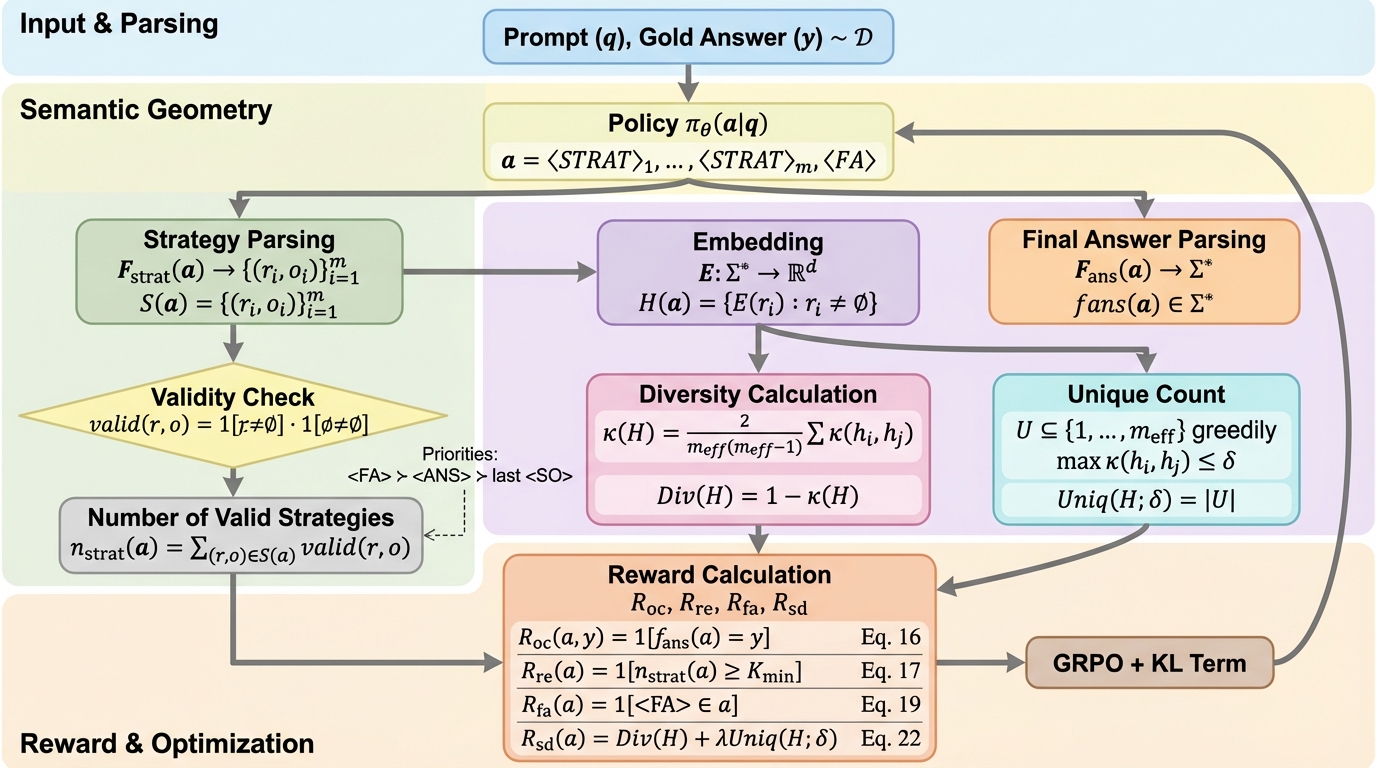
SD-E$^2$:トークン予算制約下での推論のための意味的探索
小規模言語モデル(SLM)が限られたトークン予算内で高度な推論を行うため、生成される推論プロセスの「意味的な多様性」を報酬として最適化する新しい強化学習フレームワーク「SD-E$^2$」が提案されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
小規模言語モデル(SLM)が限られたトークン予算内で高度な推論を行うため、生成される推論プロセスの「意味的な多様性」を報酬として最適化する新しい強化学習フレームワーク「SD-E$^2$」が提案されました。
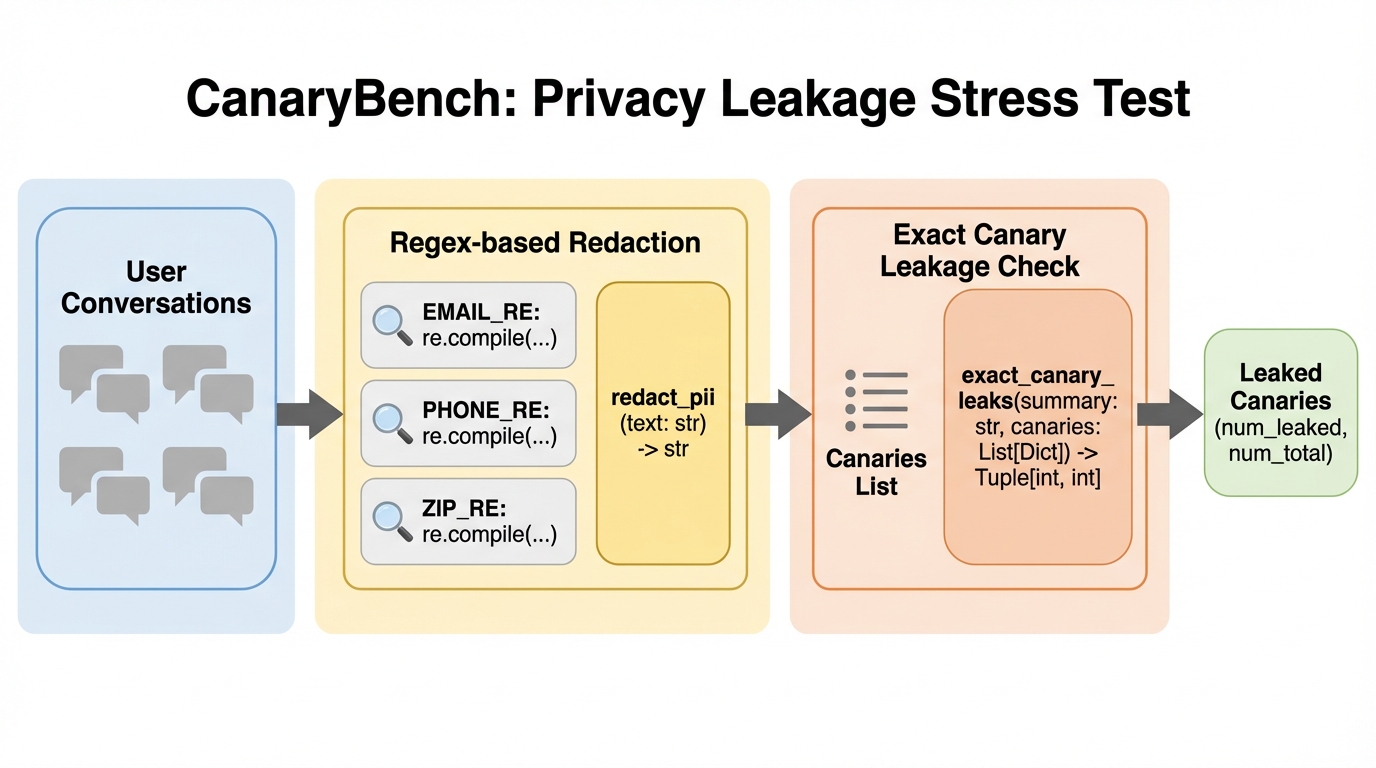
