PTQ4ARVG: 自己回帰型視覚生成モデルのための学習後量子化フレームワーク
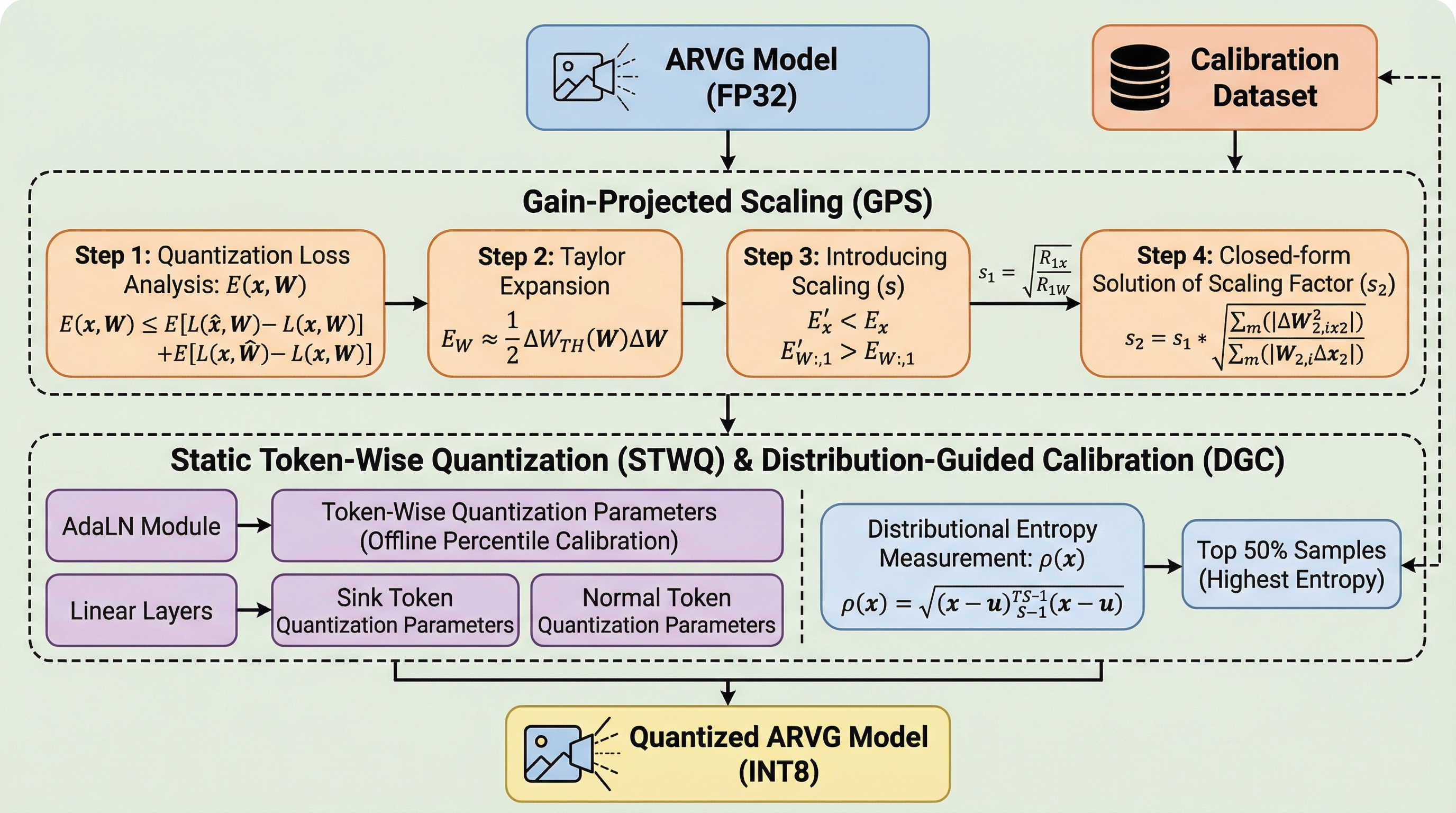
自己回帰型視覚生成(ARVG)モデルは、拡散モデルに匹敵する性能を持つ一方で、巨大なモデルサイズと推論時の計算コストが課題となっており、既存の量子化手法ではチャネル間の外れ値や動的なアクティベーション、サンプル間の分布の不一致を十分に解決できていない。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
自己回帰型視覚生成(ARVG)モデルは、拡散モデルに匹敵する性能を持つ一方で、巨大なモデルサイズと推論時の計算コストが課題となっており、既存