ReFuGe:LLMエージェントを用いたリレーショナルデータベース上の予測タスクのための特徴量生成
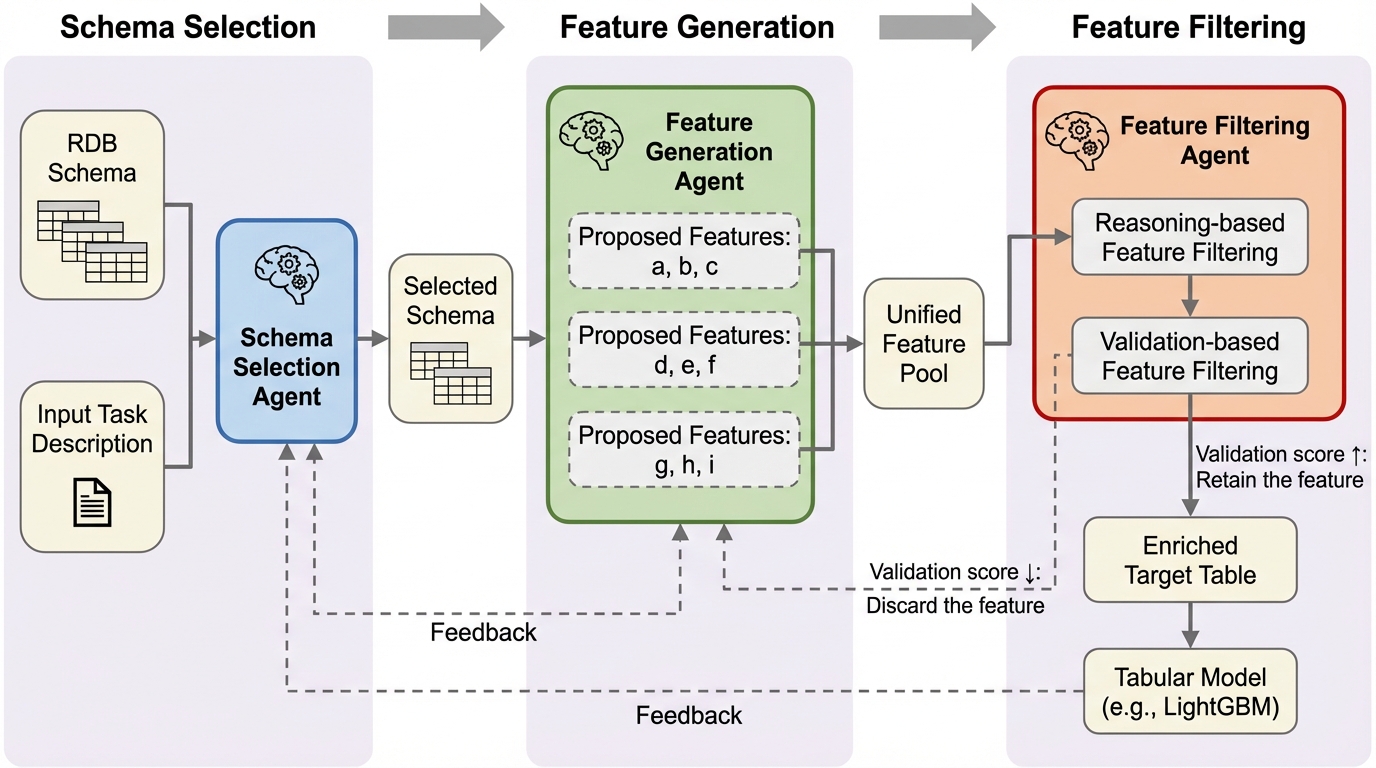
リレーショナルデータベースの複雑な構造から予測に有効な特徴量を自動生成するため、役割を専門化させた3つのLLMエージェント(スキーマ選択、特徴量生成、フィルタリング)を連携させ、反復的なフィードバックループを通じて探索空間を最適化する新しいフレームワーク「ReFuGe」が提案されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
リレーショナルデータベースの複雑な構造から予測に有効な特徴量を自動生成するため、役割を専門化させた3つのLLMエージェント(スキーマ選択、特徴量生成、フィルタリング)を連携させ、反復的なフィードバックループを通じて探索空間を最適化する新しいフレームワーク「ReFuGe」が提案されました。
