分離型LLMサービングにおける理論的に最適なAttention/FFN比率
大規模言語モデルの推論効率を最大化するため、状態を持つAttention層と計算集約的なFFN層を分離して実行するAFDアーキテクチャにおいて、両者の最適なリソース配分比率を決定する理論的枠組みが構築された。
TL;DR(結論)
大規模言語モデルの推論効率を最大化するため、状態を持つAttention層と計算集約的なFFN層を分離して実行するAFDアーキテクチャにおいて、両者の最適なリソース配分比率を決定する理論的枠組みが構築された。 KVキャッシュの増大やリクエストの頻繁な入れ替わりといった非定常なワークロードを、幾何分布を用いた確率モデルで定式化し、システムのスループットを最大化する最適な比率を導き出す閉形式の数式を開発することに成功した。 この理論に基づく最適比率は、実機トレースで較正されたシミュレーション結果と10パーセント以内の誤差で一致しており、ハードウェア特性やワークロード統計から最適なシステム構成を直接計算できる実用的な指針を提供している。
なぜこの問題か
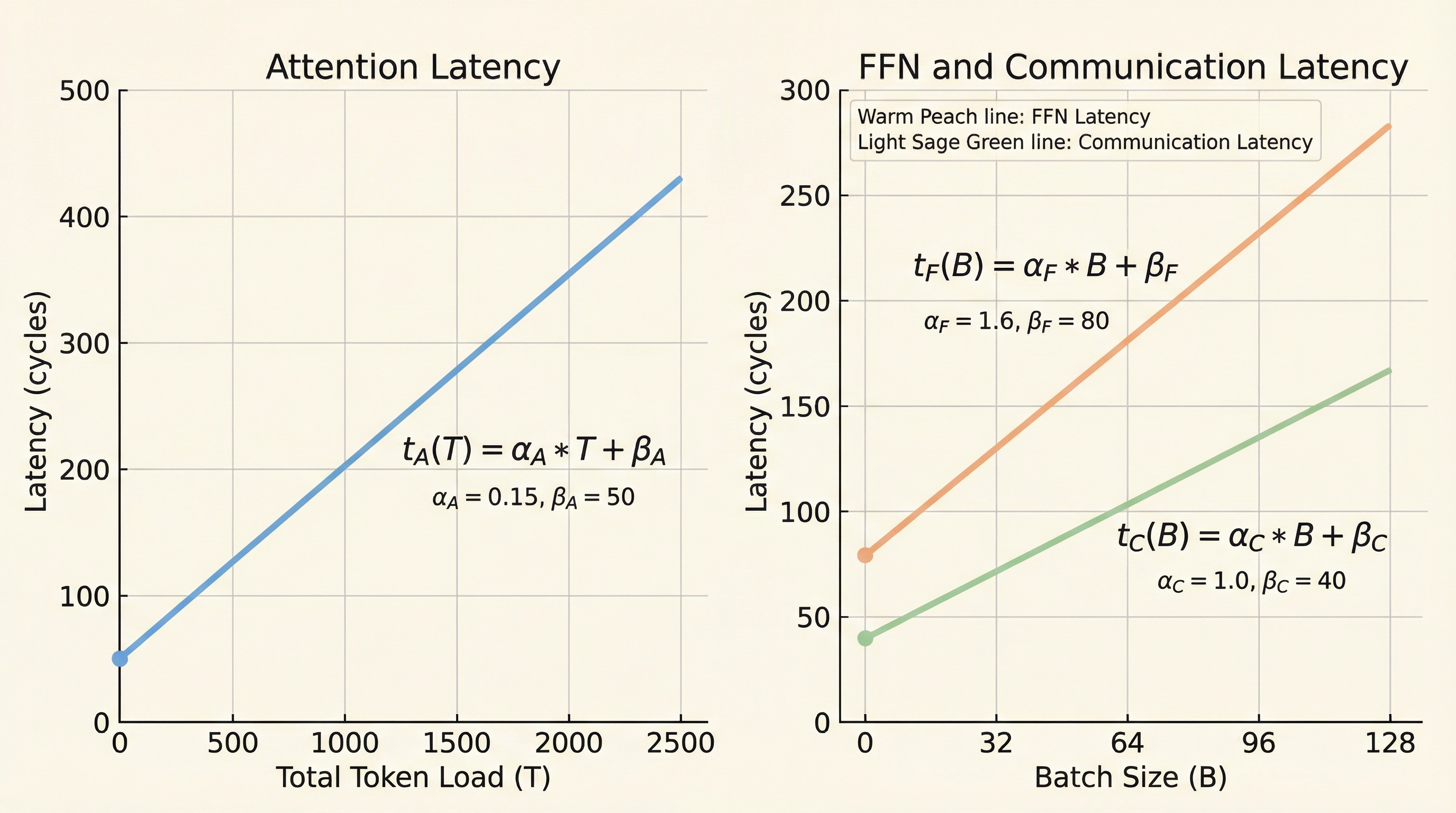
大規模言語モデル(LLM)の急速な普及に伴い、数千億ものパラメータを持つモデルをいかに効率的にサービングするかが喫緊の課題となっている。従来の単一デバイスによる実行では、メモリ容量や帯域の限界により、増大する要求に応えることが困難になっている。このため、複数のデバイスに処理を分散させるアーキテクチャへの移行が進んでいる。初期の分散手法としては、計算集約的なプリフィルフェーズと、メモリ帯域がボトルネックとなるデコードフェーズを分離する手法が提案された。しかし、デコードフェーズの内部においても、コンポーネントごとにリソース要求の特性が大きく異なるという問題が依然として残されていた。 具体的には、TransformerモデルのAttention層は過去のトークン情報を保持するKVキャッシュを読み書きするため、状態を持ち、メモリ帯域に強く依存する。一方で、FFN(Feed-Forward Network)層は状態を持たず、十分なバッチサイズがあれば演算器の計算能力を最大限に活用できる計算集約的な特性を持っている。…
核心:何を提案したのか
本研究の核心は、AFDサービングにおける確率的なワークロードモデルを開発し、最適なAttention対FFNの比率を閉形式の数式で導出したことにある。Attention側の負荷が時間とともに変化する動的な性質を、マルコフ的なダイナミクスとして定式化した。具体的には、リクエストの終了確率が幾何分布に従うという経験的事実に基づき、KVキャッシュの平均的な負荷を算出した。このモデルにより、マイクロバッチのパイプライン処理、同期バリア、および継続的なバッチ処理(Continuous Batching)の影響を考慮した解析が可能になった。 提案された数式は、ハードウェアのレイテンシ係数とワークロードの統計量を入力とする。具体的には、Attentionの計算時間をKVキャッシュの総トークン量に対する線形モデルとして定義し、FFNの計算時間をバッチサイズに対する線形モデルとして定義した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related