Cog AI Archive
最新の記事
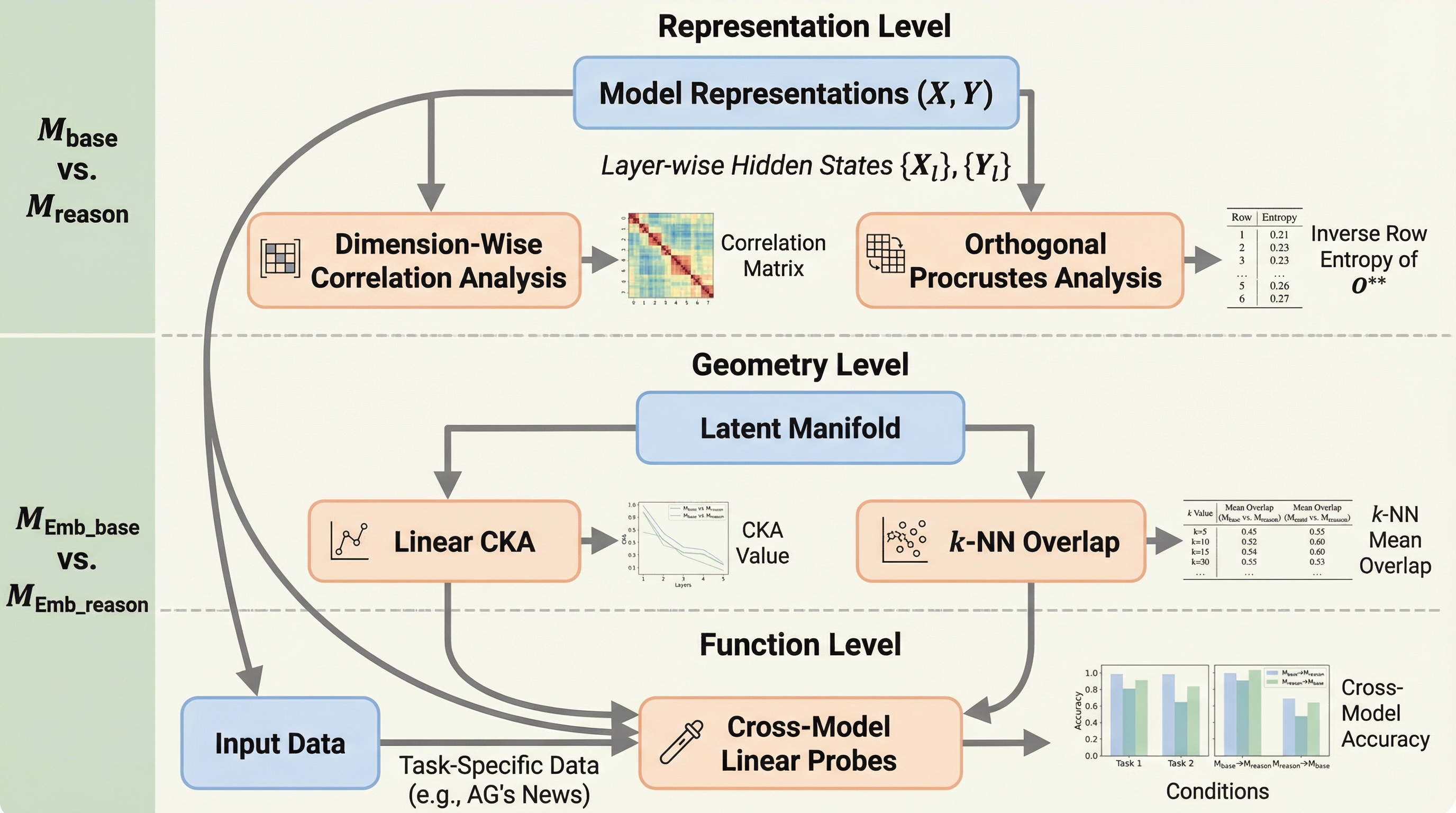