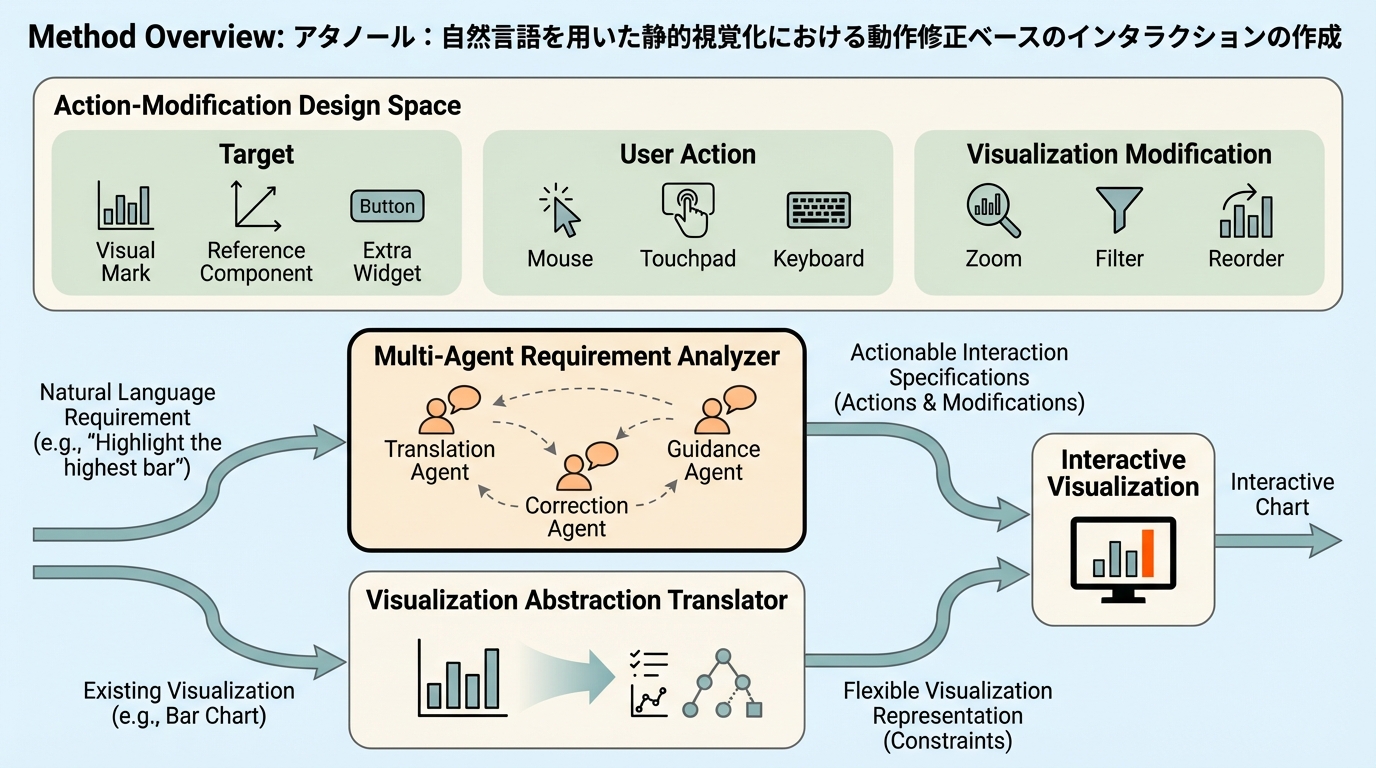
既存の静的なデータ可視化グラフに対し、自然言語による指示のみで動的なインタラクション機能を付与する新しいアプローチ「アタノール(Athanor)」が提案されました。この手法は、元のグラフを作成した際のソースコードや背後にある生データにアクセスできない状況でも、マルチモーダル大規模言語モデル(MLLM)を活用することで、静止画の状態から操作可能な形式へと変換することを可能にします。 システムの中核は、ユーザーの動作と視覚的な修正をマッピングする「動作修正デザイン空間」、自然言語の意図を正確な操作仕様に変換する「マルチエージェント要件分析器」、そして実装に依存しない形式でグラフを再構成する「可視化抽象化変換器」の3つの革新的な要素で構成されています。