CanaryBenchは、大規模言語モデル(LLM)の会話データをトピックごとにクラスタ化して要約する際、個人の特定につながる情報(PII)がどの程度漏洩するかを測定する新しいベンチマークである。実験の結果、元の会話を直接引用する「抽出型」の要約手法を用いると、特定の識別文字列(カナリア)を含むクラスタの96.
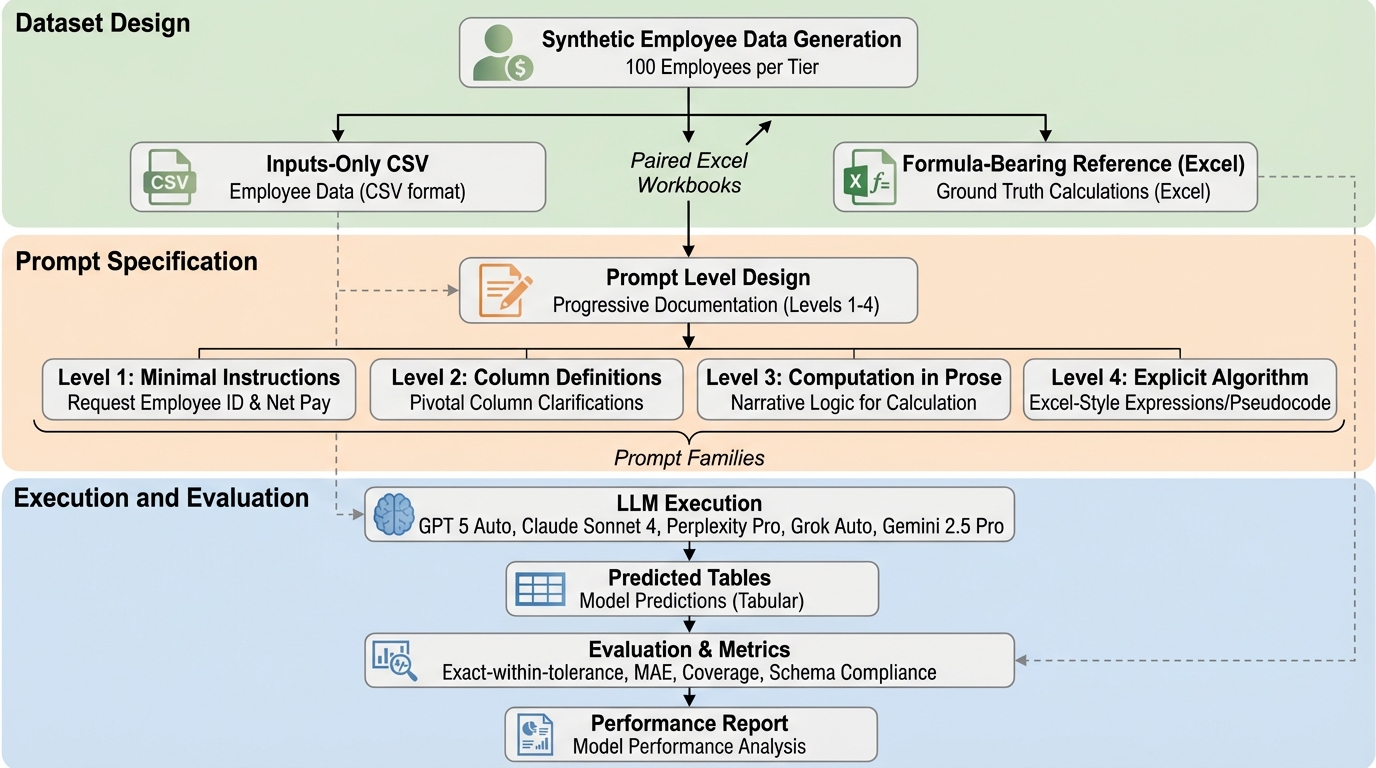
給与計算は、わずか数セントの誤差が法令遵守に影響を与えるため、大規模言語モデル(LLM)にとって極めて高い精度と監査可能性が求められる過酷なテストケースとなります。現在のLLMは文章作成や分析において優れた能力を示していますが、厳密な数値計算や、複雑なビジネスルールを正しい順序で適用する能力については依然として不確実性が残っており、本研究ではその限界と可能性を検証しました。 