ReFuGe:LLMエージェントを用いたリレーショナルデータベース上の予測タスクのための特徴量生成
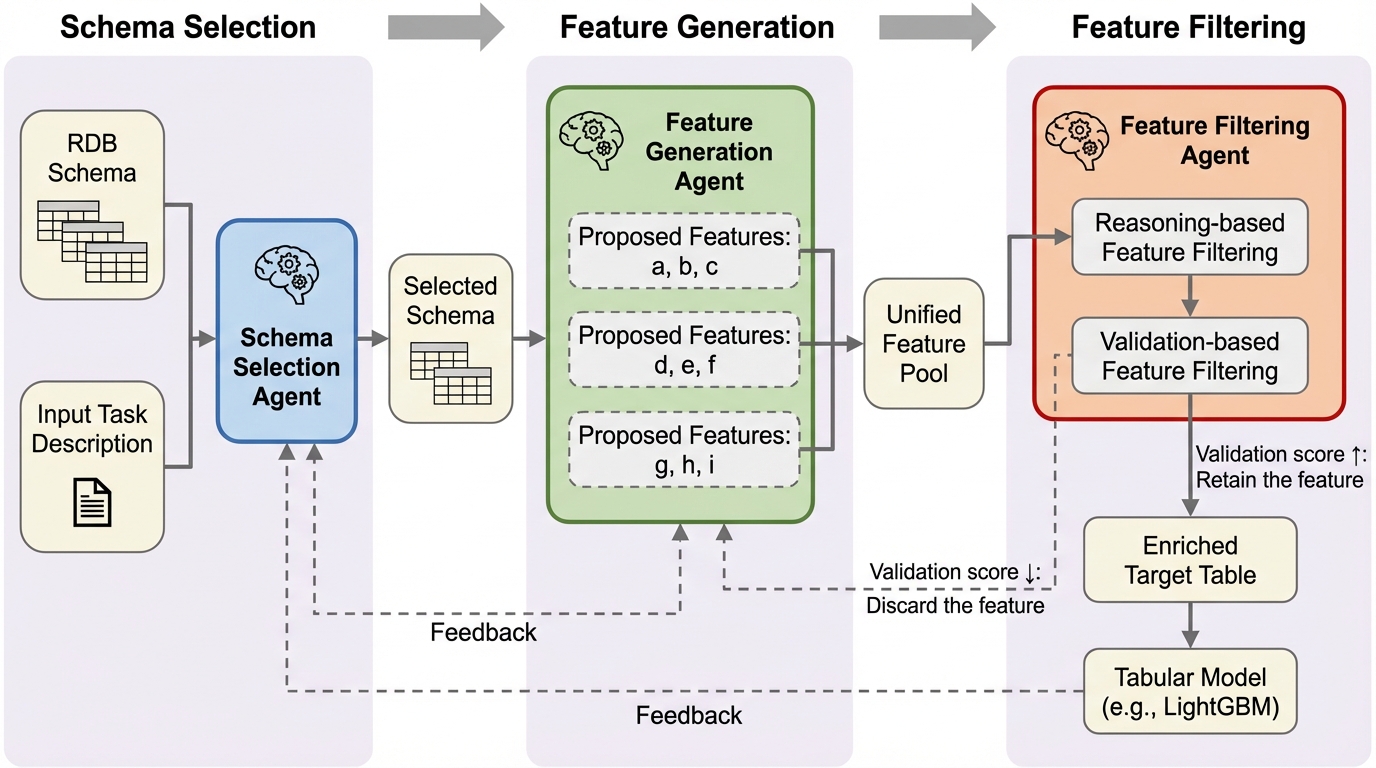
リレーショナルデータベースの複雑な構造から予測に有効な特徴量を自動生成するため、役割を専門化させた3つのLLMエージェント(スキーマ選択、特徴量生成、フィルタリング)を連携させ、反復的なフィードバックループを通じて探索空間を最適化する新しいフレームワーク「ReFuGe」が提案されました。
TL;DR(結論)
リレーショナルデータベースの複雑な構造から予測に有効な特徴量を自動生成するため、役割を専門化させた3つのLLMエージェント(スキーマ選択、特徴量生成、フィルタリング)を連携させ、反復的なフィードバックループを通じて探索空間を最適化する新しいフレームワーク「ReFuGe」が提案されました。 この手法は、テーブル間の複雑な関連性を論理的に推論する能力と、実際の予測精度に基づく数値的な検証を組み合わせることで、正解ラベルが存在しない特徴量探索の課題を解決し、人間による手動設計を必要としない効率的なデータパイプラインを実現します。 実世界の多様なドメインを含む7つのデータセットを用いた11の予測タスクにおいて、既存の機械学習モデルや他のLLMベースの手法を圧倒する平均ランク1.3という極めて高い性能を達成し、特に複雑なスキーマを持つデータベースにおいてその有効性が実証されました。
なぜこの問題か
現代のデジタル社会において、オンライン小売、ソーシャルネットワーク、フォーラムなどのウェブアプリケーションの根幹を支えているのはリレーショナルデータベース(RDB)です。これまで、RDBに関する研究の多くは、自然言語の質問からSQLクエリを生成するような情報検索タスクに主眼が置かれてきましたが、近年では蓄積されたデータから将来の行動や属性を予測するタスクへの関心が急速に高まっています。しかし、RDBから予測に真に役立つ特徴量を自動的に生成することには、主に3つの大きな困難が立ちはだかっています。 第一の課題は、複数のテーブルが複雑に関連し合うリレーショナル構造の中から、予測に寄与する信号を正しく理解し抽出することの難しさです。テーブル間の主キーと外部キーの関係性を辿り、どの情報がターゲットとなる予測対象と結びついているかを推論するには、高度な論理的思考が必要となります。第二の課題は、探索空間の膨大さです。テーブルの結合、集計関数の適用、データの変換といった操作の組み合わせは指数関数的に増大し、人間が手動ですべての可能性を検討することは事実上不可能です。第三の課題は、教師データの欠如です。…
核心:何を提案したのか
本研究では、LLMの高度な推論能力と自律的なエージェント構造を組み合わせた特徴量生成フレームワーク「ReFuGe(RElational FeatUre GEneration)」を提案しています。ReFuGeの核心は、単一のプロンプトで全てを解決しようとするのではなく、役割を専門化させた3つのエージェント(スキーマ選択、特徴量生成、特徴量フィルタリング)を構成し、それらを反復的なフィードバックループの中に配置した点にあります。このアプローチにより、複雑なデータベーススキーマに対しても、人間のようなドメイン知識に基づいた推論と、機械的な検証を高度に融合させることが可能になりました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related