LLMの創造的タスクにおけるモデル内およびプロンプト間の変動分析
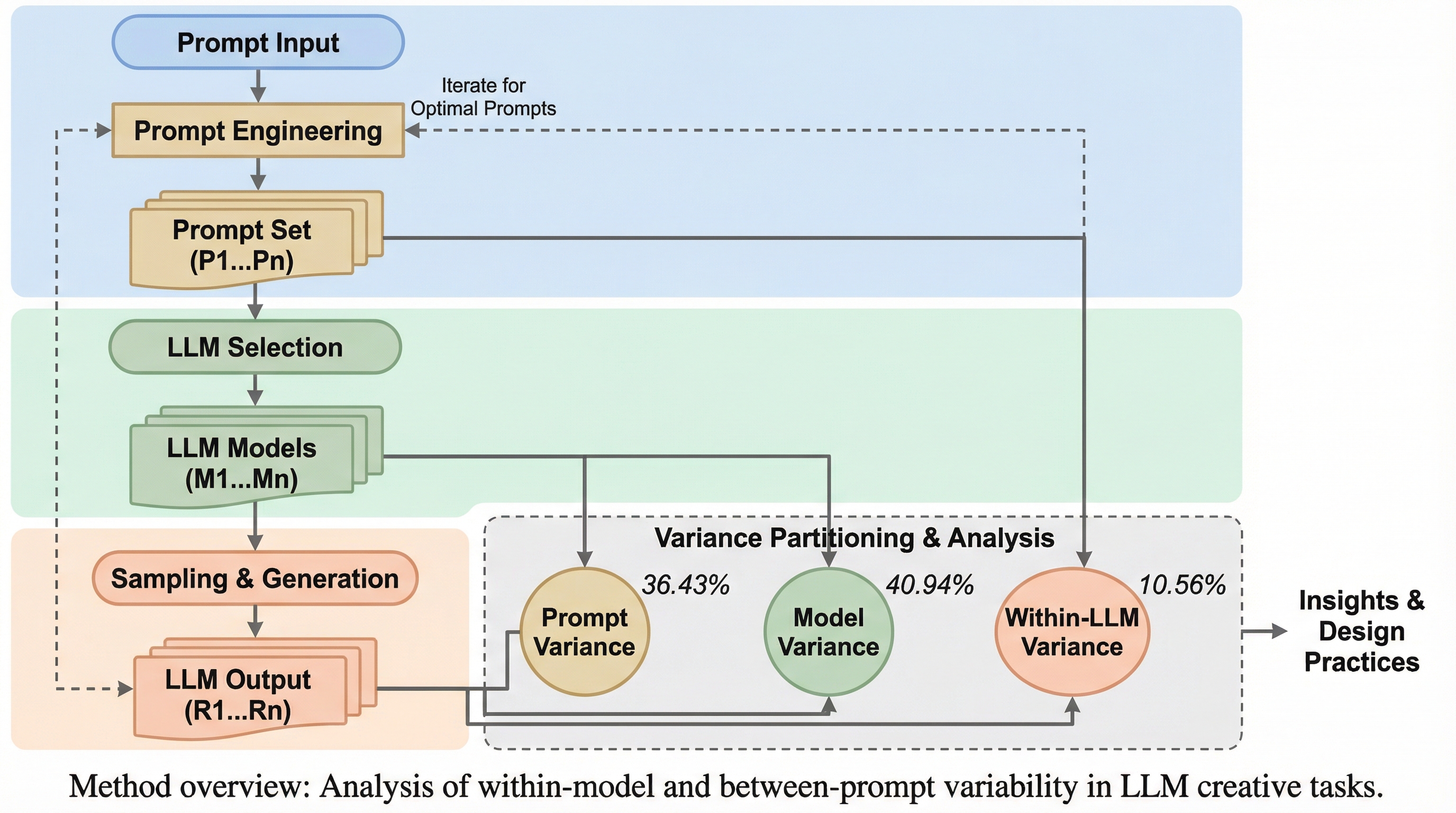
大規模言語モデル(LLM)の創造的出力における分散を詳細に分析した結果、出力の質である「独創性」についてはプロンプトが36.43%、モデルの選択が40.94%の影響力を持ち、両者が同等に重要であることが判明した。 一方で出力の量である「流暢性」については、モデルの選択が51.
TL;DR(結論)
大規模言語モデル(LLM)の創造的出力における分散を詳細に分析した結果、出力の質である「独創性」についてはプロンプトが36.43%、モデルの選択が40.94%の影響力を持ち、両者が同等に重要であることが判明した。 一方で出力の量である「流暢性」については、モデルの選択が51.25%、モデル内部のサンプリングによる変動が33.70%を占めるのに対し、プロンプトの影響はわずか4.22%にとどまり、量はモデル固有の特性に強く依存している。 12種類のモデルと10種類のプロンプトを用いた12,000件のサンプル分析により、単一の試行による評価はサンプリングのノイズをプロンプトの効果と誤認するリスクがあるため、複数回の試行による評価の重要性が統計的に示された。
なぜこの問題か
プロンプトエンジニアリングの分野では、自然言語による指示が大規模言語モデル(LLM)を予測可能かつ最適化された出力へと導くという「設計としてのプロンプト」というパラダイムが前提となっている。この考え方では、プロンプトの策定がモデルの挙動を決定する主要な要因であると見なされ、モデルは入力から出力への決定論的な写像として機能すると暗黙のうちに仮定されている。その結果、多くの評価研究では特定のプロンプトに対して一度だけモデルを実行し、得られた出力をそのプロンプト下でのモデルの代表的な挙動として解釈している。しかし、LLMは本質的に確率的な性質を持っており、出力分布からサンプリングを行う過程で生じる変動は、既存の研究ではほとんど測定されず、無視される傾向にある。温度設定をゼロにした場合であっても、GPUの並列処理やバッチ処理の影響によって非決定性が生じることが指摘されており、正確な内容の再現性は重要な課題となっている。 このようなサンプリングに起因する分散が無視されると、その変動がモデルの選択やプロンプトの効果といった他の要因に吸収され、プロンプトによる差異が実際よりも誇張されて評価される可能性がある。…
核心:何を提案したのか
本研究は、LLMの生成出力における分散を包括的かつ大規模に区分することを提案し、出力の質(独創性)と量(流暢性)のそれぞれについて要因を特定した。具体的には、12種類のLLMに対して10種類の異なるプロンプト戦略を適用し、各組み合わせについて100回の独立したサンプリングを行うことで、合計12,000件のデータを収集した。評価の対象には、日用品の新しい用途を考案する「代替用途タスク(AUT)」を採用し、自動化された評価パイプラインを用いて独創性スコアとアイデアの数を測定している。分析手法としては線形混合効果モデルを用い、全分散をモデル間の差異、プロンプト間の差異、モデルとプロンプトの相互作用、そしてモデル内部のサンプリングによる誤差の4つの構成要素に分解した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related