研究では、GPT 5 Auto、Claude Sonnet 4、Perplexity Pro、Grok Auto、Gemini 2.5 Proといった主要なモデルを対象に、5段階の難易度を持つデータセットと4段階のプロンプト手法を用いて、給与計算スキーマの意味理解と計算精度を評価しました。検証の結果、単純な計算では多くのモデルが100%の精度を達成したものの、複雑なシナリオではプロンプトの詳細度が精度に大きく影響し、特に明示的な数式を提供したレベル4においてPerplexity Proが最も高い信頼性を示しました。 実験データによれば、単純な乗算を超えた複雑なタスクにおいて、LLMが単独で正確な結果を出すには限界があり、明示的なアルゴリズムの提示や外部ツールの活用が不可欠であることが明らかになりました。特に、多州にまたがる税金の按分や為替変換を含む高度なシナリオでは、モデル間で性能の差が顕著に現れており、実務への導入には慎重なプロンプト設計と検証プロセスの構築が求められるという結論に至っています。
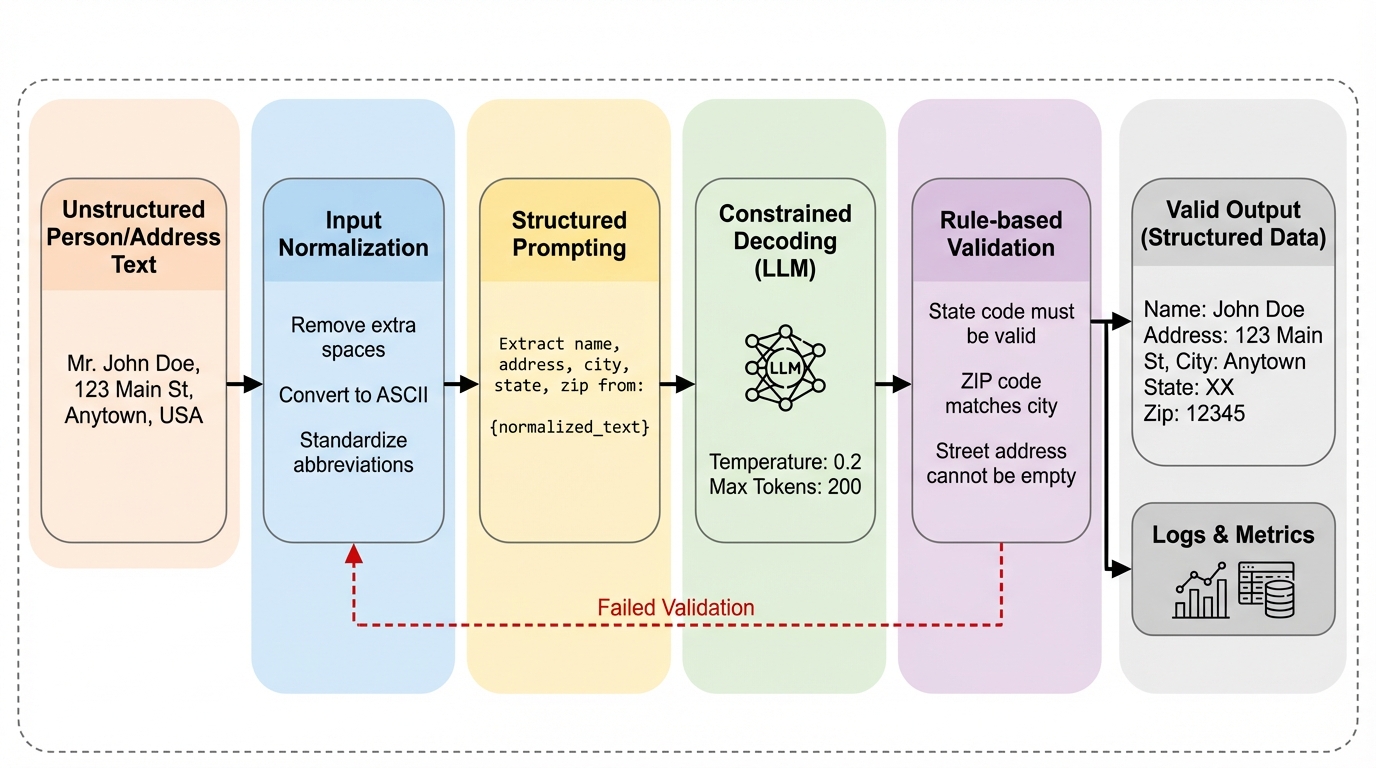
非構造化された氏名や住所のテキストを、大規模言語モデルと決定論的な検証レイヤーを組み合わせることで、17項目の詳細なスキーマに変換する新しいフレームワークを提案しました。 追加のファインチューニングを一切行わず、入力の正規化、構造化されたプロンプト、制約付きデコード、そして厳格なルールベースの検証を統合することで、99.8%という極めて高い解析精度を達成しています。 