RLHFにおける頑健な報酬モデリングのための因子分解因果表現学習
人間からのフィードバックを用いた強化学習(RLHF)において、報酬モデルが回答の長さや追従的な表現といった「偽の相関」を学習し、不当に高い報酬を得ようとする報酬ハッキングが生じる課題に対し、因果的な視点から表現を分解する新手法「CausalRM」を提案した。
TL;DR(結論)
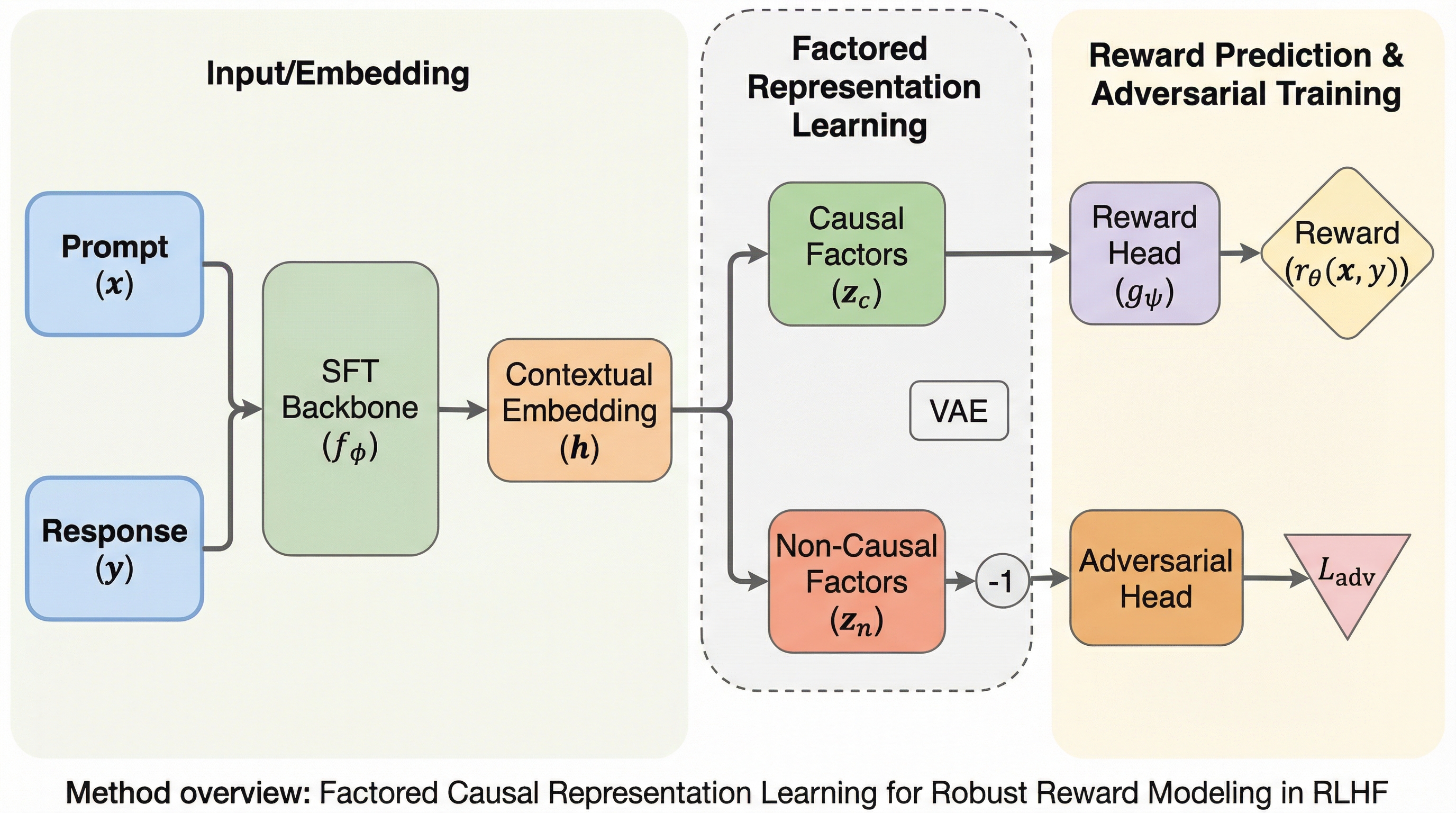
人間からのフィードバックを用いた強化学習(RLHF)において、報酬モデルが回答の長さや追従的な表現といった「偽の相関」を学習し、不当に高い報酬を得ようとする報酬ハッキングが生じる課題に対し、因果的な視点から表現を分解する新手法「CausalRM」を提案した。 この手法は、言語モデルの埋め込み表現を、報酬予測に不可欠な「因果的因子」と、長さやバイアスなどの報酬に無関係な属性を保持する「非因果的因子」に明示的に因子分解し、報酬予測ヘッドが因果的因子のみを参照するように構造的な制約を課すことで、偽の相関の影響を排除する。 数学推論や対話タスクを用いた広範な実験の結果、提案手法は報酬モデルの予測精度を向上させるだけでなく、下流のRLHFにおける方策の性能を改善し、回答の長さやユーザーへの過度な同調に対する感度を抑制して、未知のデータに対しても頑健な報酬予測が可能であることを実証した。
なぜこの問題か
大規模言語モデルを人間の好みに合わせるRLHFのプロセスでは、人間の判断を模倣する報酬モデルが極めて重要な役割を果たす。しかし、標準的な報酬モデルの学習には、人間が好みを判断する際の本質的な理由とは無関係な特徴、すなわち「偽の相関」を学習しやすいという重大な欠陥がある。例えば、モデルは回答の論理的な正しさではなく、単に回答が長いことや、ユーザーの意見に盲目的に同調するような追従的な言い回しに対して高いスコアを割り当ててしまう傾向がある。このようなショートカットを学習した報酬モデルを強化学習の報酬源として利用すると、エージェントは予測される報酬を最大化するために、内容が不正確であっても見かけだけを整える「報酬ハッキング」を引き起こす。 これまでの研究では、回答の長さなどの特定の要因を制御するために、正則化手法や特定の報酬ヘッドの分離などが提案されてきた。しかし、これらの手法は制御すべきバイアス要因を事前に明示的に指定する必要があり、現実の複雑なタスクにおいてモデルがどのような偽の相関を悪用するかをすべて予測して定義することは極めて困難である。…
核心:何を提案したのか
本研究では、因果表現学習の知見を報酬モデリングに応用した新しいフレームワーク「CausalRM」を提案している。この手法の核心は、モデルが生成する文脈埋め込みを、報酬予測に十分な情報を持つ「因果的因子」と、報酬とは無関係な属性を捉える「非因果的因子」の二つに明示的に分解することにある。因果的因子は、人間の好みを決定づける本質的な特徴を保持するように学習され、一方で非因果的因子は、回答の長さやスタイルのバイアスといった報酬予測に寄与すべきではない情報を吸収する役割を担う。 CausalRMの最大の特徴は、報酬予測を行うヘッドが因果的因子のみに依存するように構造的な制約を課している点である。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related