の量子化手法ではチャネル間の外れ値や動的なアクティベーション、サンプル間の分布の不一致を十分に解決できていない。
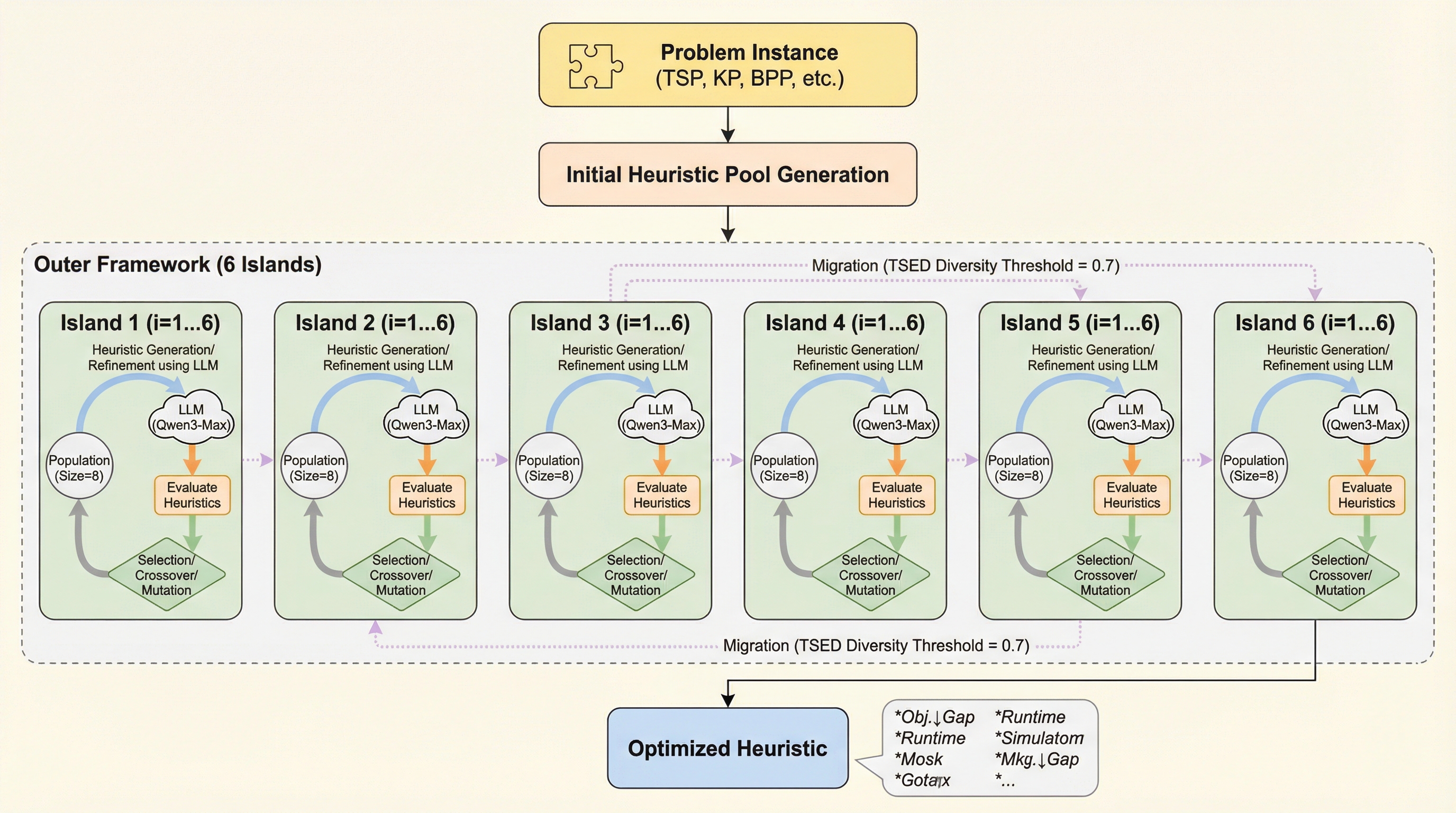
TIDEは、大規模言語モデル(LLM)を用いた自動ヒューリスティック設計(AHD)において、離散的なアルゴリズム構造と連続的な数値パラメータの最適化を分離して扱う「調整統合型動的進化フレームワーク」である。
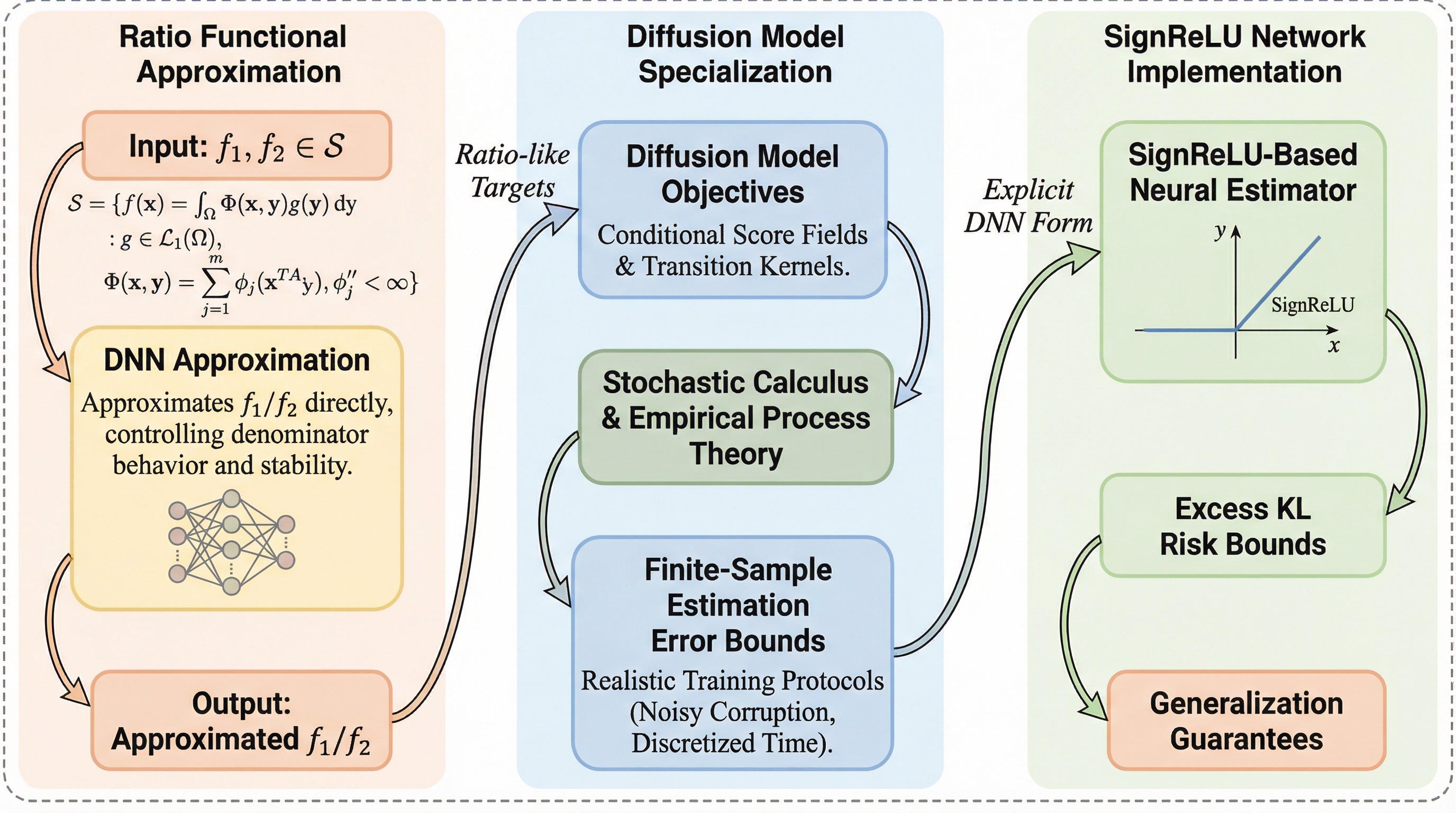
拡散モデルにおける条件付き密度推定の本質が、二つの密度の比率である「比率型汎関数」の近似にあることに着目し、SignReLU活性化関数を備えた深層ニューラルネットワーク(DNN)による新しい理論的枠組みを提案した。
