人間を模倣した推論によるホワイトボックス・オペアンプ設計
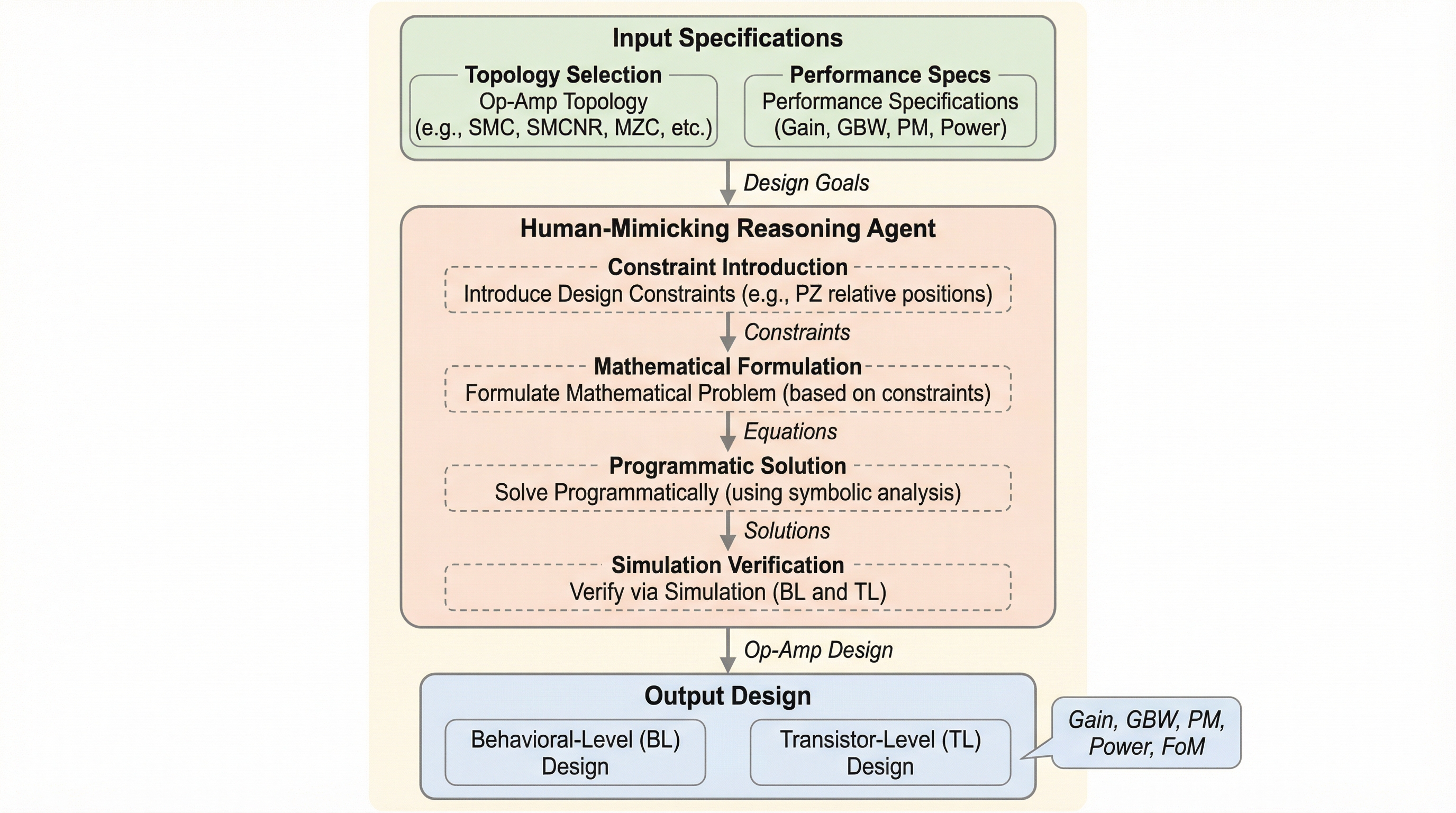
アナログ回路の基本要素である演算増幅器(オペアンプ)の設計において、従来のベイズ最適化などのブラックボックス手法は物理的根拠に乏しく、設計意図が不明確であるため、下流のトランジスタレベルへの移行時に設計不備や失敗を招くという課題がありました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