このシステムは、多言語対応や誤字脱字への耐性を持ちながら、郵便番号と州の整合性チェックなどの実世界の制約を強制することで、大規模な情報システムにおける信頼性と再現性の高いデータ抽出を低コストで実現します。
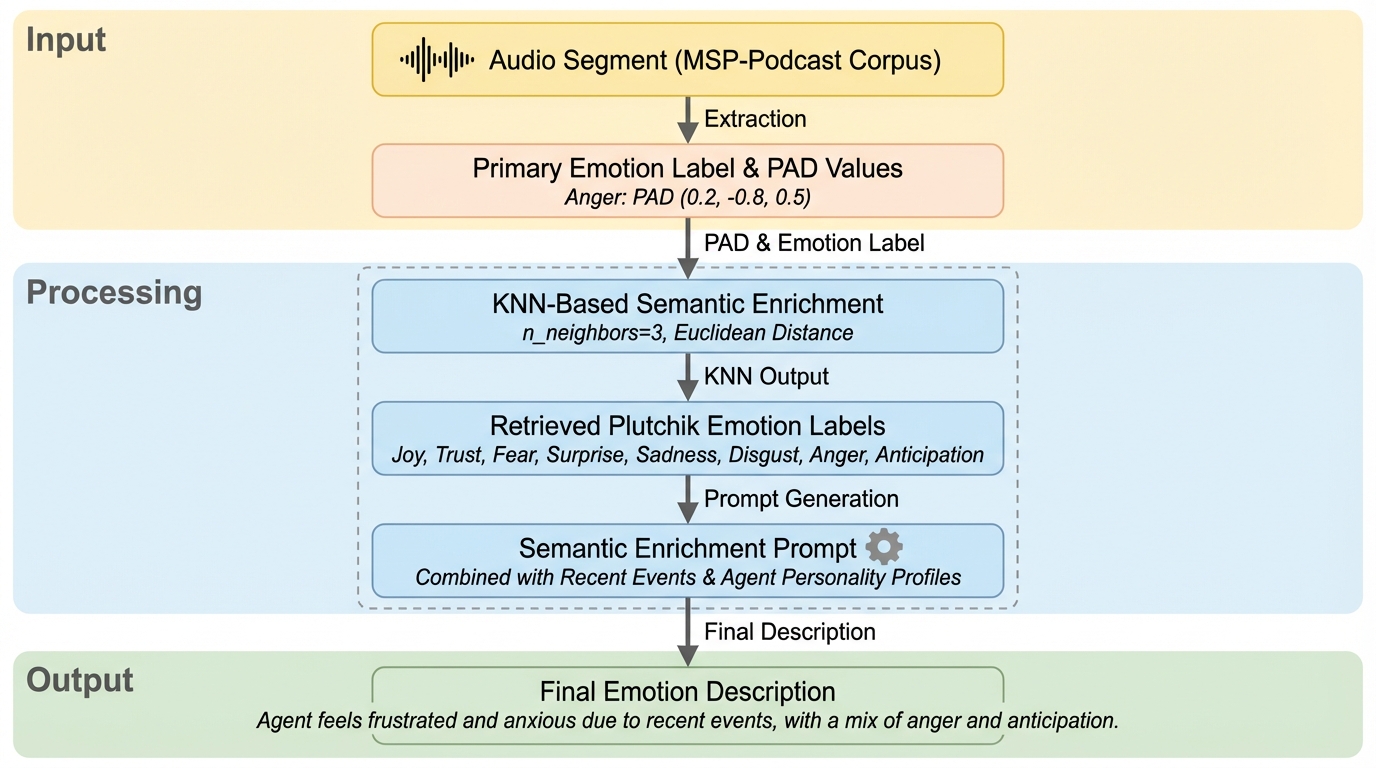
従来の大規模言語モデル(LLM)エージェントは、感情を一時的な信号としてのみ処理するため、長期的な対話において感情の一貫性が失われる「感情的健忘(emotional amnesia)」という深刻な課題を抱えていました。
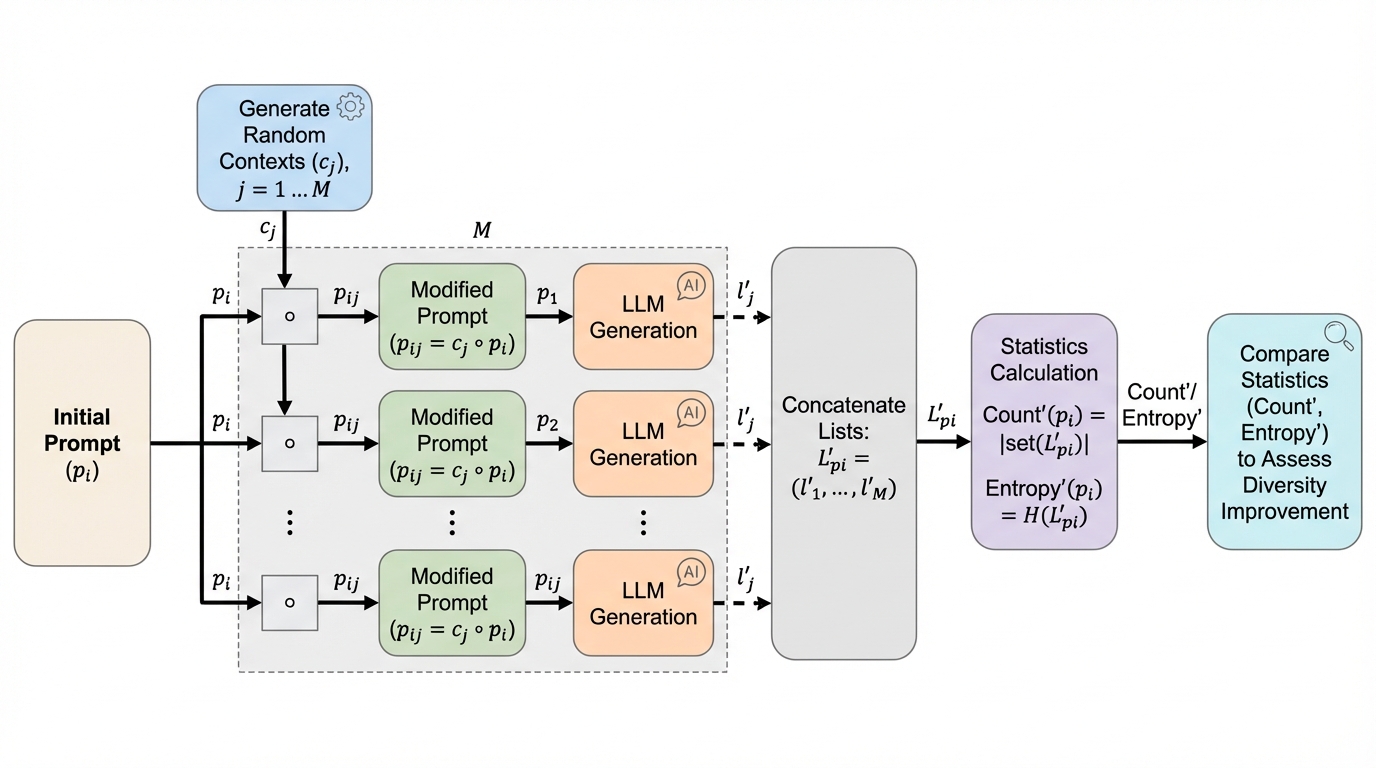