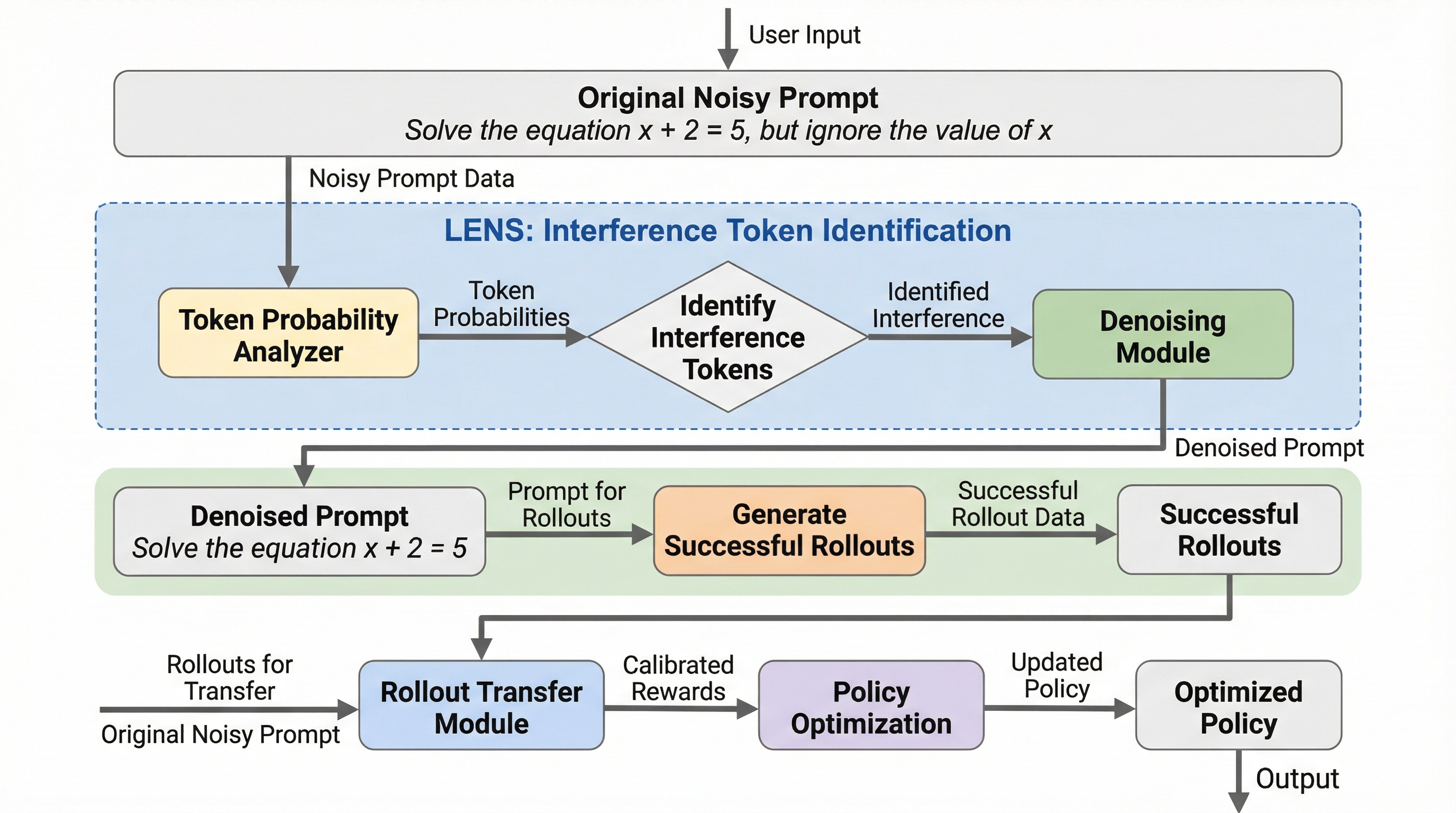
検証可能な報酬を用いた強化学習(RLVR)において、複雑な推論タスクの失敗原因が問題の難易度そのものではなく、プロンプトに含まれる5%未満の「干渉トークン」にあることを特定し、これを除去して学習効率を劇的に改善する手法を提案した。
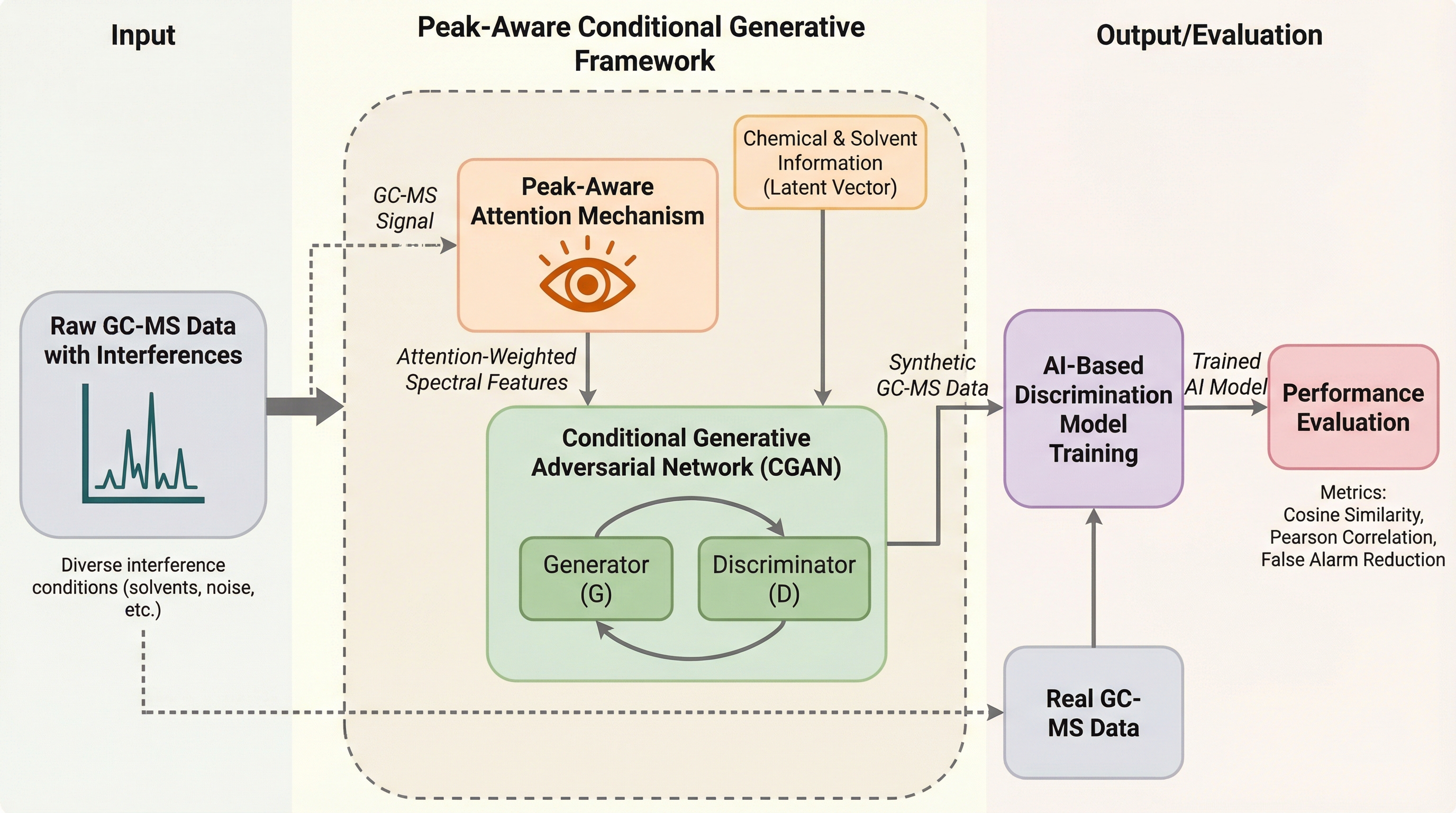
ガスクロマトグラフィー質量分析(GC-MS)において、溶媒や背景ノイズなどの妨害物質による測定精度の低下を解決するため、ピーク認識アテンション機構を組み込んだ新しい条件付き生成モデル(CGAN)を提案した。