アナログ回路の基本要素である演算増幅器(オペアンプ)の設計において、従来のベイズ最適化などのブラックボックス手法は物理的根拠に乏しく、設計意図が不明確であるため、下流のトランジスタレベルへの移行時に設計不備や失敗を招くという課題がありました。
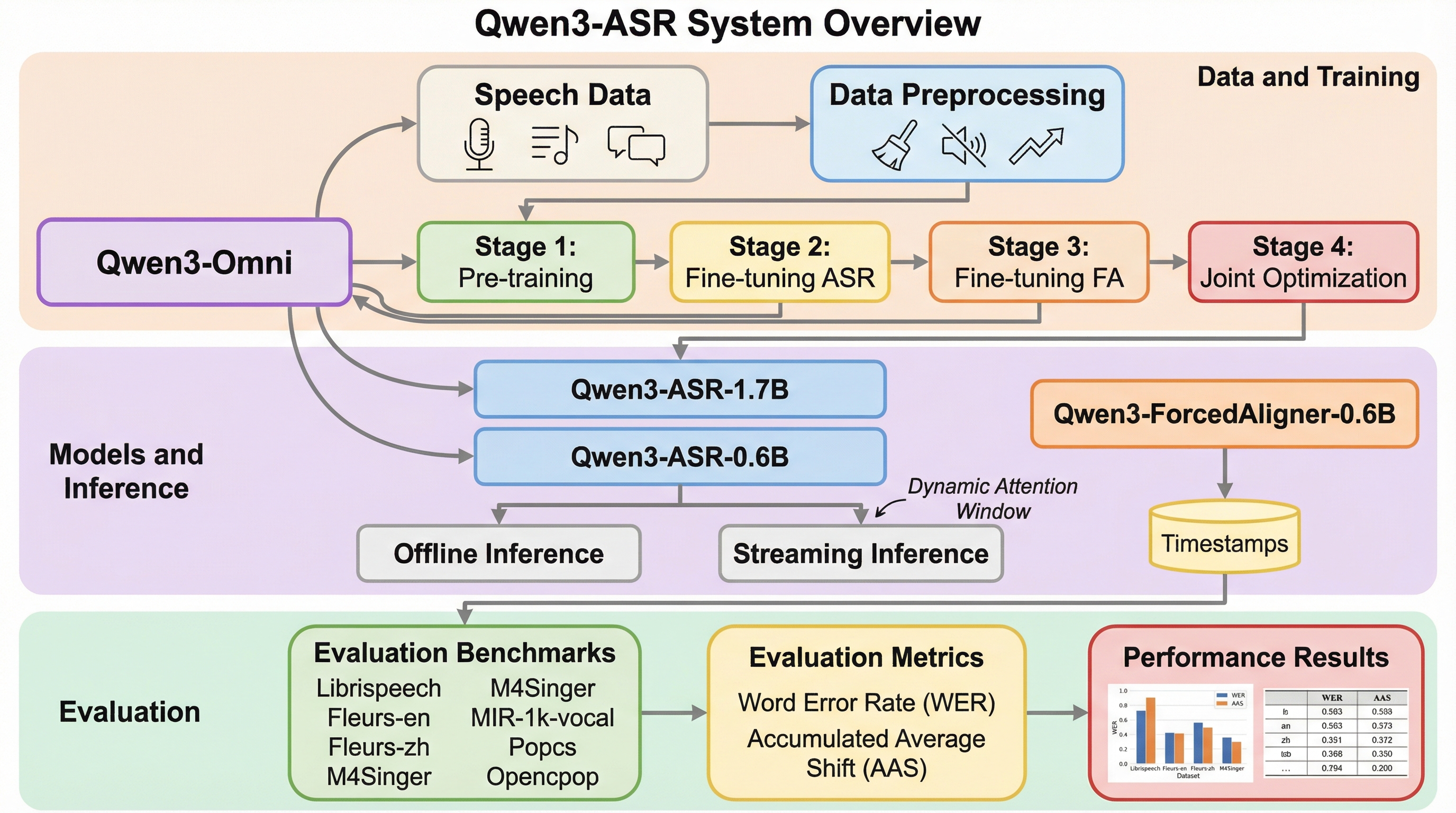
Qwen3-ASRは、52の言語と方言に対応する1.7Bおよび0.6Bの音声認識モデルと、11言語に対応した世界初のLLMベース非自己回帰型強制アライメントモデルで構成される強力な製品群である。