大規模言語モデル(LLM)が特定の一般的な回答ばかりを生成してしまう「ロングテール問題(モード崩壊)」に対し、プロンプトの先頭に無関係なランダムな単語や文章を付加するだけで、出力の多様性が統計的に有意に向上することを明らかにしました。
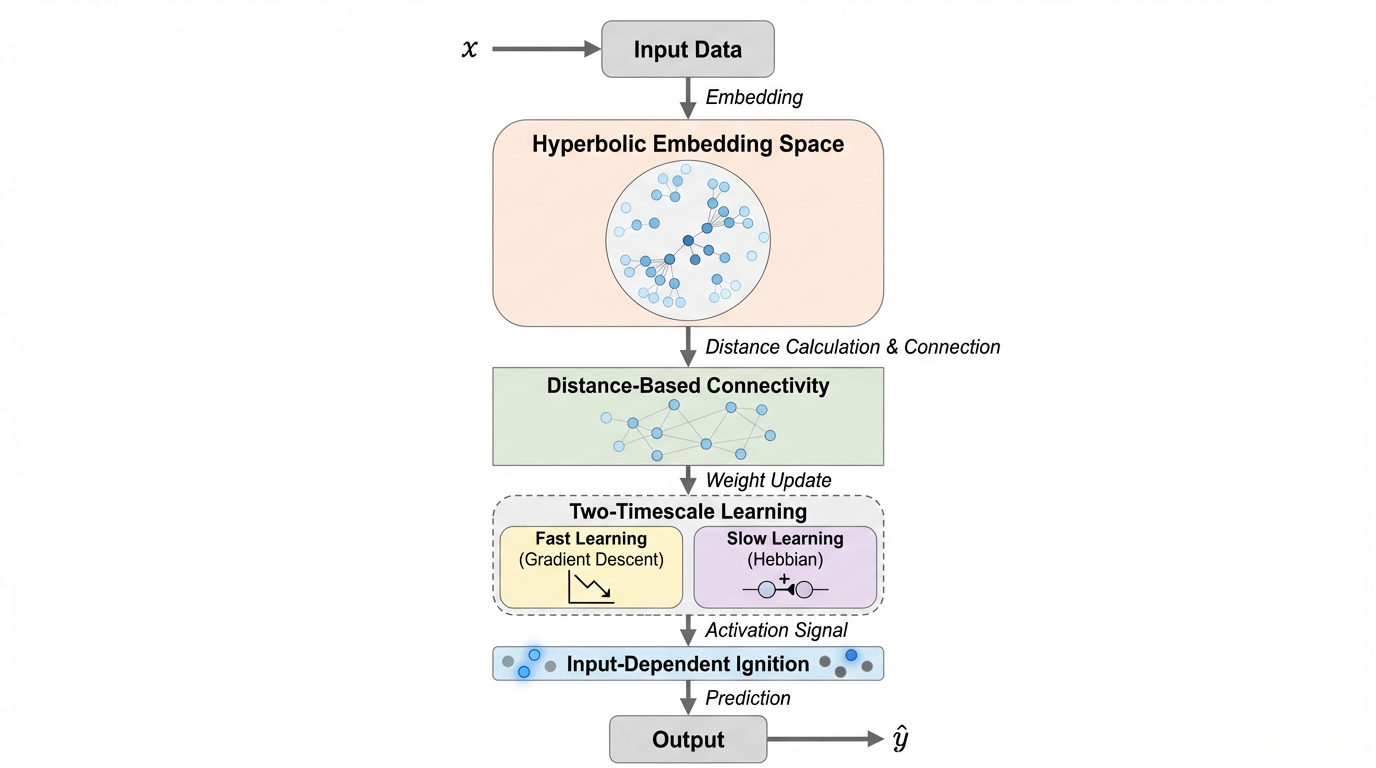
共鳴型スパース幾何ネットワーク(RSGN)は、脳の自己組織化されたスパースな接続性と動的な経路選択を模倣し、計算ノードを双曲幾何学空間(ポアンカレ球)に配置することで、従来のTransformerが抱える計算量の増大問題を根本から解決する新しいニューラルアーキテクチャである。
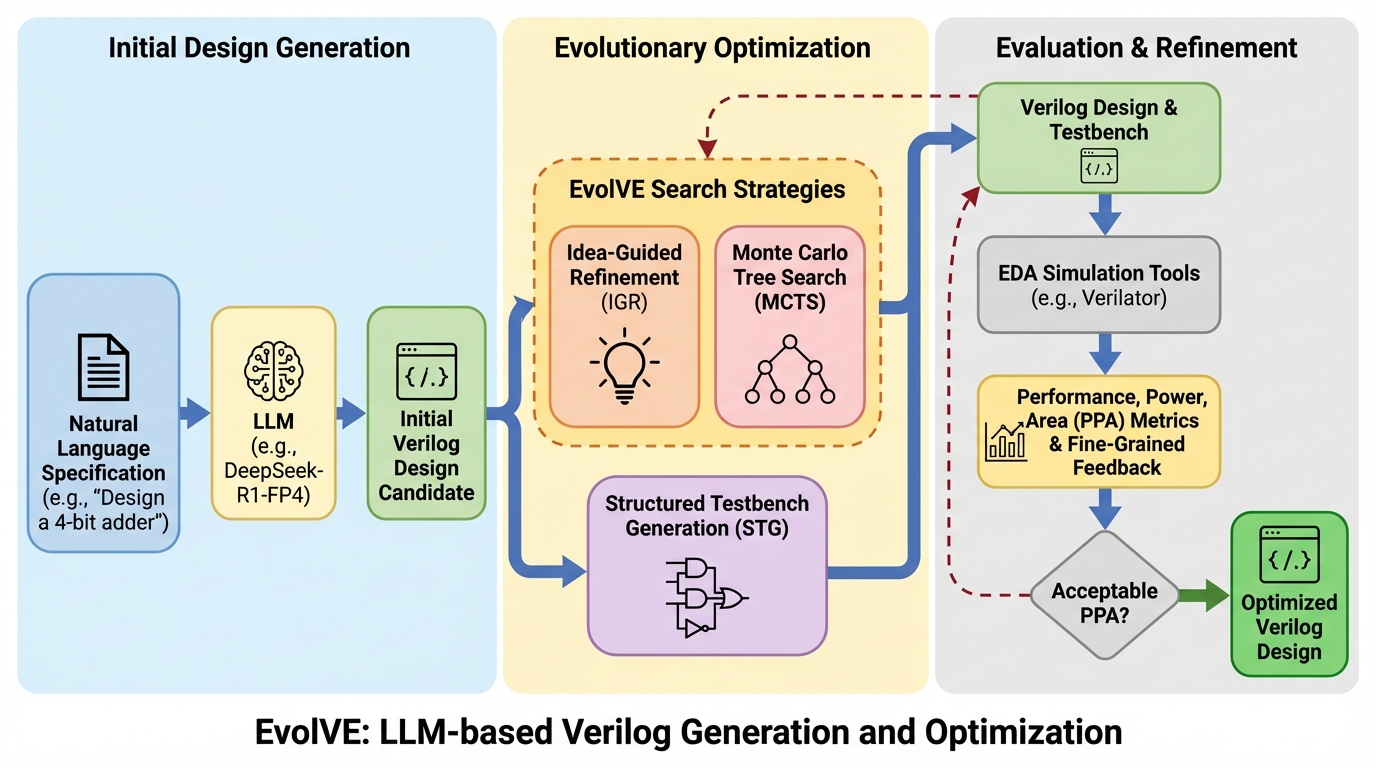
EvolVEは、大規模言語モデル(LLM)を活用してハードウェア記述言語であるVerilogのコード生成と最適化を自動化する、進化的探索アルゴリズムに基づいた革新的なフレームワークである。 