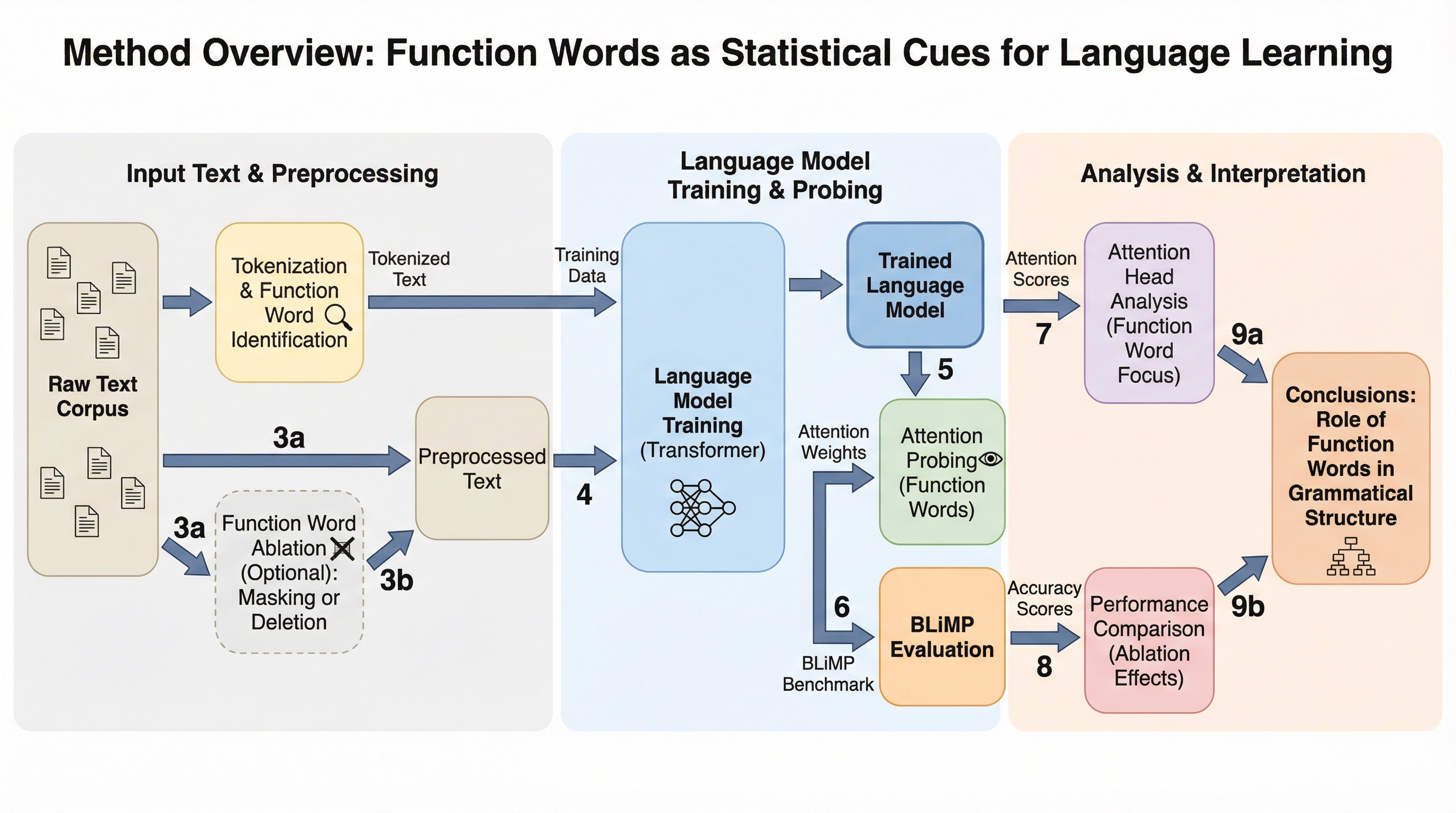
推論モデルは埋め込みモデルを強化するのか?