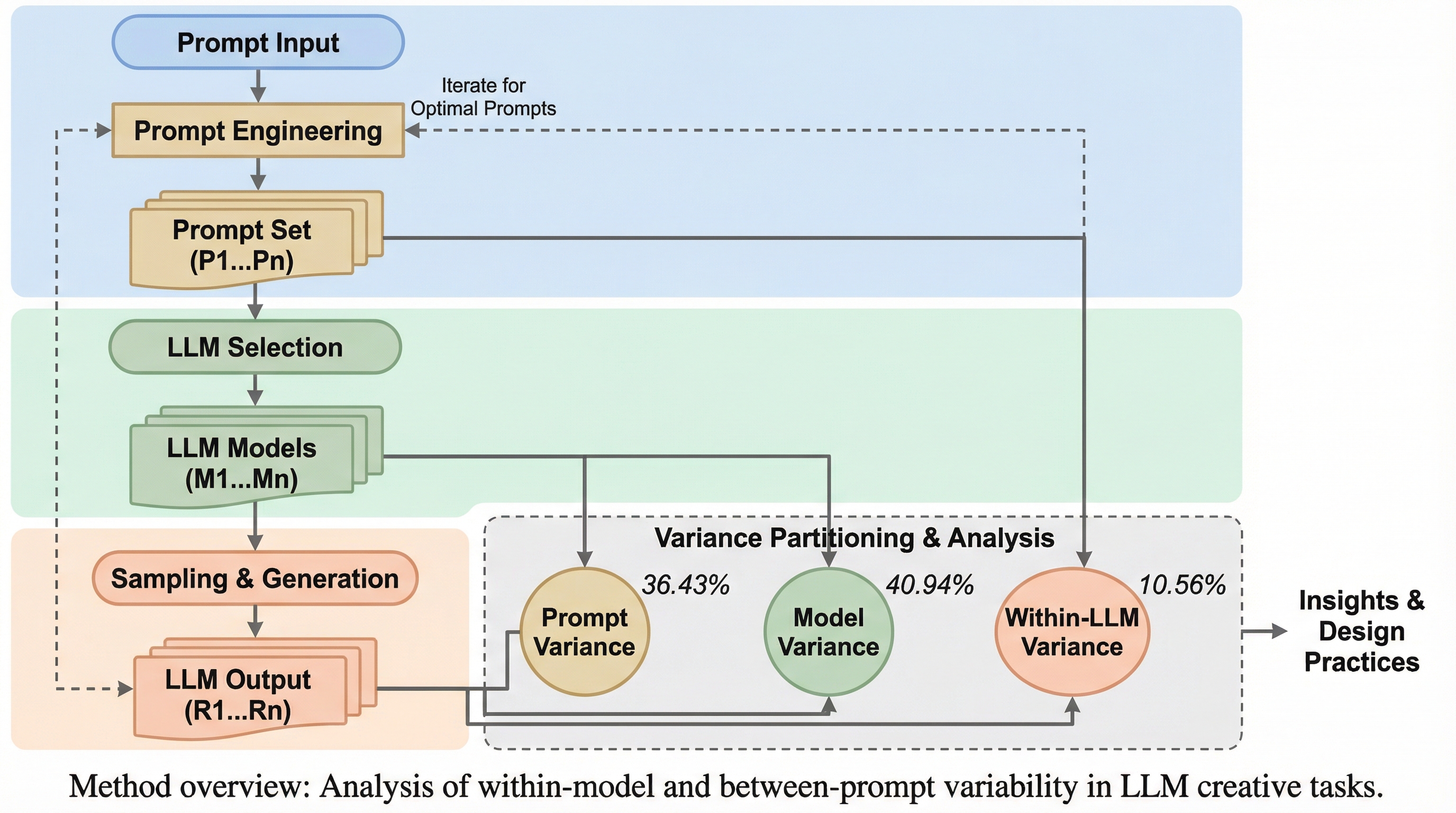
大規模言語モデル(LLM)の創造的出力における分散を詳細に分析した結果、出力の質である「独創性」についてはプロンプトが36.43%、モデルの選択が40.94%の影響力を持ち、両者が同等に重要であることが判明した。 一方で出力の量である「流暢性」については、モデルの選択が51.
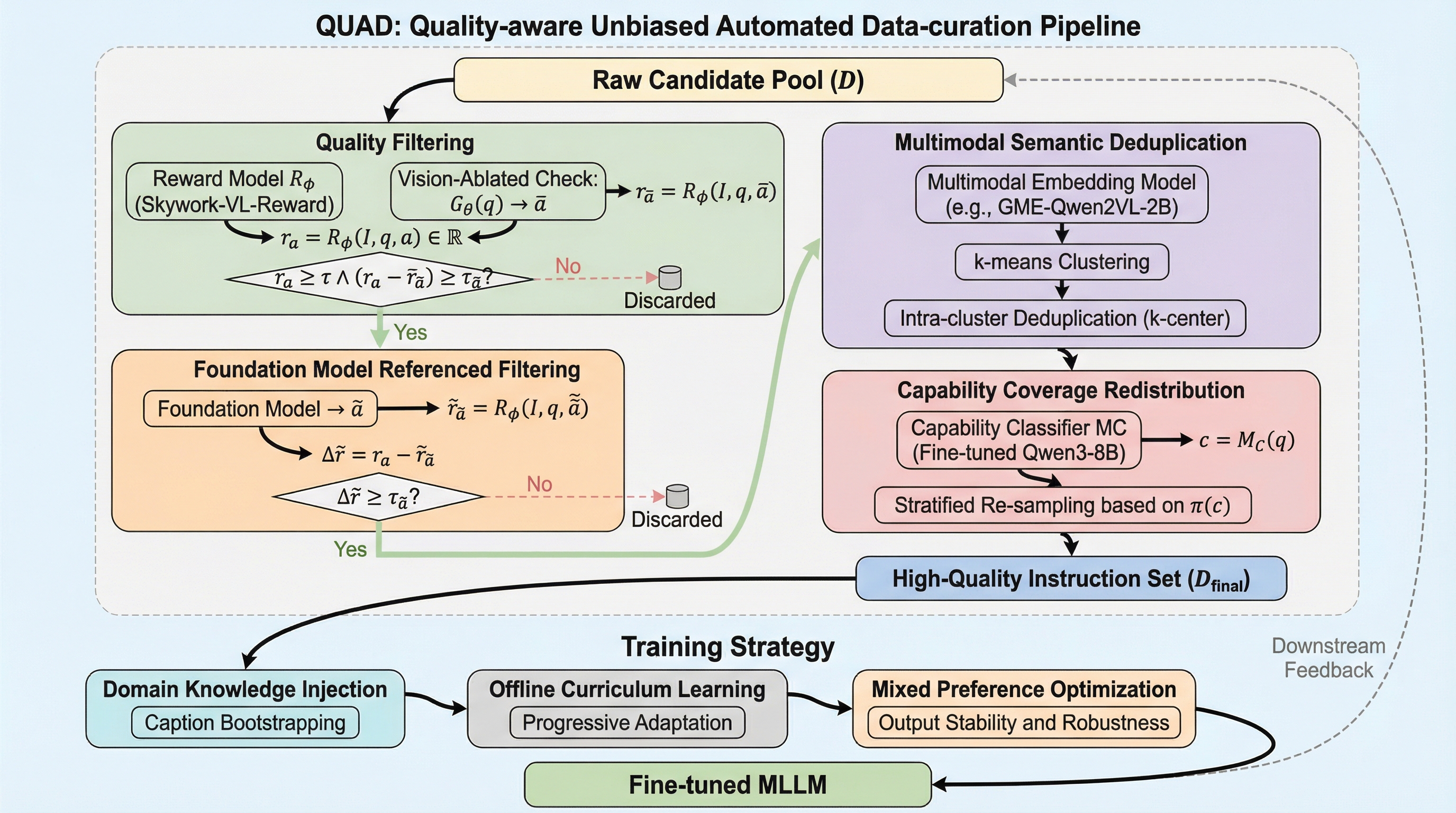
