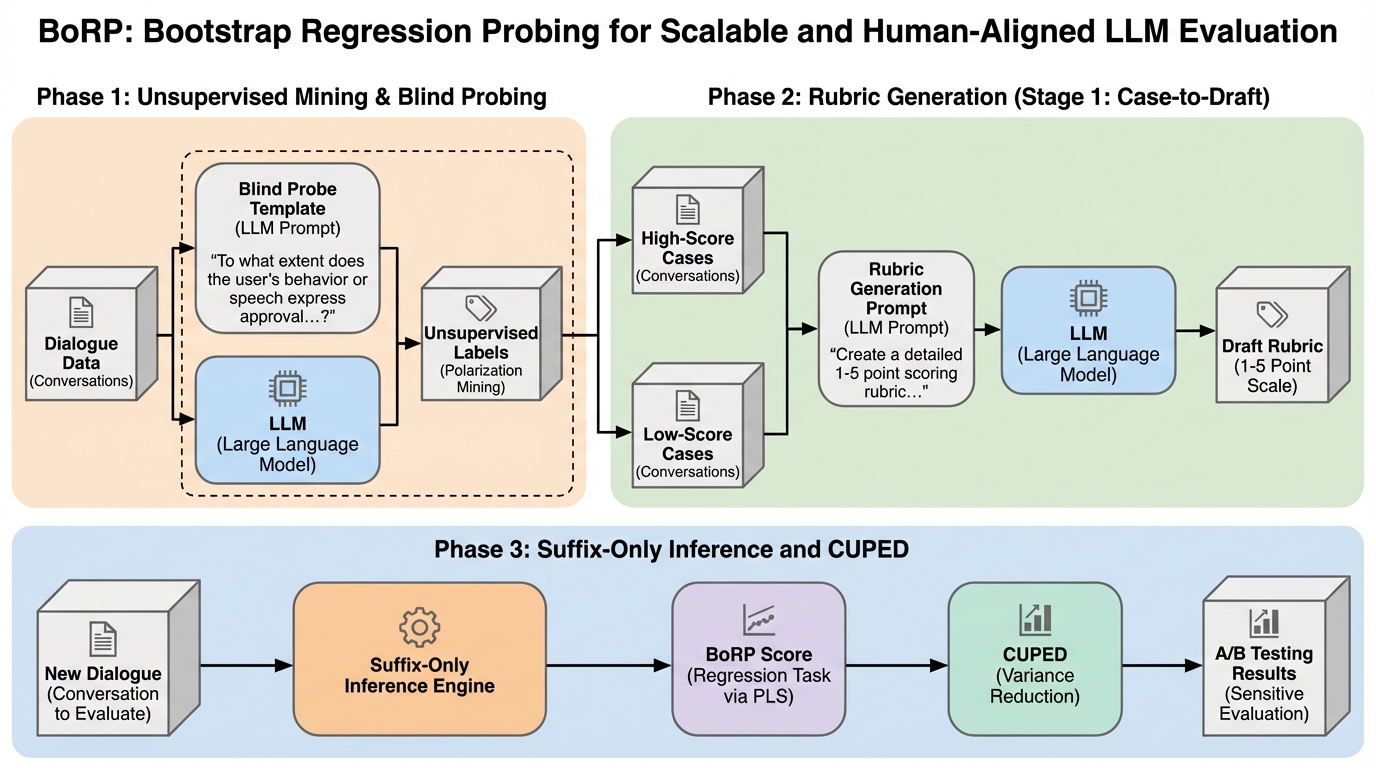
従来のLLMによる評価(LLM-as-a-Judge)が抱える「高コスト・低速・評価の偏り」という課題を解決するため、モデルの内部状態(潜在空間)を直接解析してユーザー満足度を1から5の数値で回帰予測する新手法「BoRP」が提案されました。 独自の「偏極指数(PI)」を用いて、ラベルのないデータから満足度が極端なサンプルを自動抽出し、教師モデルを通じて評価基準(ルーブリック)を自動生成するブートストラップ機構を備えており、専門家による膨大な作業なしで高精度な評価システムを構築可能です。 実証実験では、Qwen3-14Bを用いたBoRPが、より巨大なQwen3-Maxの生成評価を上回る人間との整合性を示し、推論コストをGPT-4比で169分の1以下に抑えつつ、単一GPUで1日あたり140万セッションを処理できる圧倒的な効率性を実現しました。
なぜこの問題か
会話型AIの開発において、ユーザーの満足度を正確に測定することは反復的な改善のために不可欠ですが、自由形式の対話では従来の指標が機能しにくいという深刻な課題があります。セッションの長さや発話回数といった従来のヒューリスティックな指標は曖昧であり、例えば対話が長いことは、ユーザーが没頭しているのか、あるいは回答が分かりにくくて混乱しているのかを区別できません。一方で、継続率のような事後的な指標は結果が出るまでに時間がかかる「遅行指標」であり、迅速な戦略の改善に必要な感度を持ち合わせていません。この「指標のギャップ」を埋めるために、現在は主に4つの手法が検討されていますが、それぞれが産業展開における「高い壁」に直面しています。 第一に、人間による手動評価は黄金律(ゴールドスタンダード)ですが、スケーラビリティの壁に突き当たります。人間によるラベル付けは稀少でコストが高いため、統計的に有意なA/Bテストを行うには不十分なサンプル数しか確保できず、小さな改善を検出するのに非現実的な実験期間を要します。第二に、LLMを評価者として利用する生成ベースの評価は、精度とコストのトレードオフに苦しんでいます。…
核心:何を提案したのか
本研究では、評価をテキストの「生成」としてではなく、モデル内部の潜在空間における「高精度な回帰タスク」として再定義するエンドツーエンドのフレームワーク「BoRP(Bootstrapped Regression Probing)」を提案しています。BoRPは、LLMの隠れ状態が持つ幾何学的な特性を直接利用することで、生成ベースの手法が抱える限界を打破することを目指しています。このフレームワークの核心は、モデルの内部表現から満足度に関連する特定の「部分空間」を特定し、それを1から5の連続的なスコアにマッピングする幾何学的なアプローチにあります。 BoRPの主な貢献は4点に集約されます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related