機能的正当性を最大化するモンテカルロ木探索(MCTS)と、設計の最適化に特化したアイデア主導型洗練(IGR)という二つの異なる戦略を使い分け、さらに検証プロセスを高速化する構造化テストベンチ生成(STG)を導入している。 評価の結果、既存のベンチマークで世界最高水準の正解率を達成しただけでなく、産業規模の課題を含むIC-RTLベンチマークにおいて、人間による設計を大幅に上回る電力・性能・面積(PPA)の削減に成功した。
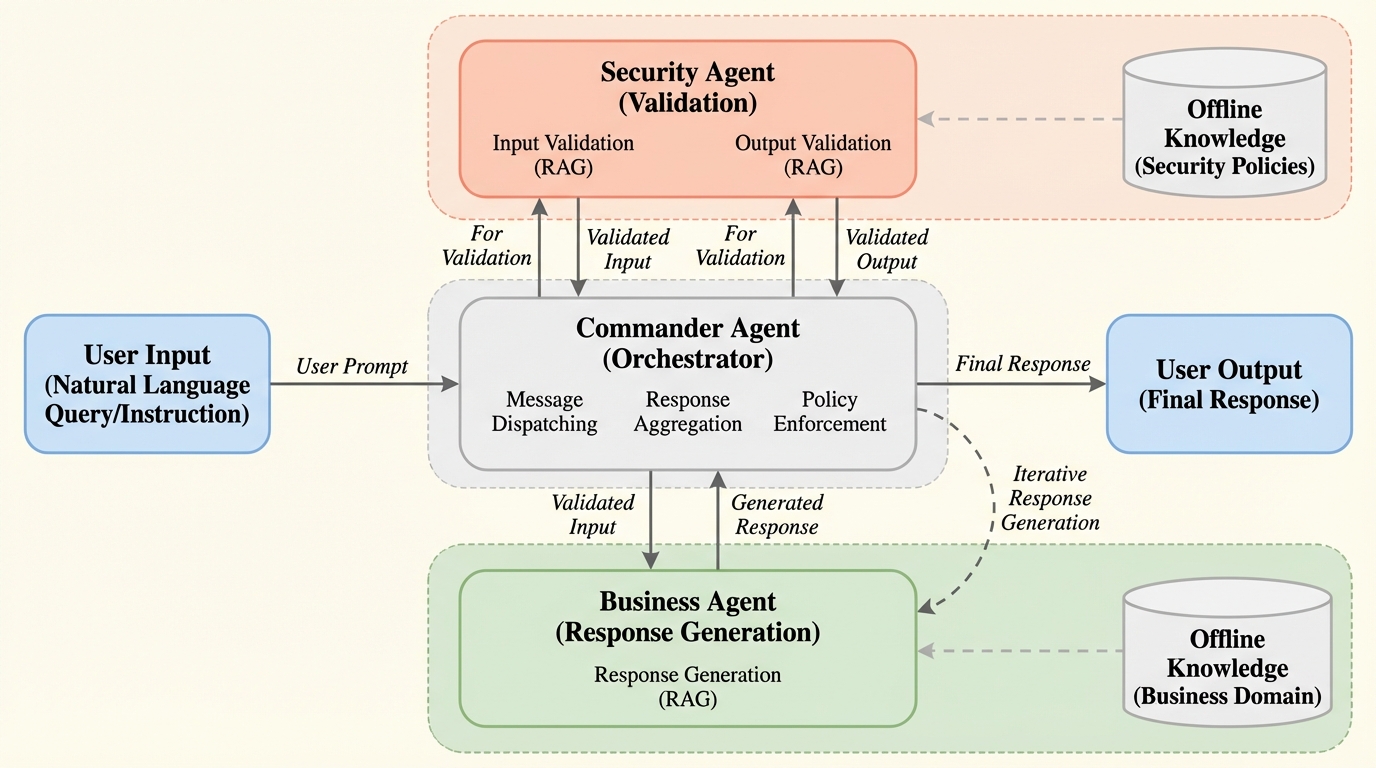
大規模言語モデル(LLM)の普及に伴い、OWASPが定義する「LLMのためのTop 10」のようなセキュリティ脆弱性への対策が急務となっており、データの完全性、機密性、およびサービスの可用性を保護するための新しい防御策が求められています。