飲食・小売店舗(FSRS)の現場では、監視カメラのノイズや複雑な推論要求により汎用モデルの性能が低下するという課題がありましたが、本研究ではQwen3-VL-8Bを基盤としたドメイン特化型モデル「Ostrakon-VL」を開発しました。
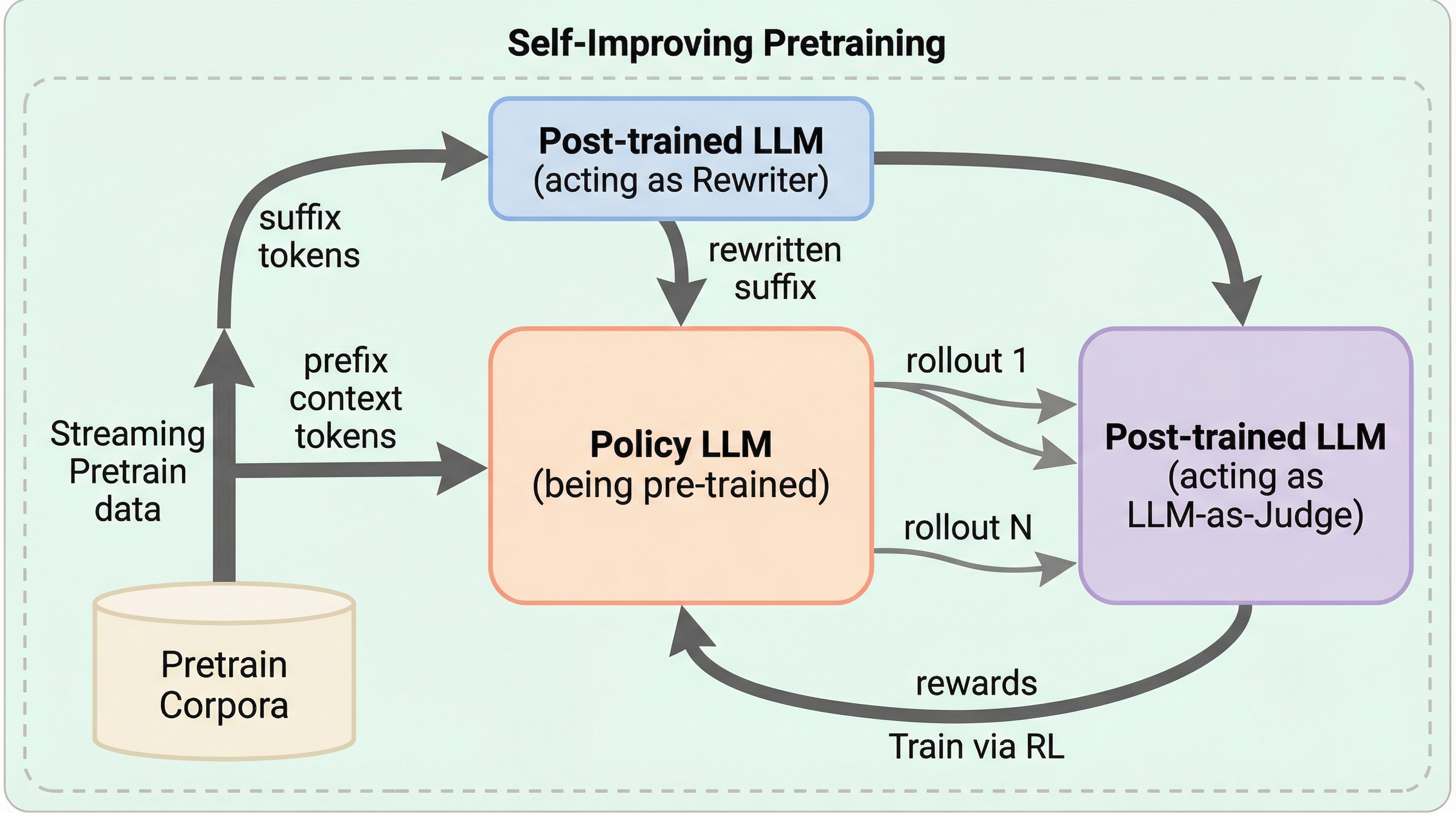
大規模言語モデルの安全性や事実性を根本から高めるため、従来の次単語予測に代わり、事後学習済みの強力なモデルを「判定役」および「書き換え役」としてループに組み込み、強化学習を用いてシーケンス単位で最適化する「自己改善型事前学習」を提案している。