これにより、プログラミングの専門知識を持たない一般的なユーザーであっても、既存のグラフに対してホバー効果やフィルタリング、ズームといった高度な機能を容易に追加できるようになります。 評価実験として実施されたケーススタディと11名の参加者を対象とした詳細なユーザーインタビューの結果、アタノールは多様なユーザー要件をカバーし、視覚的な一貫性を保ちながら静的なグラフを効果的に動的なものへと変換できることが確認されました。特にSVG形式で出力された棒グラフ、折れ線グラフ、散布図、面グラフなどの主要なチャートタイプにおいて、その有用性と効率性が実証されており、データ分析の深化を支援する強力なツールとしての可能性を示しています。
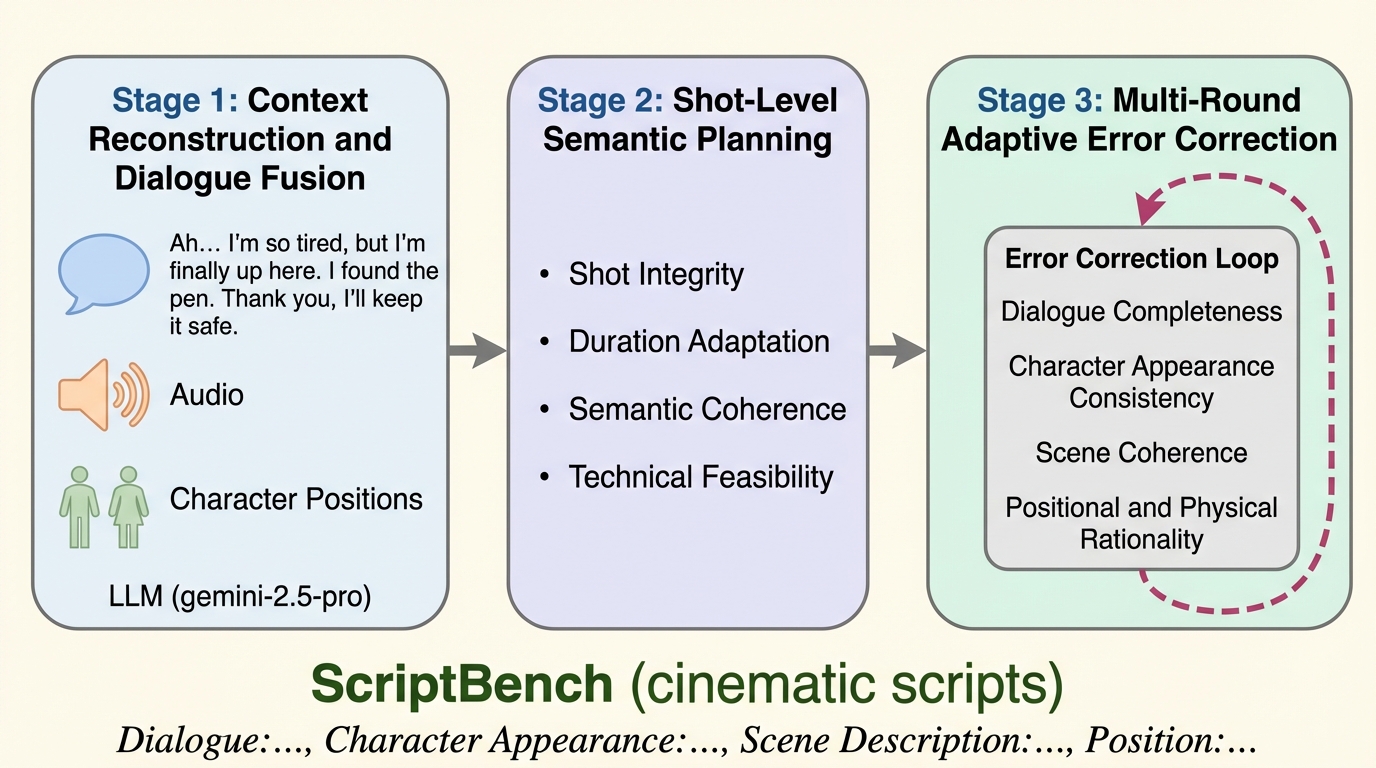