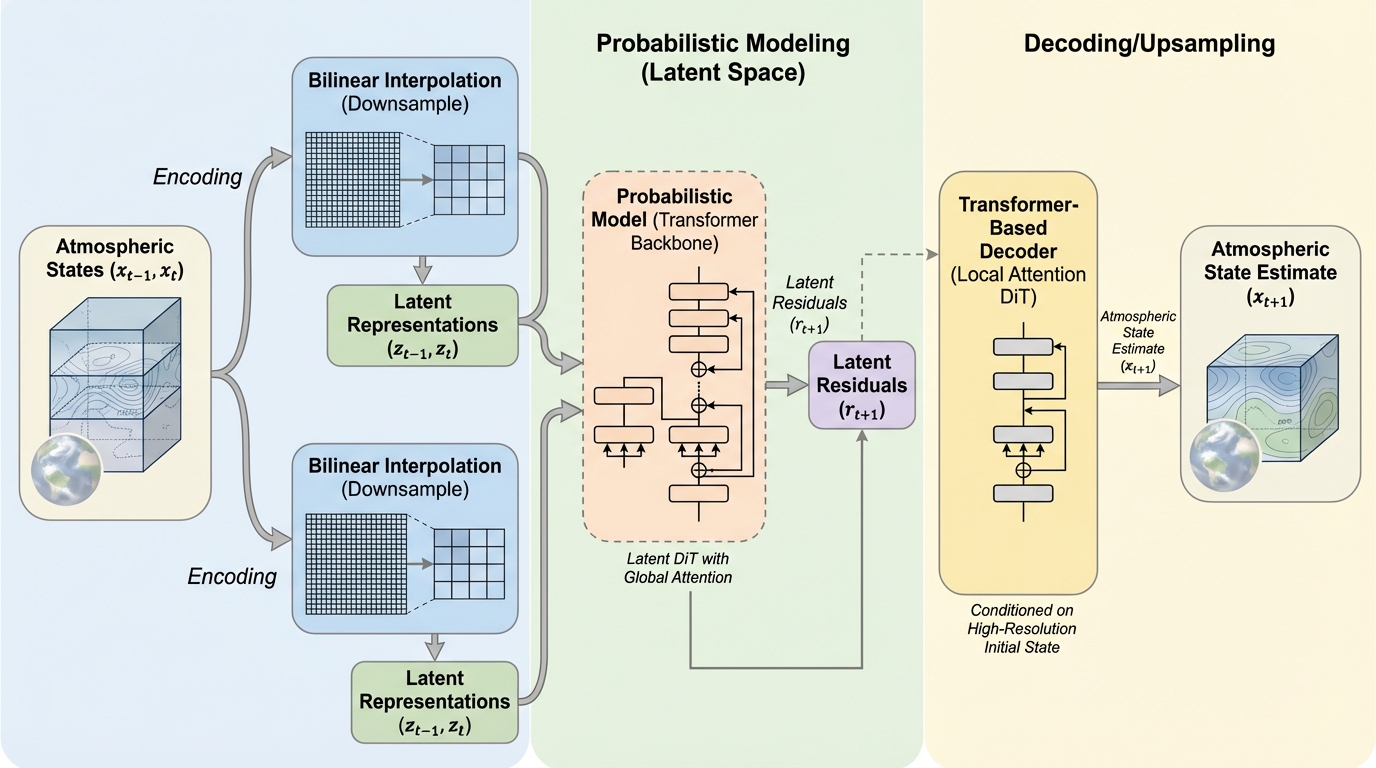
NVIDIAの研究チームは、複雑な専用アーキテクチャや特殊な学習手法を排除し、標準的なTransformerと潜在空間を活用した新しい気象予測フレームワーク「ATLAS」を開発した。 この手法は、双線形補間による単純なダウンサンプリングと潜在空間での残差予測を組み合わせることで、拡散モデルや確率的補間などの異なる確率的手法において一貫して高い精度を実現している。 ERA5データを用いた検証では、従来の数値予報システム(IFS)を大幅に上回り、既存の最先端深層学習モデルであるGenCastに対しても、多くの変数で統計的に有意な精度向上を達成した。