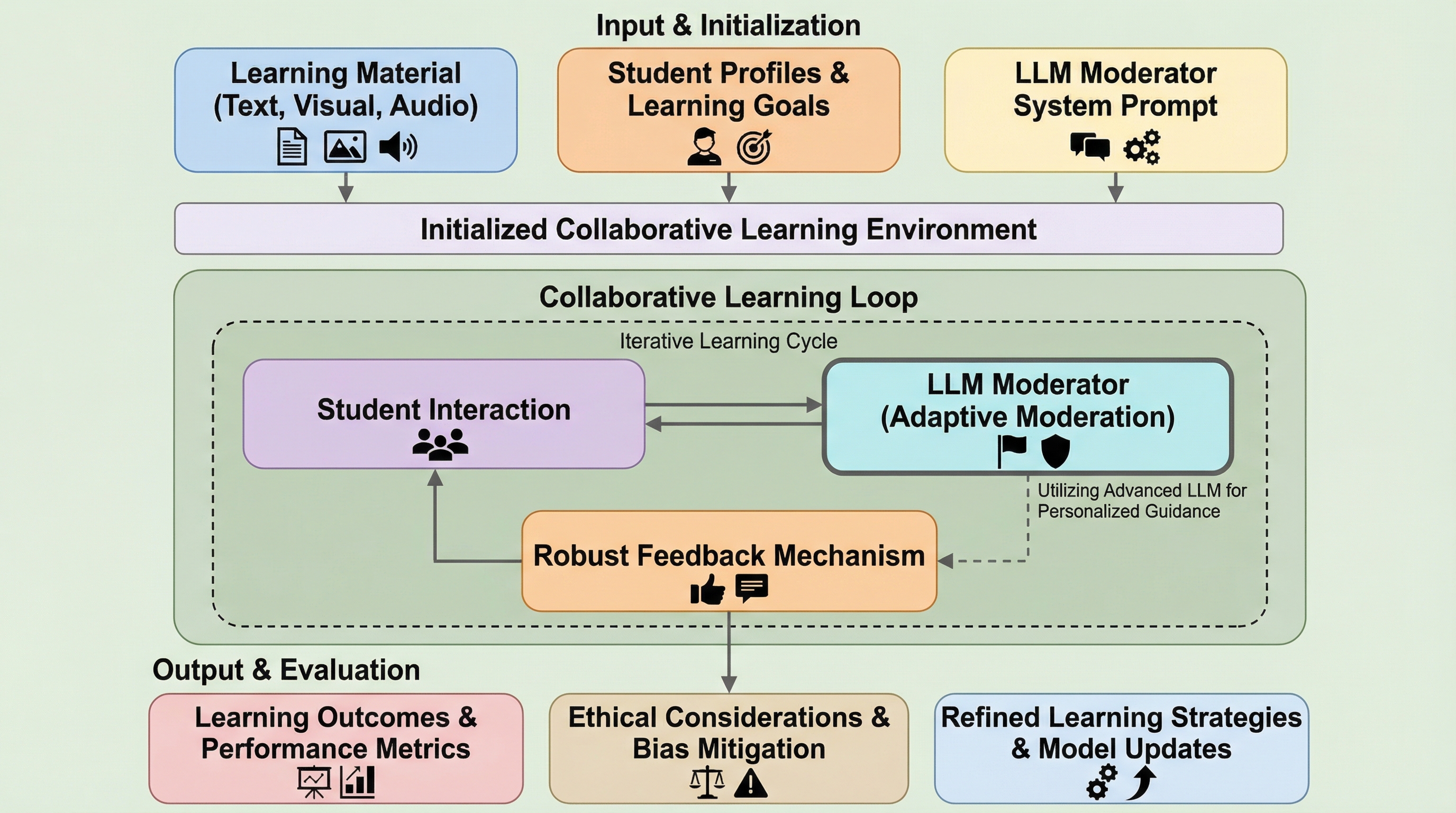
本研究では、高度な大規模言語モデルであるGPT-4oを動的なモデレーターとして統合し、リアルタイムでの議論促進と学習者のニーズへの適応を可能にする新しい協調学習フレームワークを提案しました。検索拡張生成(RAG)技術と多層的なフィードバック機構を組み合わせることで、従来の静的なシステムでは困難だった参加者間の公平な関与の促進や、文脈に応じた柔軟なプロンプト調整を実現しています。