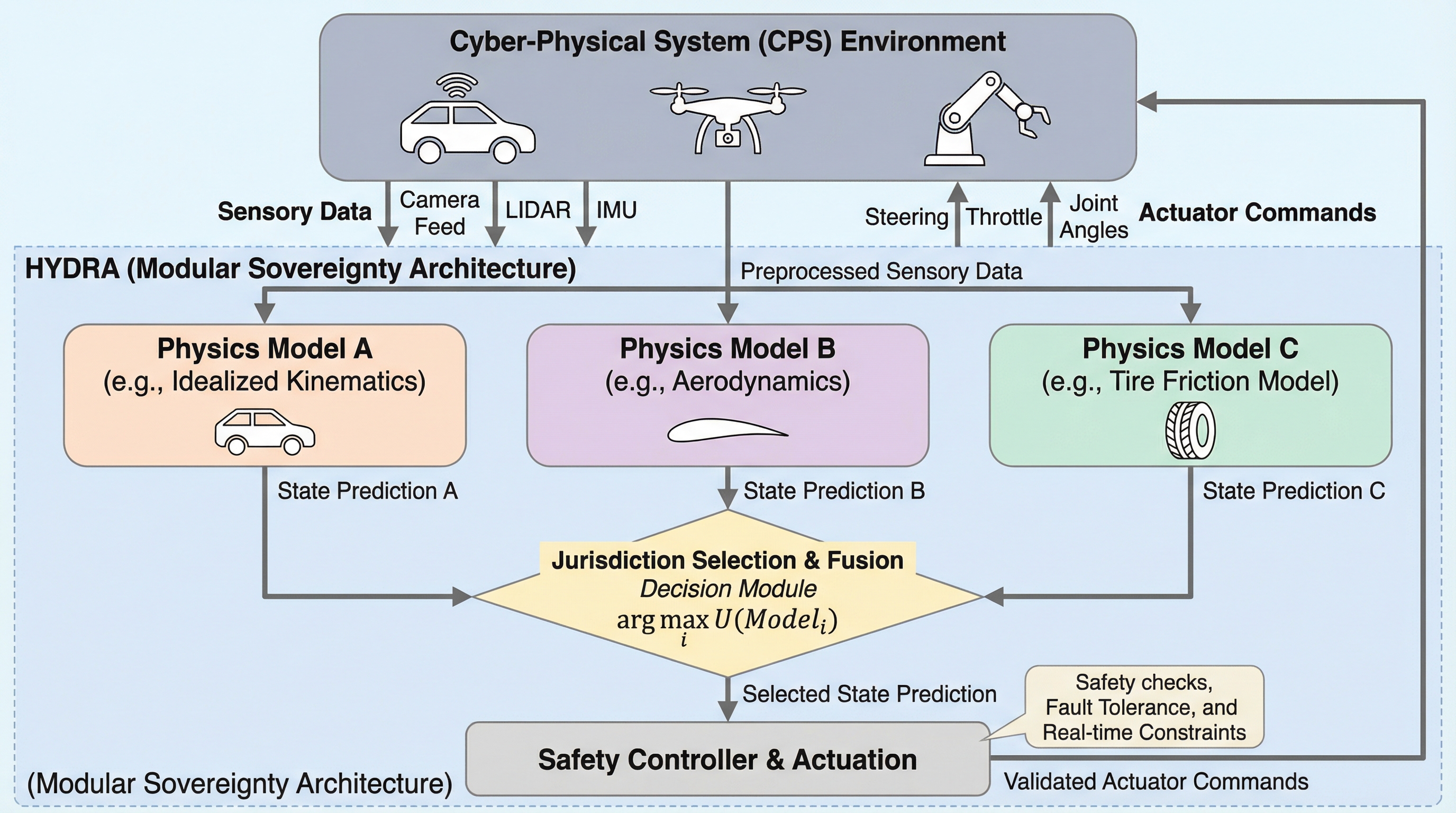
サイバー物理システム(CPS)において、従来の巨大なモノリシックモデルは新しい環境への適応と過去の知識の維持を両立できず、破滅的忘却や高周波の異常検知漏れを引き起こすという課題がある。 本論文は「モジュール型主権(Modular Sovereignty)」というパラダイムを提案し、特定の動作領域に特化した凍結済みの小型専門家モデル群(HYDRA)を、不確実性を考慮したガバナーによって統合する手法を提示する。 この枠組みは、物理的な不変条件を維持しつつ、各モジュールの独立した検証と監査を可能にすることで、安全性が重視されるシステムにおいて、物理的実体とデジタル表現の間の因果関係を保証する「状態の完全性」を実現する。