従来の動画生成AIは、対話のような抽象的な概念から一貫した物語を持つ長尺映像を作る際、創作意図と映像表現の間に「意味のギャップ」が生じる課題がありました。本研究では、アルフレッド・ヒッチコックの「映画には脚本が最も重要である」という哲学に基づき、断片的な対話文から詳細な撮影指示を含む脚本を自動生成し、それを基に一貫性のある映像を構築する新しいエージェントフレームワークを提案しています。 専門的な脚本家、監督、批評家の役割を担う3つのエージェントと、大規模データセットScriptBench、そして強化学習(GRPO)を組み合わせることで、既存の動画生成モデルの限界を超えた劇的な緊張感と視覚的一貫性を実現することに成功しました。これにより、キャラクターの同一性や物語の文脈を維持したまま、プロフェッショナルな品質の映画風動画を自動で制作することが可能になります。 本フレームワークは、ScripterAgentによる精密な脚本作成、DirectorAgentによるシーン間の連続性確保、CriticAgentによる多角的な評価という一連のプロセスを通じて、最新の動画生成モデル(Sora2-ProやVeo3.1など)の性能を最大限に引き出します。実験では、脚本への忠実度や映像の連続性を示す新指標VSAにおいて大幅な向上を記録し、自動映画製作における新たなパラダイムを確立しました。
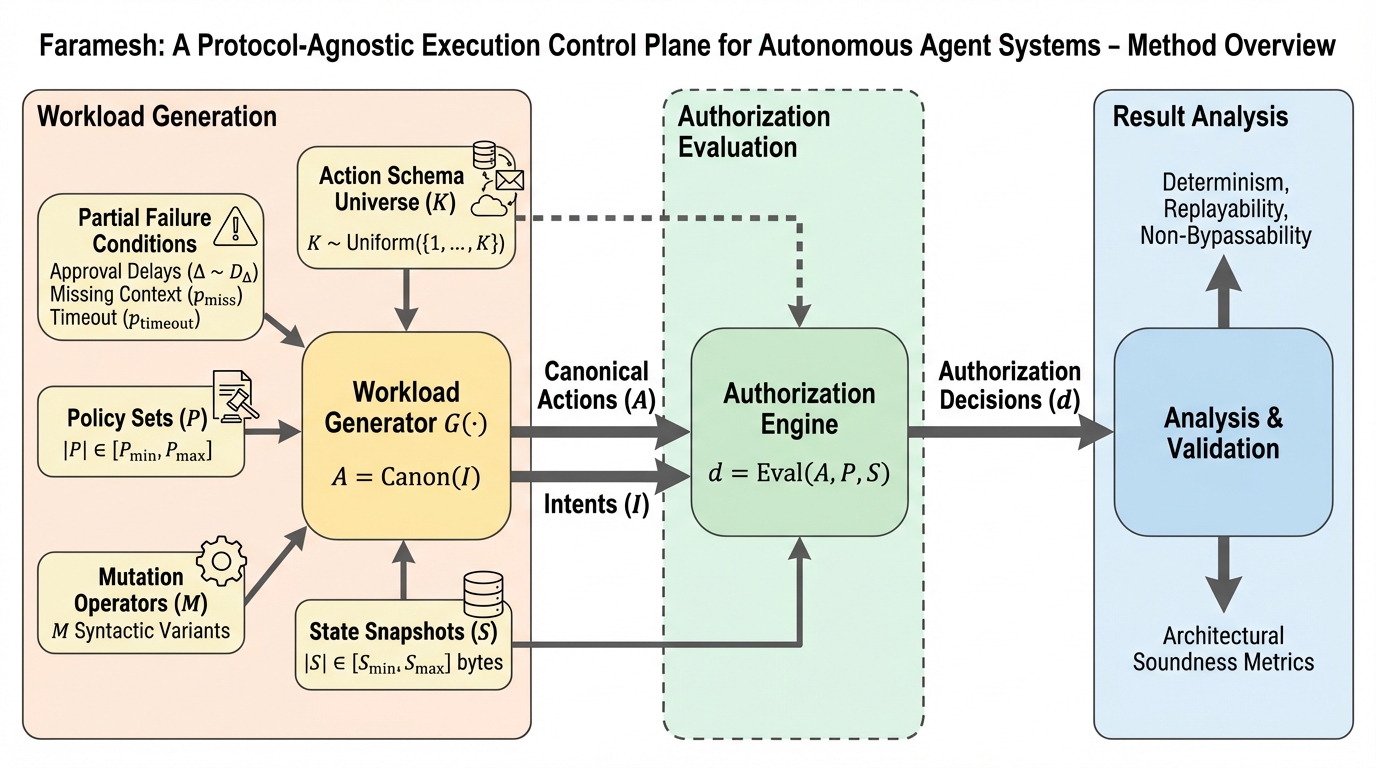
Farameshは、自律型エージェントがインフラ操作や資金移動などの現実的な影響を及ぼす際に、実行の直前で強制的に認可を判断する「アクション認可境界(AAB)」を導入する画期的な制御プレーンである。
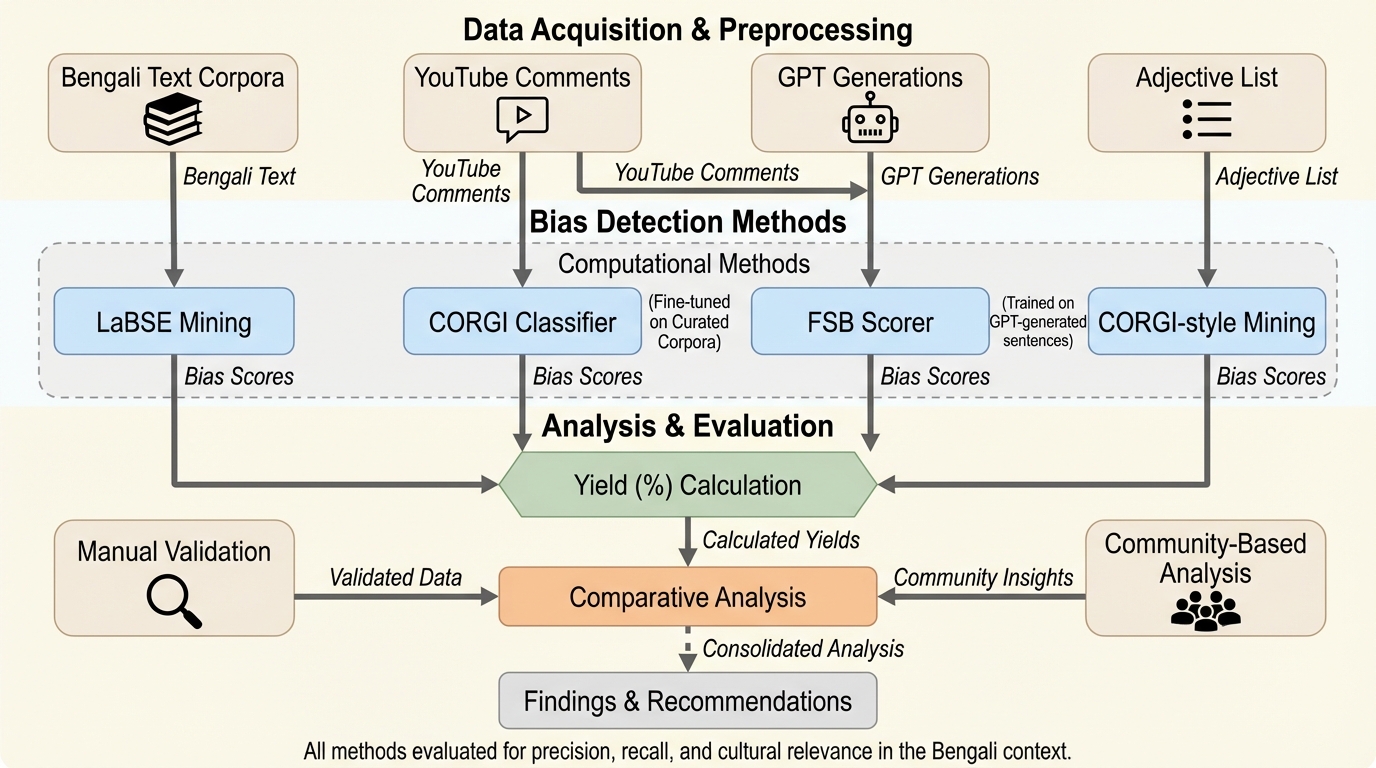
大規模言語モデル(LLM)におけるジェンダーバイアスの研究は英語に偏っており、ベンガル語のような低リソース言語かつ独自の文化背景を持つ言語での実態は十分に解明されていませんでした。 