デノイジングの視点から拡散モデルの記憶を制御する手法の提案
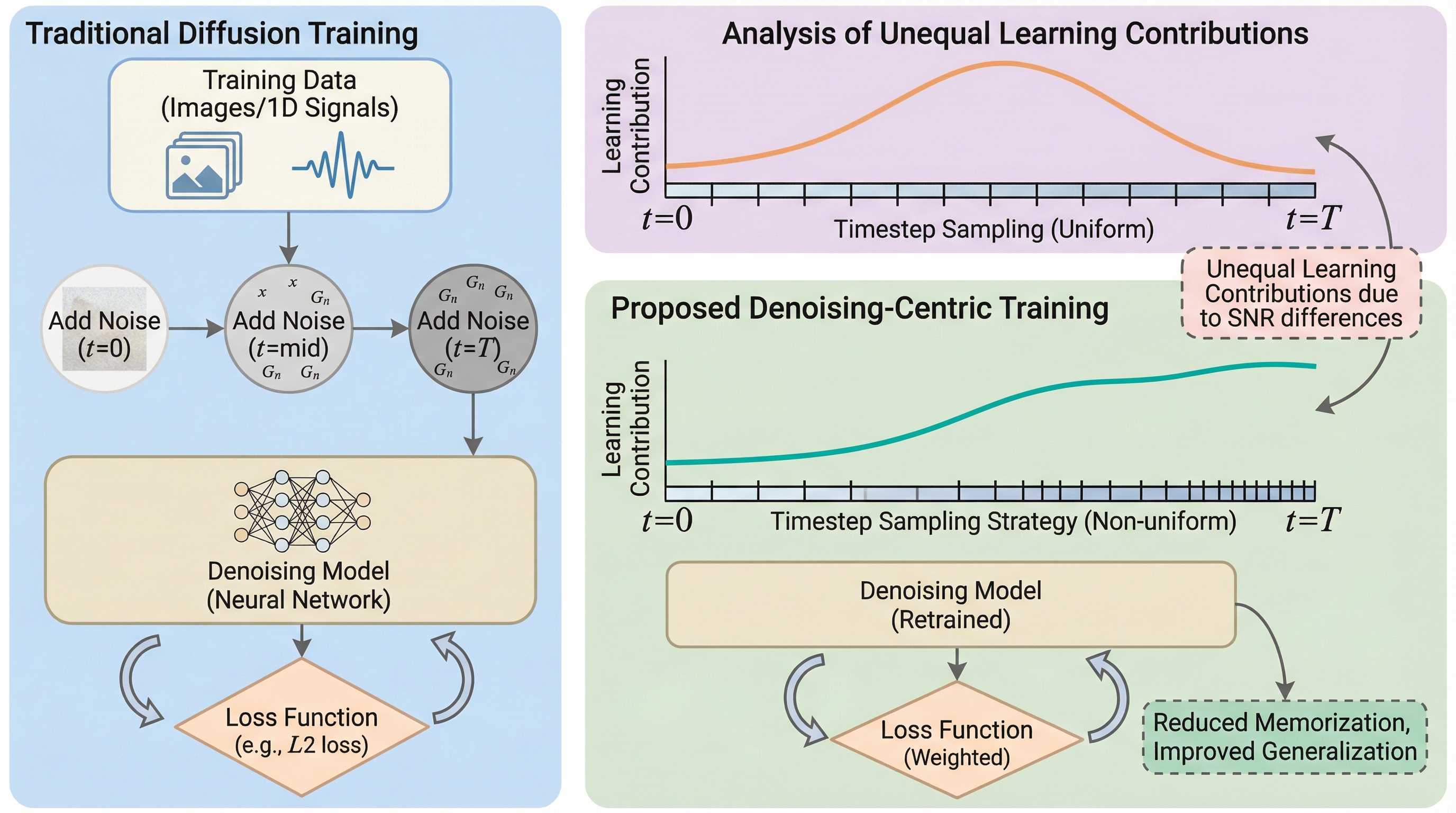
拡散モデルの学習において、タイムステップを一様にサンプリングすると信号対雑音比(SNR)の変動により学習の寄与が不均衡になり、特定の訓練データを過度に再現する「記憶」が生じる問題を、デノイジングの動態を重視する視点から解明した。
TL;DR(結論)
拡散モデルの学習において、タイムステップを一様にサンプリングすると信号対雑音比(SNR)の変動により学習の寄与が不均衡になり、特定の訓練データを過度に再現する「記憶」が生じる問題を、デノイジングの動態を重視する視点から解明した。 この課題に対し、タイムステップのサンプリングを正規分布に基づき制御する手法を提案し、信頼区間を設定することで学習の重点をデノイジングの後期段階へシフトさせ、モデルの記憶と汎化のトレードオフを直接的かつ直感的に調整することを可能にした。 画像および1次元信号生成タスクでの検証により、学習の重点をデノイジングの後期に移動させることで、ワッサースタイン距離などの指標が最大94%改善し、生成データの分布が訓練データの真の統計的性質と高度に整合し、記憶が効果的に抑制されることが実証された。
なぜこの問題か
拡散モデルは、画像生成や編集の分野で目覚ましい成果を上げているだけでなく、科学研究や産業分野におけるデータ拡張など、ドメイン固有の高度なタスクにも広く採用されるようになっている。しかし、これらの実用的な用途においては、生成されたサンプルが訓練データの統計的な分布に厳密に従うことが強く求められる。芸術的な画像生成とは異なり、科学的シミュレーションや医療データの拡張といった文脈では、モデルによる過度な創造性や「もっともらしいが架空のデータ」の生成は、分析結果を歪める有害な要素となり得る。そのため、モデルが訓練データをどの程度「記憶」し、どの程度「汎化」するかを精密に制御する能力は、モデルの信頼性を担保する上で極めて重要な課題となっている。 先行研究によれば、拡散モデルのサンプリングプロセスは「汎化領域」と「記憶領域」の2つに大別できることが示されている。ノイズレベルが高い初期段階(タイムステップ $t$ が大きい状態)では、データの全体的な分布レベルの特徴が形成されるが、出力に近い後期段階($t$ が小さい状態)では、具体的な細部や構造が導入される。…
核心:何を提案したのか
本論文の核心的な提案は、拡散モデルの記憶を制御するために、デノイジング中心の視点からタイムステップのサンプリング戦略を動的に調整する新しい枠組みを構築したことにある。従来の均一なサンプリング手法に代わり、タイムステップ $t$ を正規分布 $N(\mu, \sigma^2)$ からサンプリングすることで、デノイジングの軌跡に沿って「どこで重点的に学習を行うか」を明示的に制御する。この手法の狙いは、モデルの学習動作を汎化領域と記憶領域の間で一律に促進するのではなく、より学習が困難でドリフトが生じやすい領域に焦点を当てることで、生成プロセスが外挿領域へ逸脱するのを防ぐことにある。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related