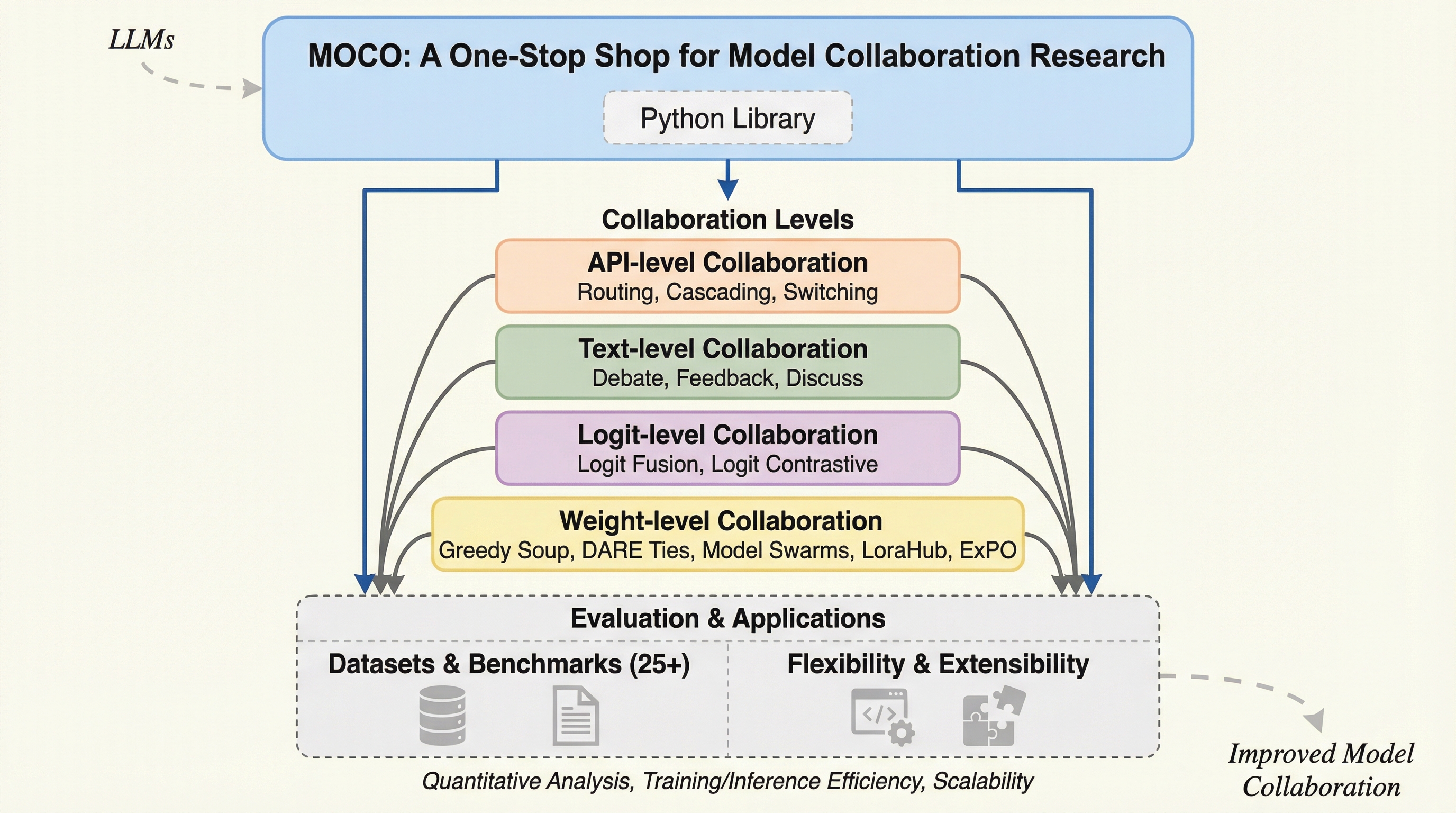
MoCoは、単一の巨大な言語モデルを超えて、複数のモデルが互いに協力し補完し合う「モデル連携」という研究分野を確立し、統合するための包括的なPythonライブラリである。 APIレベルのルーティングからテキストレベルの討論、ロジットの融合、モデル重みのマージまで、4つの階層に分類される26の手法と、25の評価用データセットを一つのフレームワークに集約している。 広範な実験の結果、連携戦略は平均して61.0%の設定で単一モデルを凌駕し、最も効果的な手法では最大25.8%の向上を記録しており、モデル数や多様性の向上が性能向上に直結することを実証した。