本研究では、翻訳、分類器、GPTによる生成、辞書ベースのマイニングなど多角的な手法を用いてベンガル語のバイアスを検証し、英語中心の検出枠組みをそのまま適用することの限界を明らかにしました。 農村部でのフィールド調査を含むコミュニティ主導のアプローチを導入することで、自動化システムでは捉えきれない文化特有のバイアスを特定し、より公平な自然言語処理システムの構築に向けた基盤を提示しました。
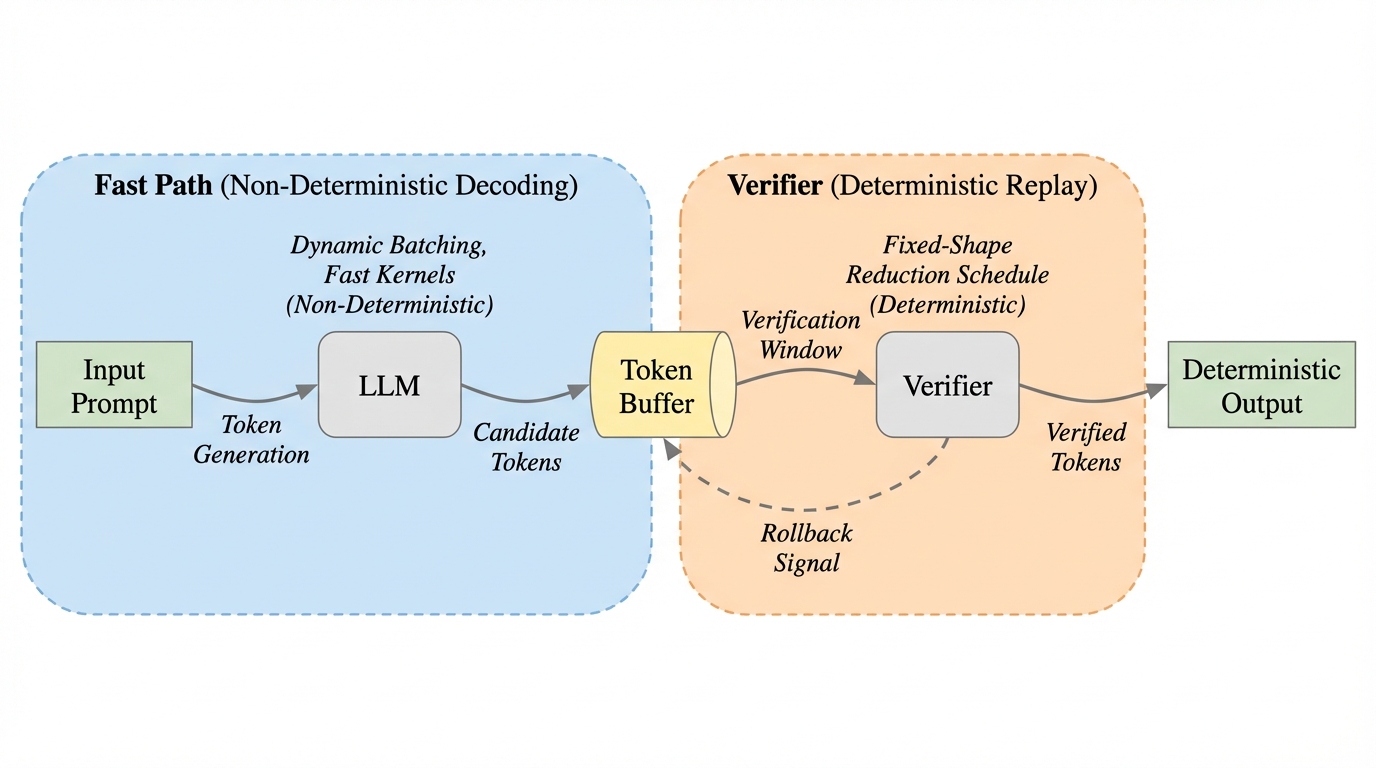
LLM推論における非決定性は、浮動小数点演算の非結合性と動的バッチ処理による計算順序の変化に起因しており、これを解決する既存のバッチ不変カーネル手法はスループットを最大56%低下させるなどの大きな性能上の代償を伴っていた。
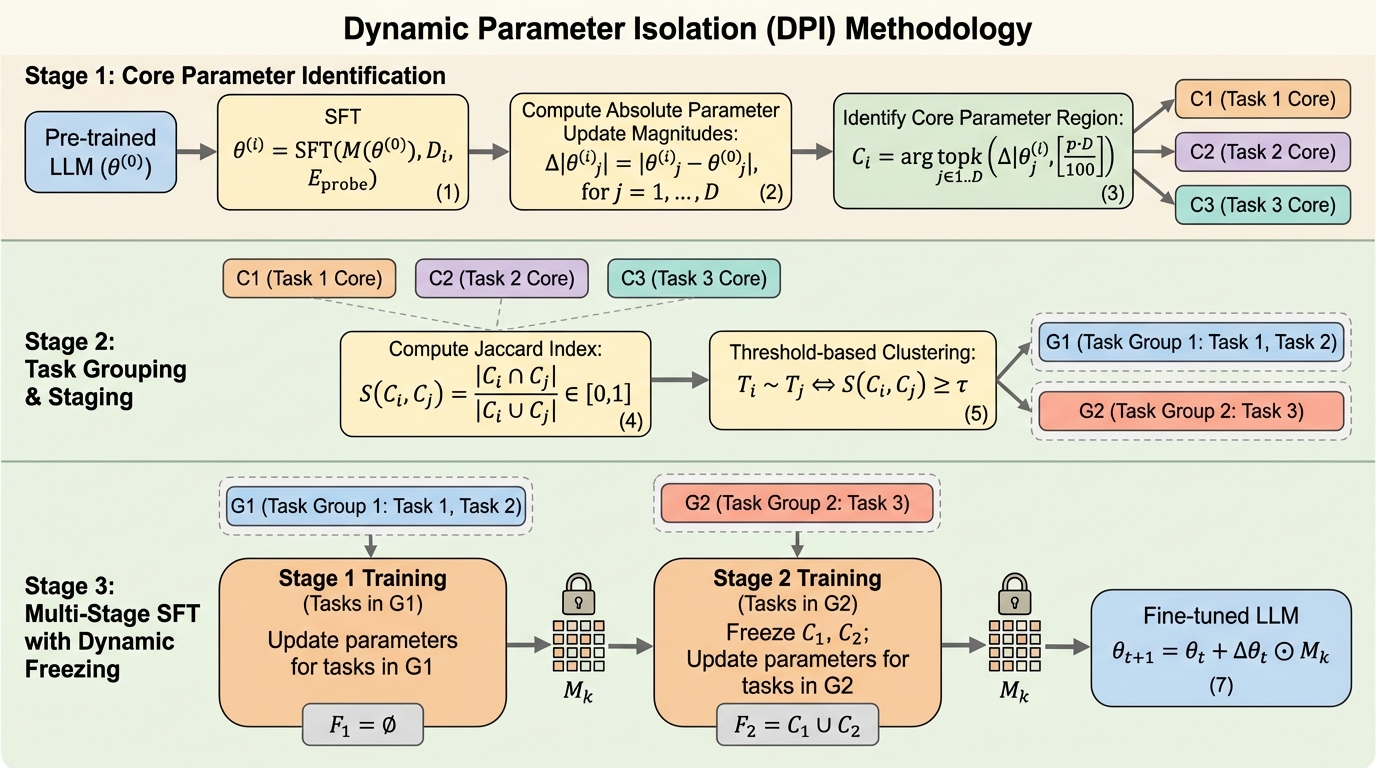