FairytaleQAデータセットを用いた検証により、学生のエンゲージメント向上や批判的思考の育成、さらには多様な学習環境におけるスケーラビリティと包括的な教育体験の提供が確認されました。
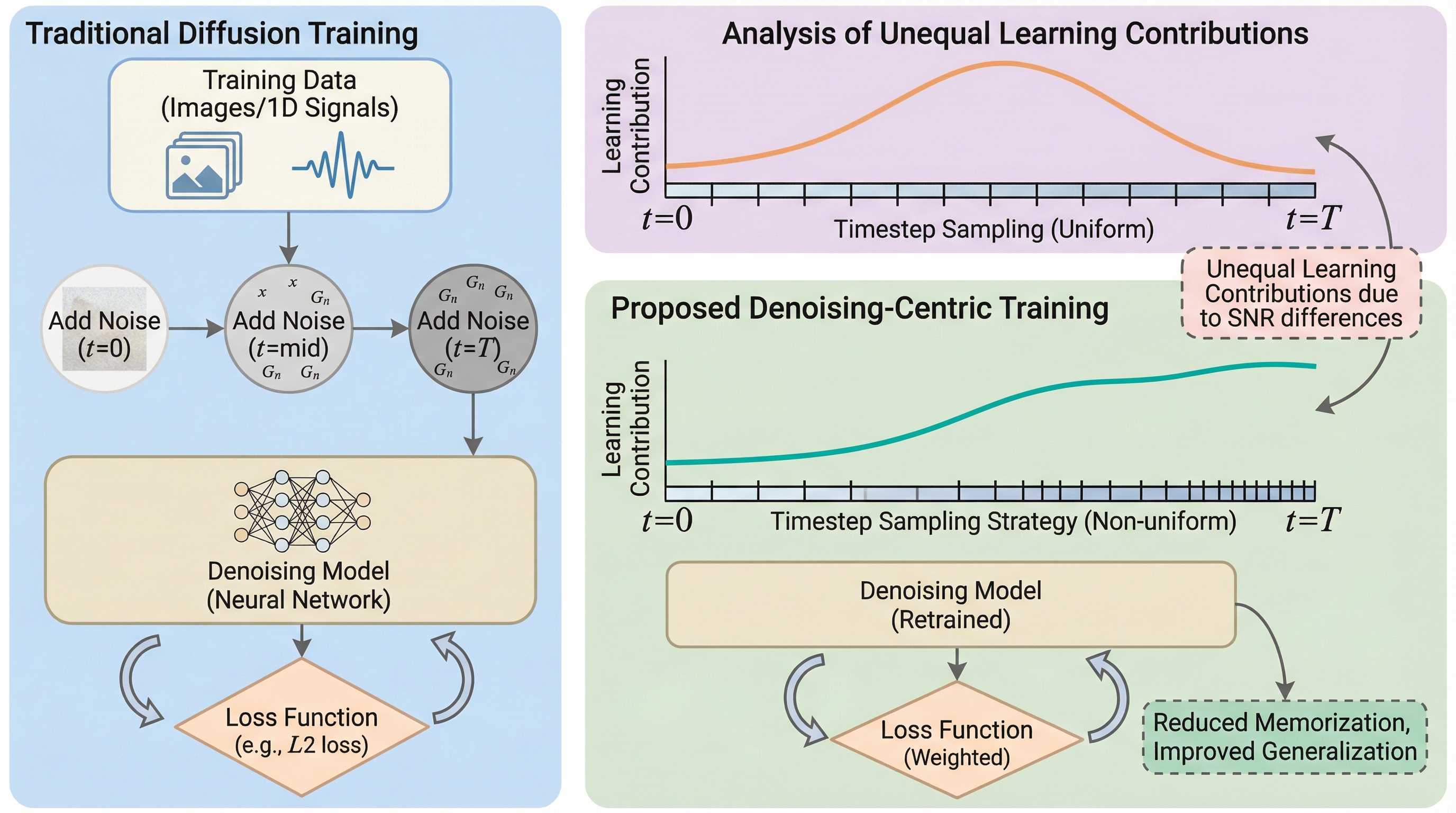
拡散モデルの学習において、タイムステップを一様にサンプリングすると信号対雑音比(SNR)の変動により学習の寄与が不均衡になり、特定の訓練データを過度に再現する「記憶」が生じる問題を、デノイジングの動態を重視する視点から解明した。