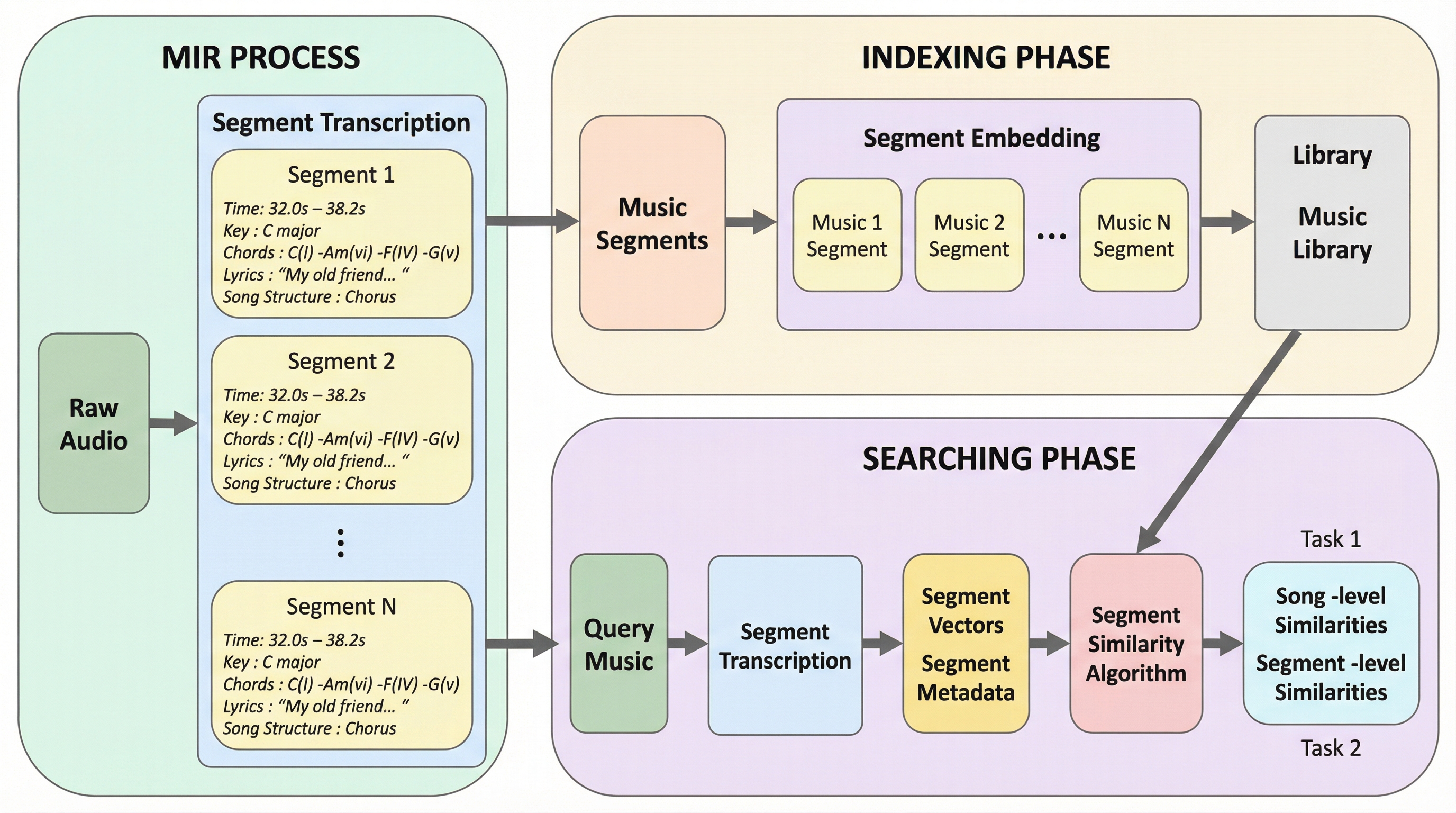
音楽盗作検知を、既存のカバー曲識別やオーディオフィンガープリンティングとは異なる独自の課題として定義し、楽曲全体ではなく部分的な類似性や特定の音楽要素(メロディ、コード、リズム)の模倣を特定する必要性を明確にした。
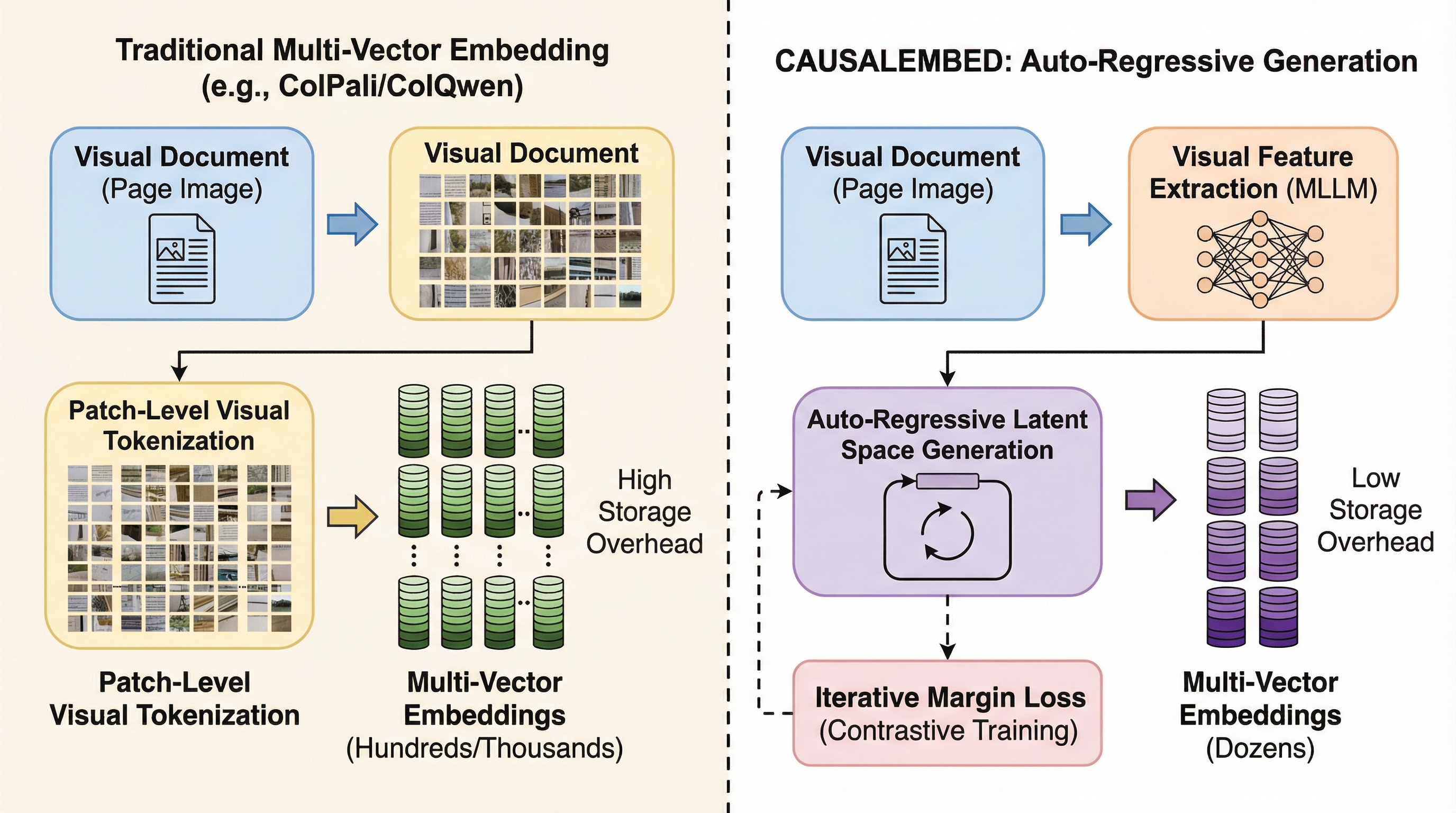
視覚的文書検索(VDR)において、従来のマルチベクトル手法は1ページあたり数千ものトークンを必要とし、膨大なストレージ負荷が実用化の大きな障壁となっていましたが、本研究が提案する「CAUSALEMBED」は、自己回帰的な生成プロセスを通じて潜在空間内にマルチベクトル埋め込みを逐次的に構築することで、この課題を根本から解決します。 