大規模言語モデル(LLM)の教師あり微調整(SFT)において、異なるタスク間の目的が衝突することで一方の性能が上がると他方が下がる「シーソー現象」を解決するため、タスクごとに依存するパラメータ領域が異なるという「パラメータの不均一性」に着目した新しい手法「DPI」が提案された。
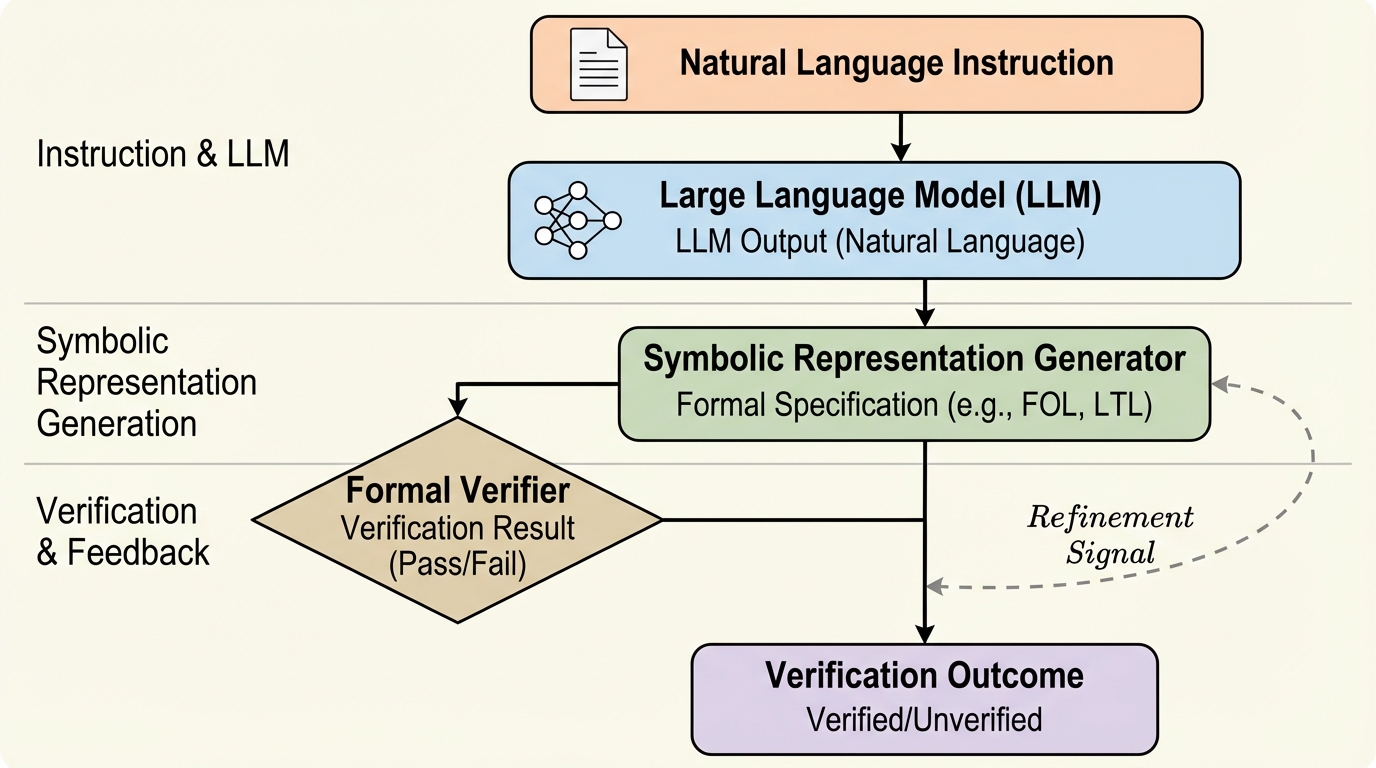
大規模言語モデル(LLM)が複雑な指示を誤解したり無視したりする問題に対し、指示を制約充足問題(CSP)として定式化し、論理的および意味的な制約の両面から出力を厳密に検証する汎用フレームワーク「NSVIF」が開発されました。
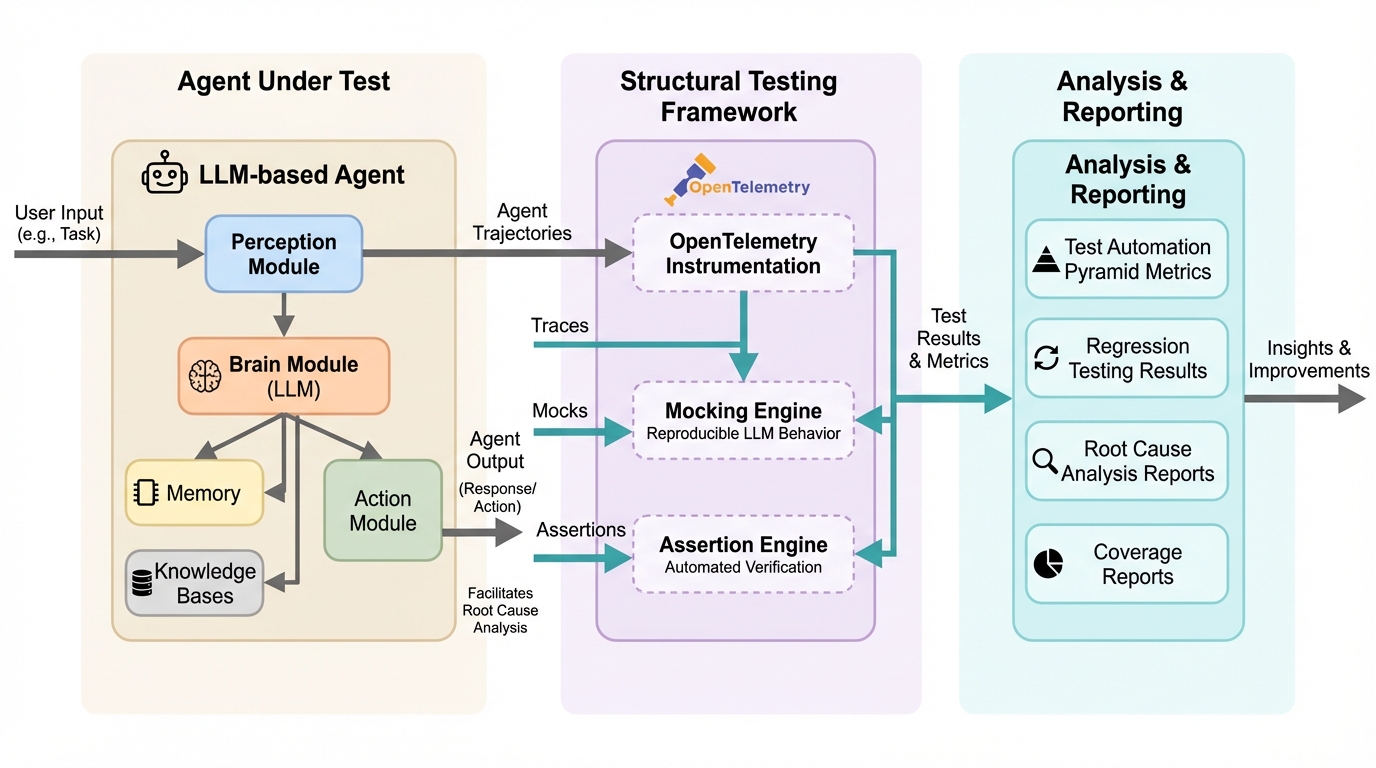
LLMエージェントの普及に伴い、従来のユーザー視点によるブラックボックス形式の受入テストだけでは、内部動作の不透明さや高コスト、再現性の欠如といった課題が顕在化している。 