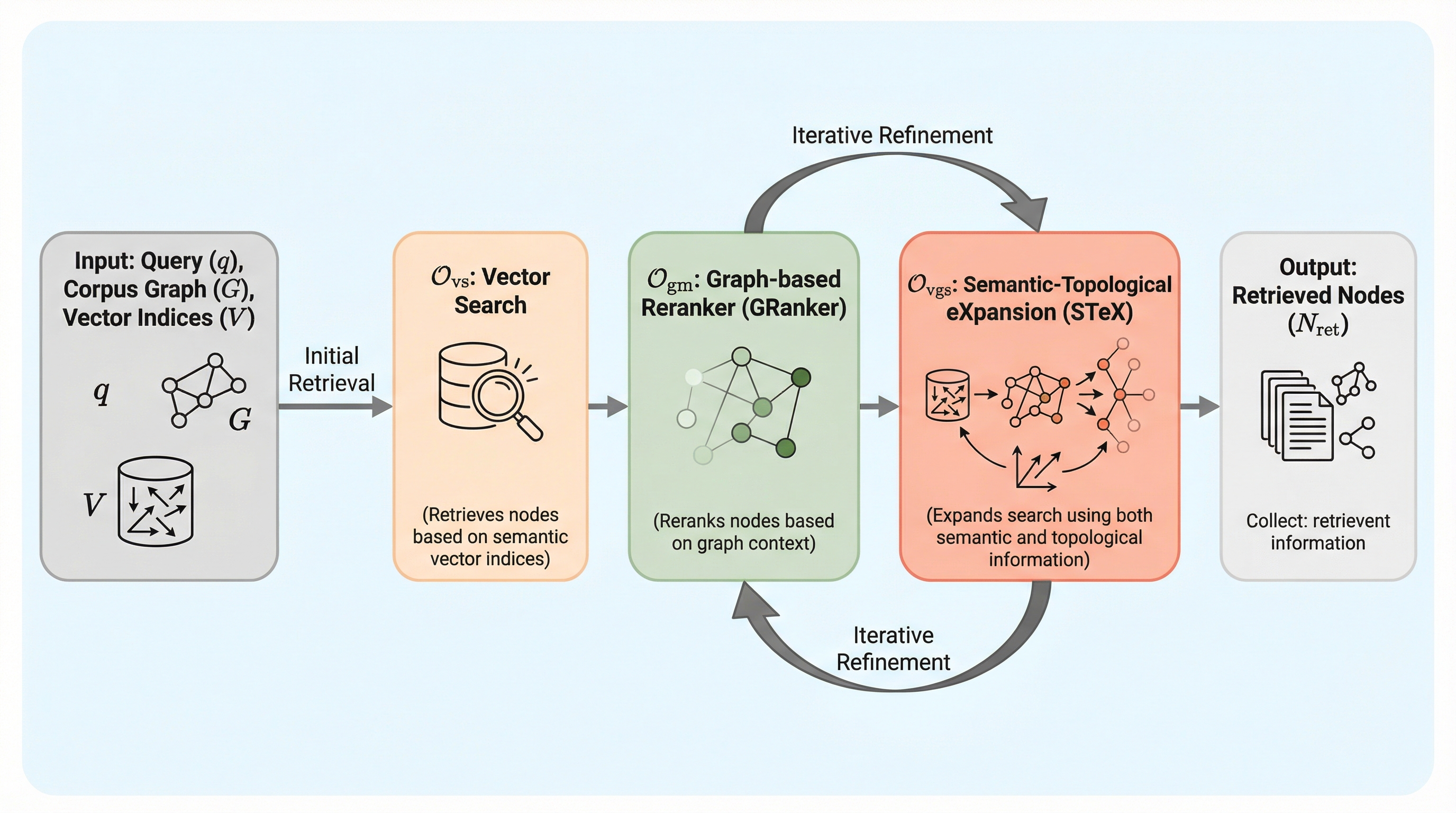
イグボ語の発音記号復元に対するコーパスベースのアプローチ
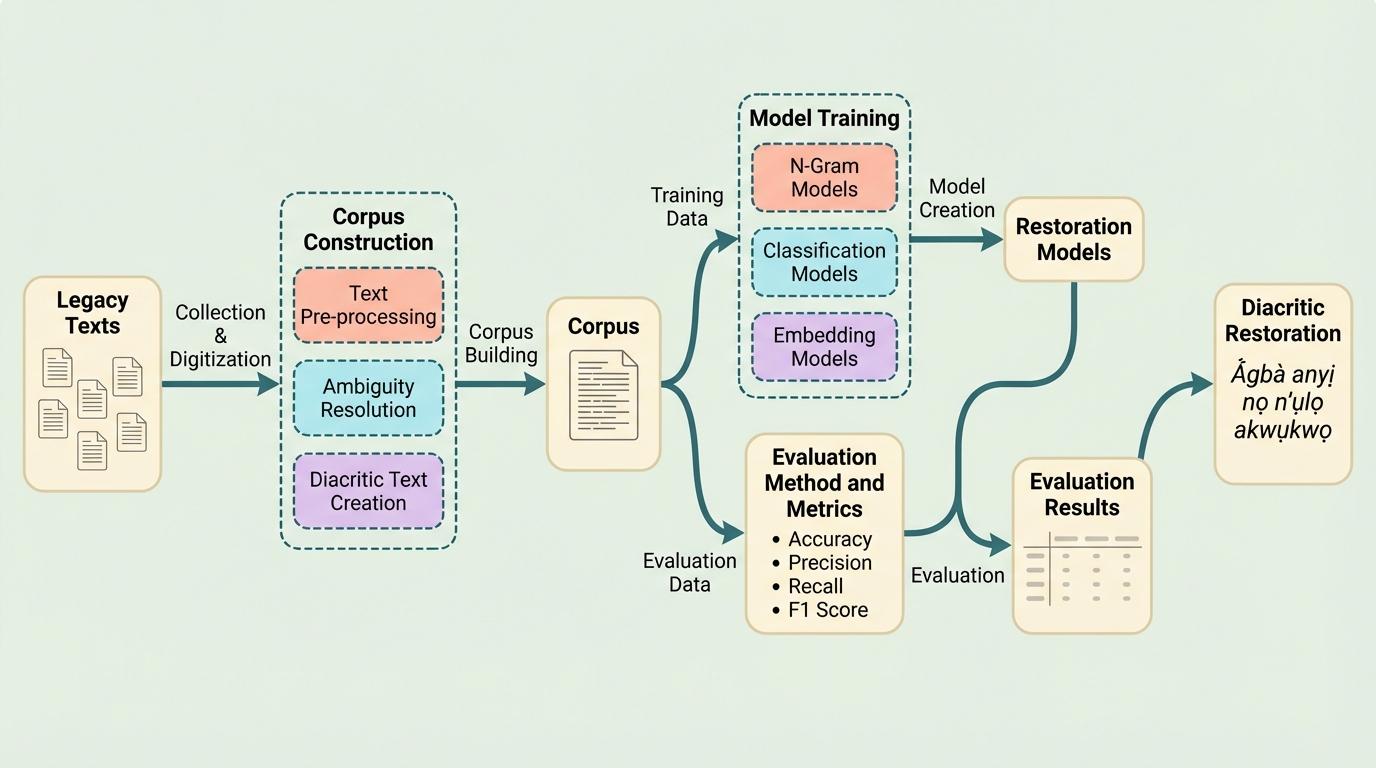
イグボ語は自然言語処理のリソースが極めて乏しい言語であり、デジタルテキストにおいて意味や声を区別する発音記号が省略されることで生じる深刻な曖昧性が、言語理解の大きな障壁となっている。本研究では、この問題を解決するために、n-gramモデル、機械学習による分類モデル、および他言語からの投影を利用した単語埋め込みモデルという3つの主要な技術的アプローチを提案し、データセット生成のための柔軟なフレームワークを構築した。検証の結果、提案されたすべての手法が単語の出現頻度のみに基づく基準値を大幅に上回る精度を記録し、特に文脈情報を活用する手法が、検索エンジンや機械翻訳などの言語インフラを改善する上で極めて有効であることを実証した。