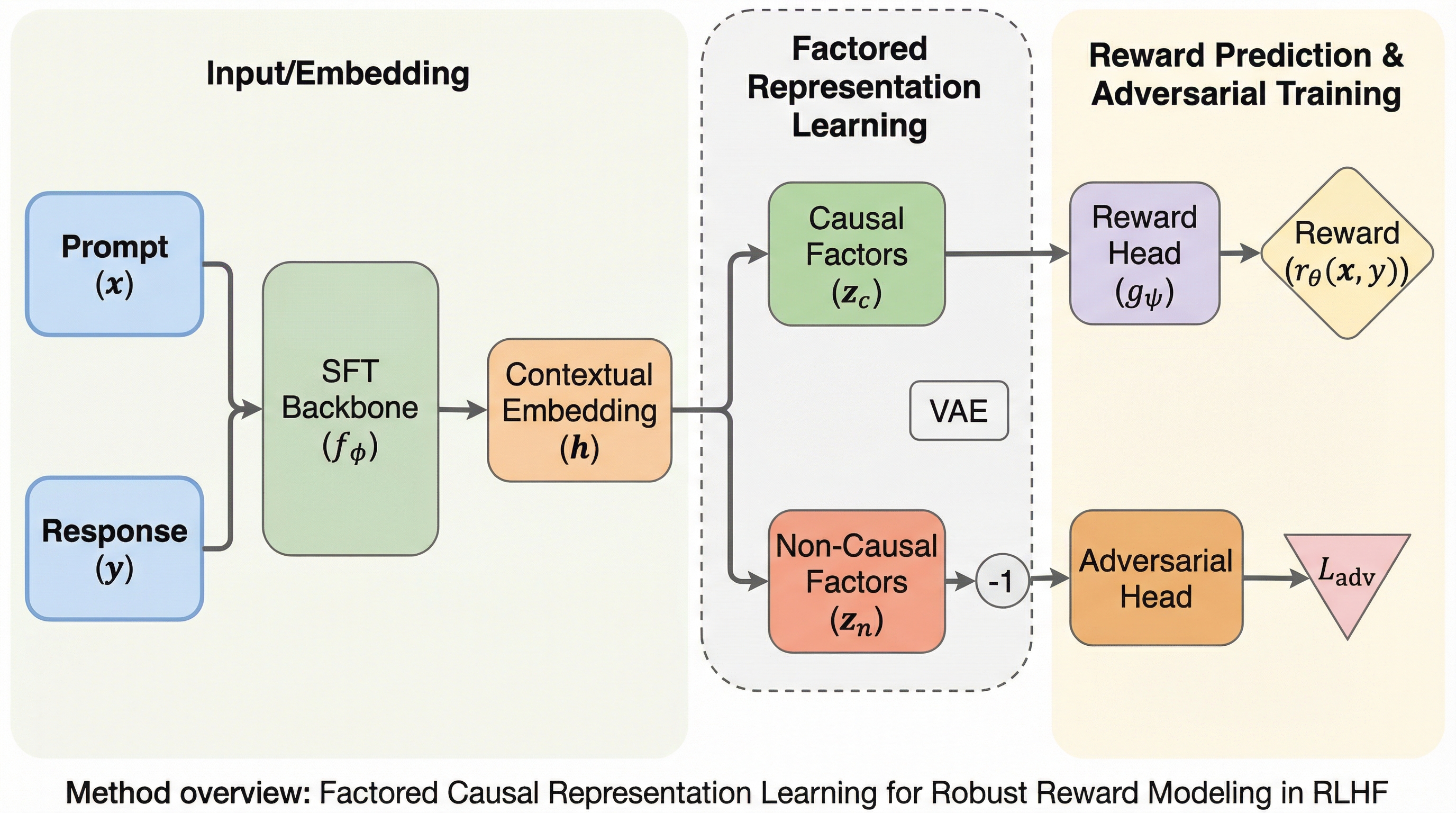
人間からのフィードバックを用いた強化学習(RLHF)において、報酬モデルが回答の長さや追従的な表現といった「偽の相関」を学習し、不当に高い報酬を得ようとする報酬ハッキングが生じる課題に対し、因果的な視点から表現を分解する新手法「CausalRM」を提案した。
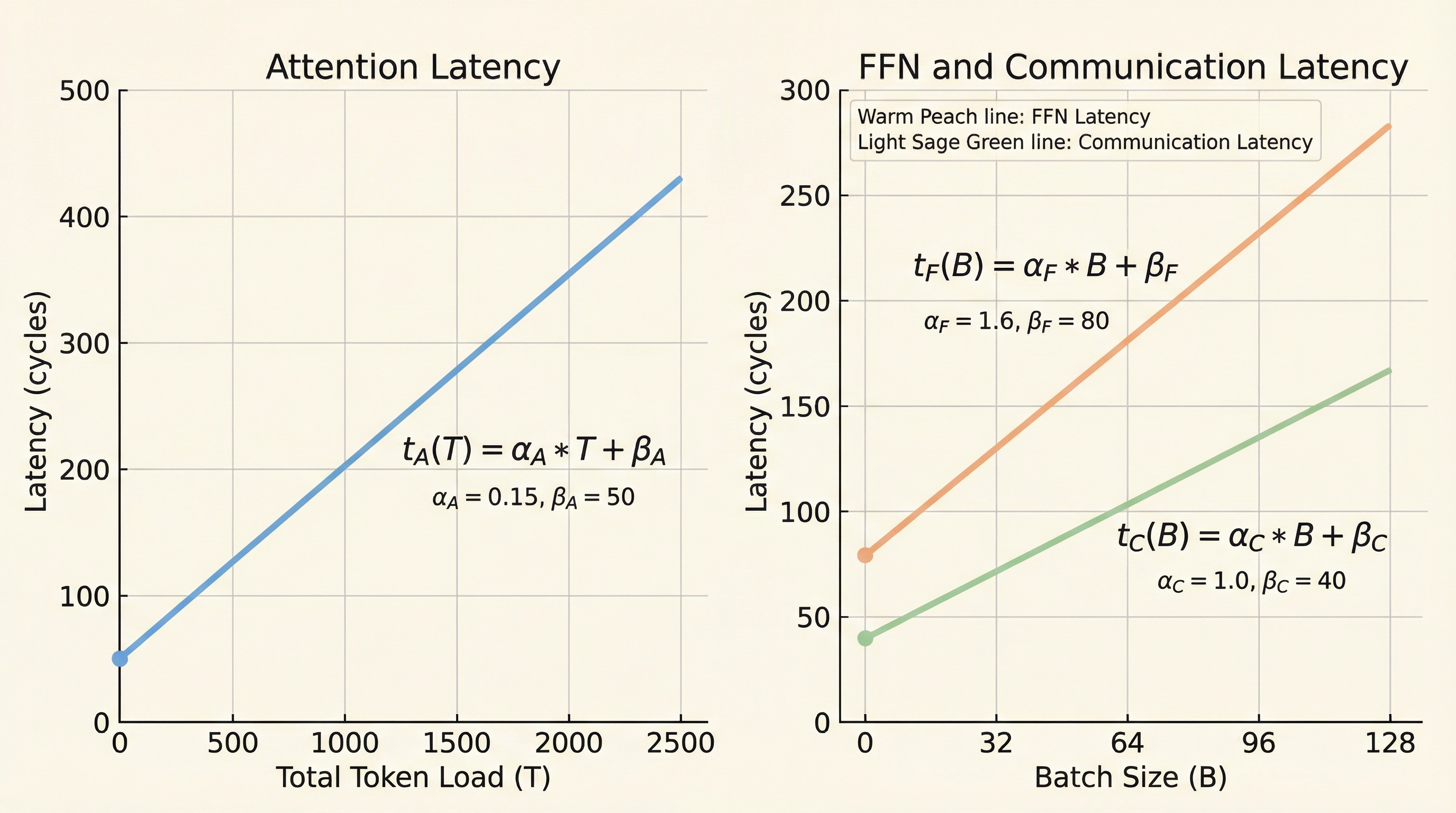