本研究では、OpenTelemetryを用いた実行トレースの取得、LLMの挙動を固定するモッキング、自動検証のためのアサーションを組み合わせた「構造テスト」の手法とフレームワークを提案し、技術的な深層レベルでの検証を可能にした。 このアプローチにより、テスト自動化ピラミッドやテスト駆動開発といったソフトウェア工学のベストプラクティスをエージェント開発に適用でき、品質向上と開発コストの削減、迅速な不具合原因の特定が実現されることを実証した。
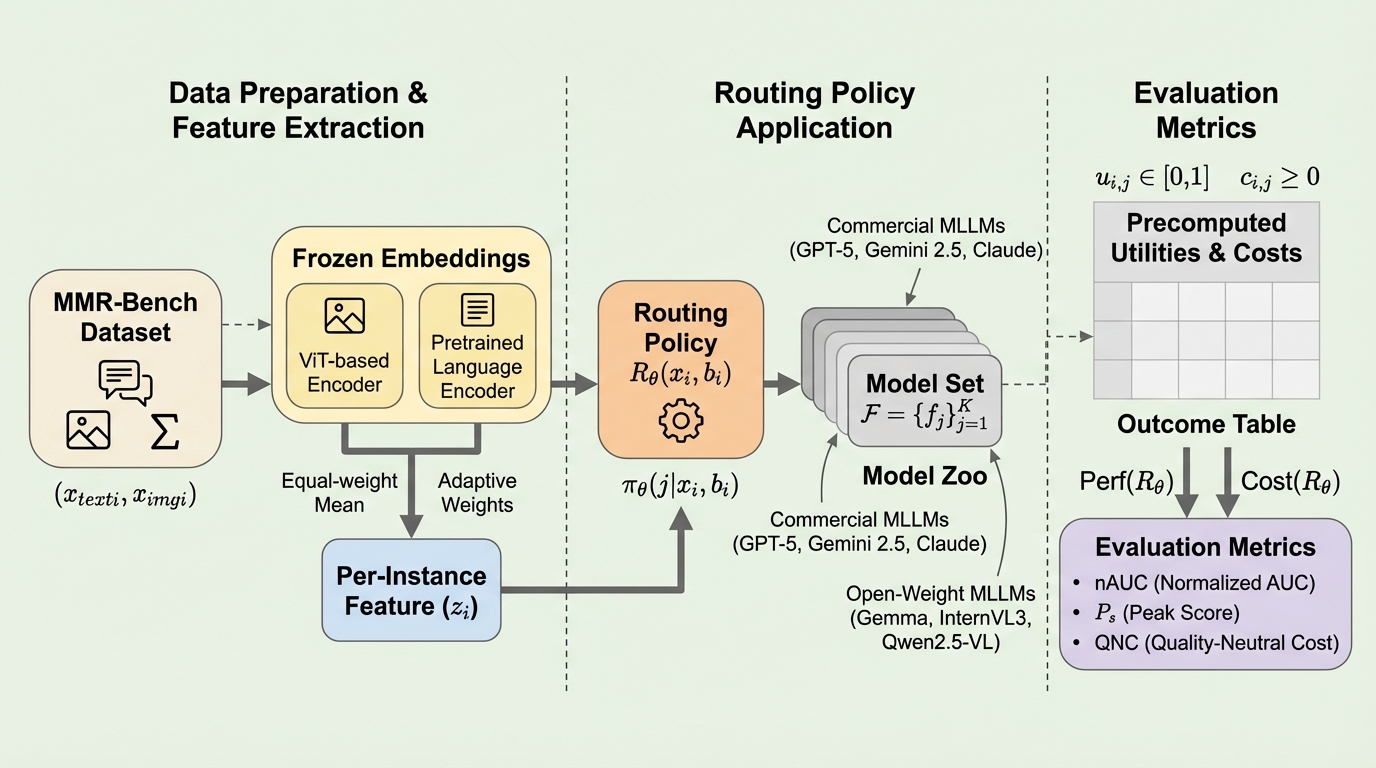
マルチモーダル大規模言語モデル(MLLM)の急速な発展に伴い、モデルごとの能力やコストの不均一性が顕著になっているが、本研究ではクエリごとに最適なモデルを選択して精度とコストのバランスを最適化する「ルーティング」のための包括的ベンチマーク「MMR-Bench」を提案した。