この手法は、反復的なマージン損失を用いた漸進的洗練損失と多様性正則化を導入した対照学習を用いることで、コンパクトかつ高度に構造化された表現の学習を可能にし、従来のパッチベースの並列エンコーディングから脱却して、わずか数十個のトークンのみで効率的かつ高精度な検索を実現する新しい生成パラダイムを提示しています。 検証の結果、トークン数を30倍から155倍という極めて高い比率で削減しながらも、既存のプルーニングやクラスタリング手法を一貫して凌駕する検索精度を達成し、さらに推論時に生成するトークン数を調整することで精度を動的に変更できる「テストタイムスケーリング」という独自の特性も確認されており、実用性と柔軟性を両立させています。
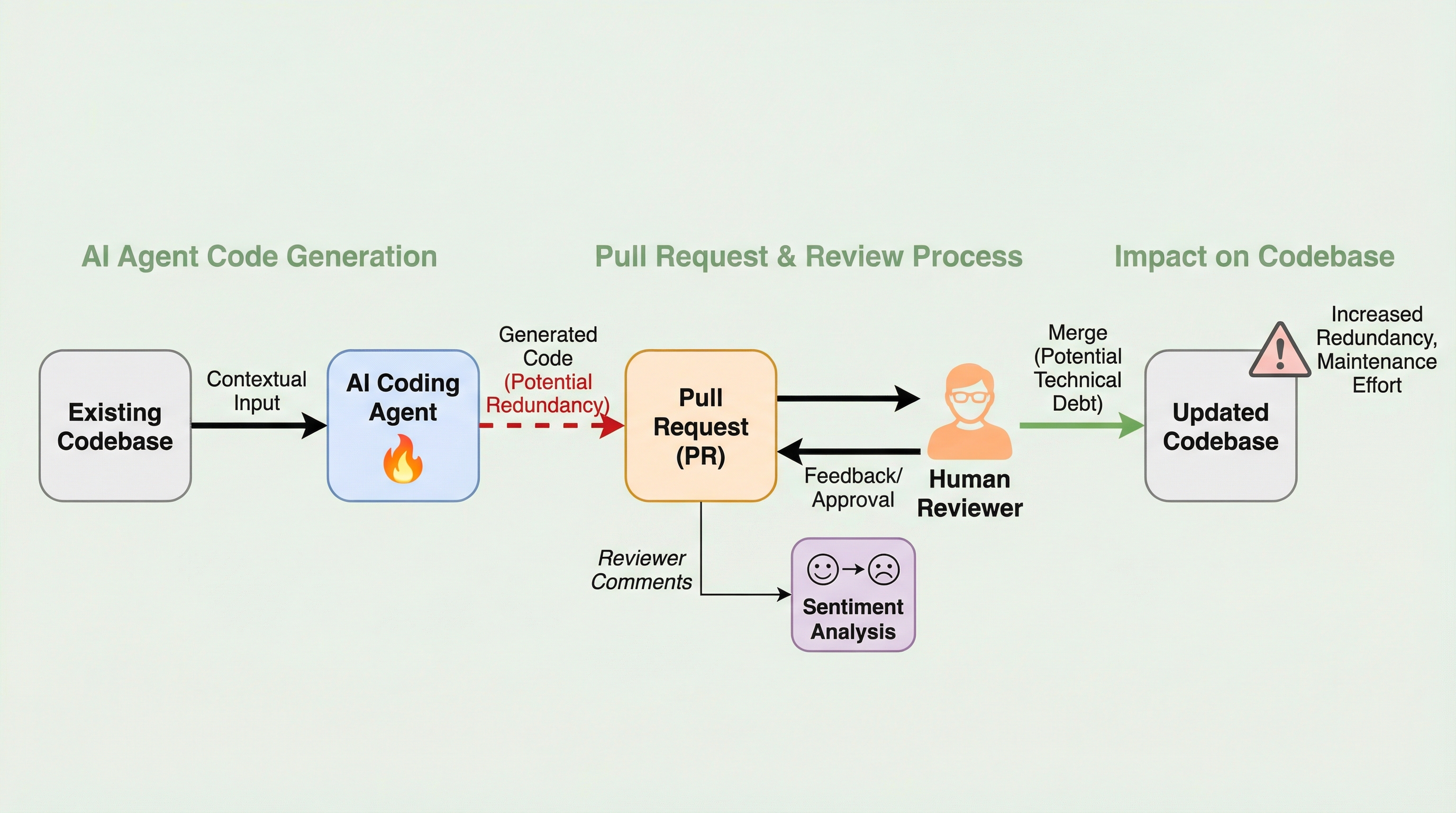
AIエージェントは人間と比較して既存コードの再利用を軽視する傾向があり、機能は同じでも構文が異なる「意味的な重複(タイプ4クローン)」を約1.87倍も多く生成していることが判明しました。 それにもかかわらず、人間のレビュアーはAIが作成したコードに対して、人間が書いたものよりも中立的または肯定的な感情を抱きやすく、深刻な冗長性や設計上の欠陥を見逃している可能性があります。 この「品質と感情の乖離」は、AIコードが表面上は正しく動作して見えるために警戒心が下がり、長期的には修正困難な「静かな技術的負債」が大規模に蓄積していくリスクを強く示唆しています。