大規模言語モデルの推論効率を最大化するため、状態を持つAttention層と計算集約的なFFN層を分離して実行するAFDアーキテクチャにおいて、両者の最適なリソース配分比率を決定する理論的枠組みが構築された。
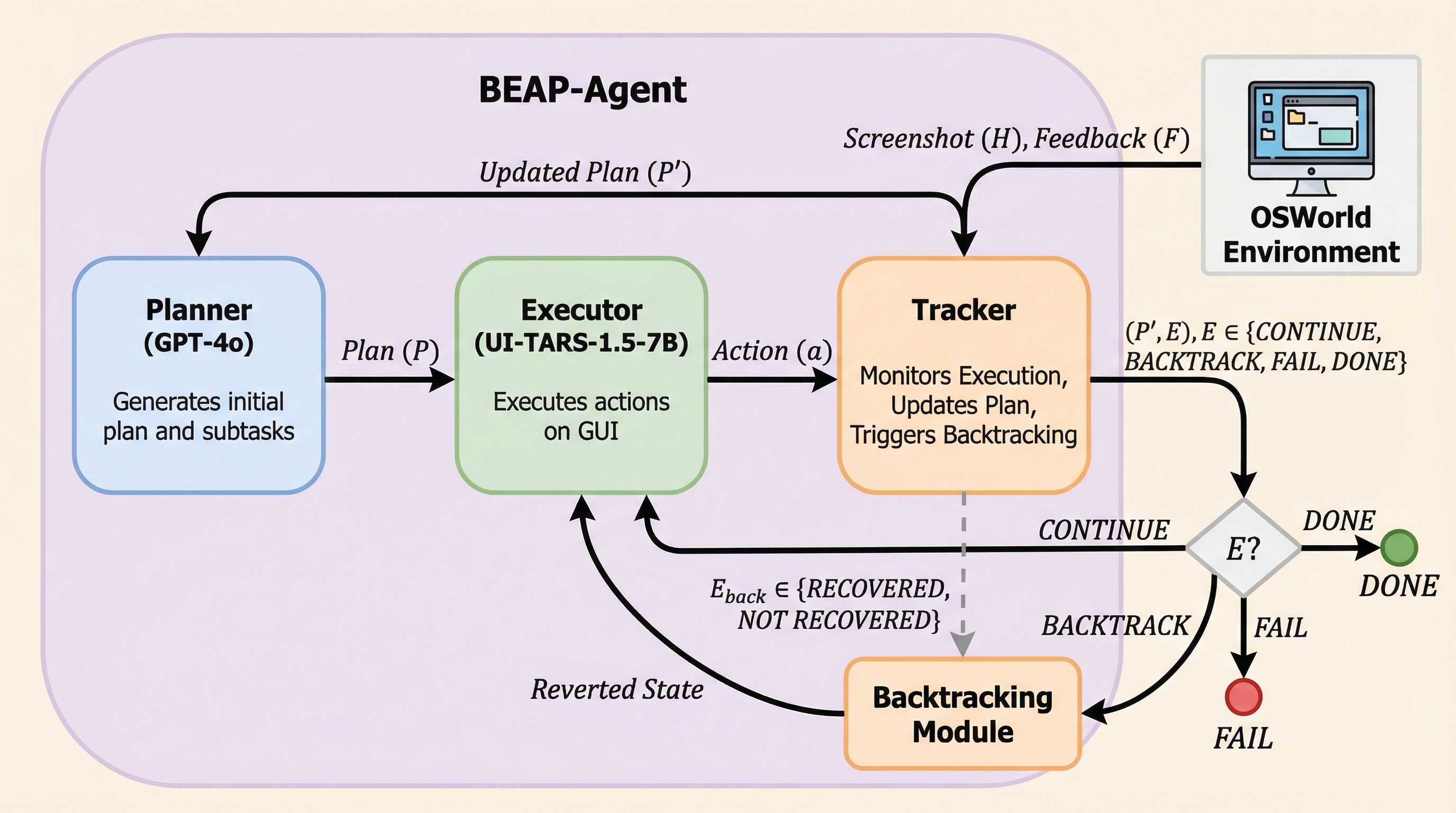
従来のGUIエージェントは、一度誤った操作を行うと復旧が困難でタスク失敗に直結するという課題がありましたが、本研究ではタスク実行を「深さ優先探索(DFS)」としてモデル化し、長距離かつ多段階のバックトラックを可能にする新フレームワーク「BEAP-Agent」を提案しました。