検証可能な報酬を用いた強化学習(RLVR)で訓練された推論モデルを初期値として用いても、埋め込みモデルの性能はベースモデルと比較して統計的に有意な向上を示さない「無効果(Null Effect)」が確認された。
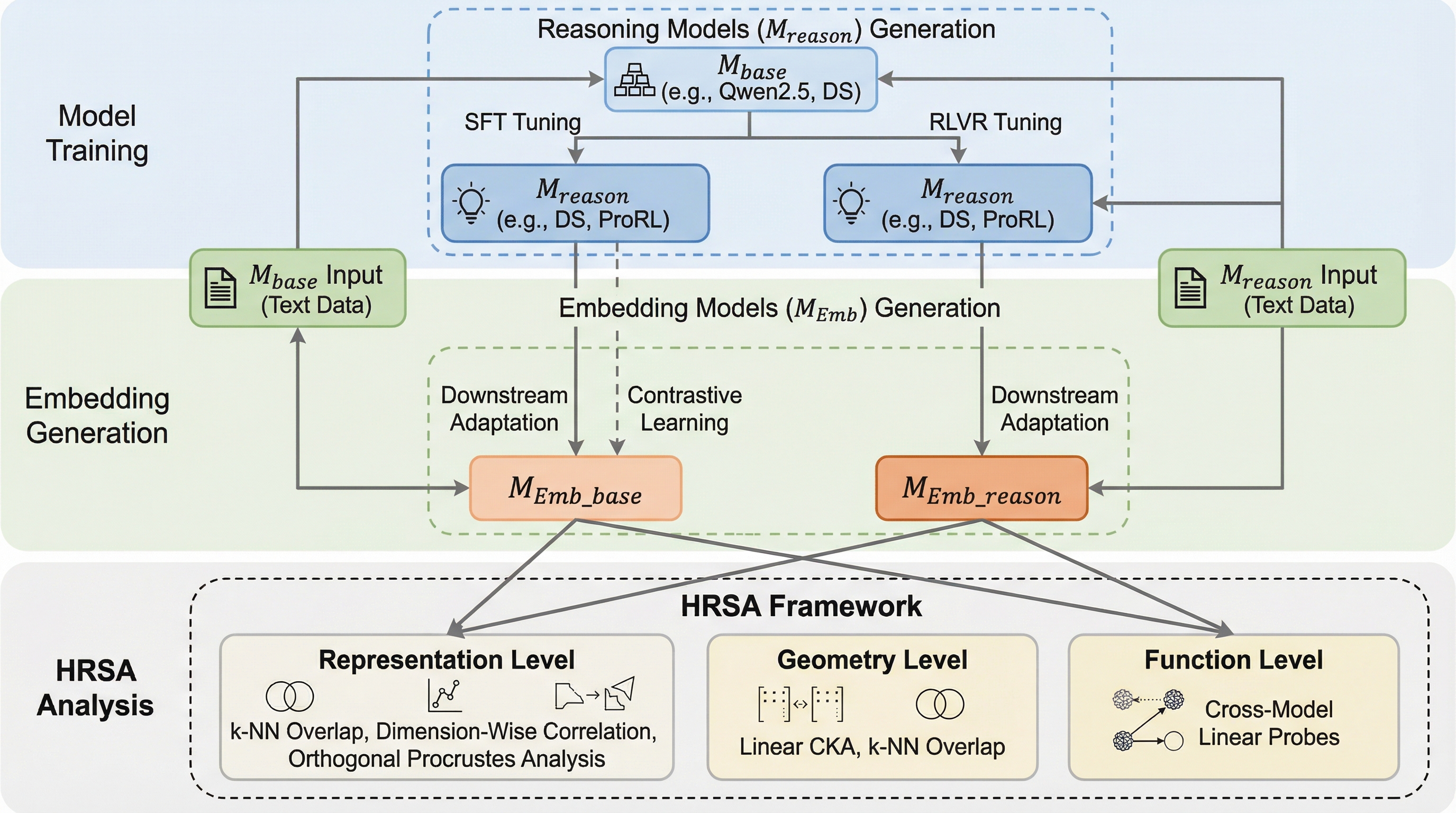
推論モデルは埋め込みモデルを強化するのか?
RLVR(検証可能な報酬による強化学習)で最適化された推論モデルを基盤としても、テキスト埋め込みモデルの性能はベースモデルと比較して向上しないという「ゼロ効果」が、MTEBやBRIGHTなどの主要なベンチマーク評価によって明らかになりました。
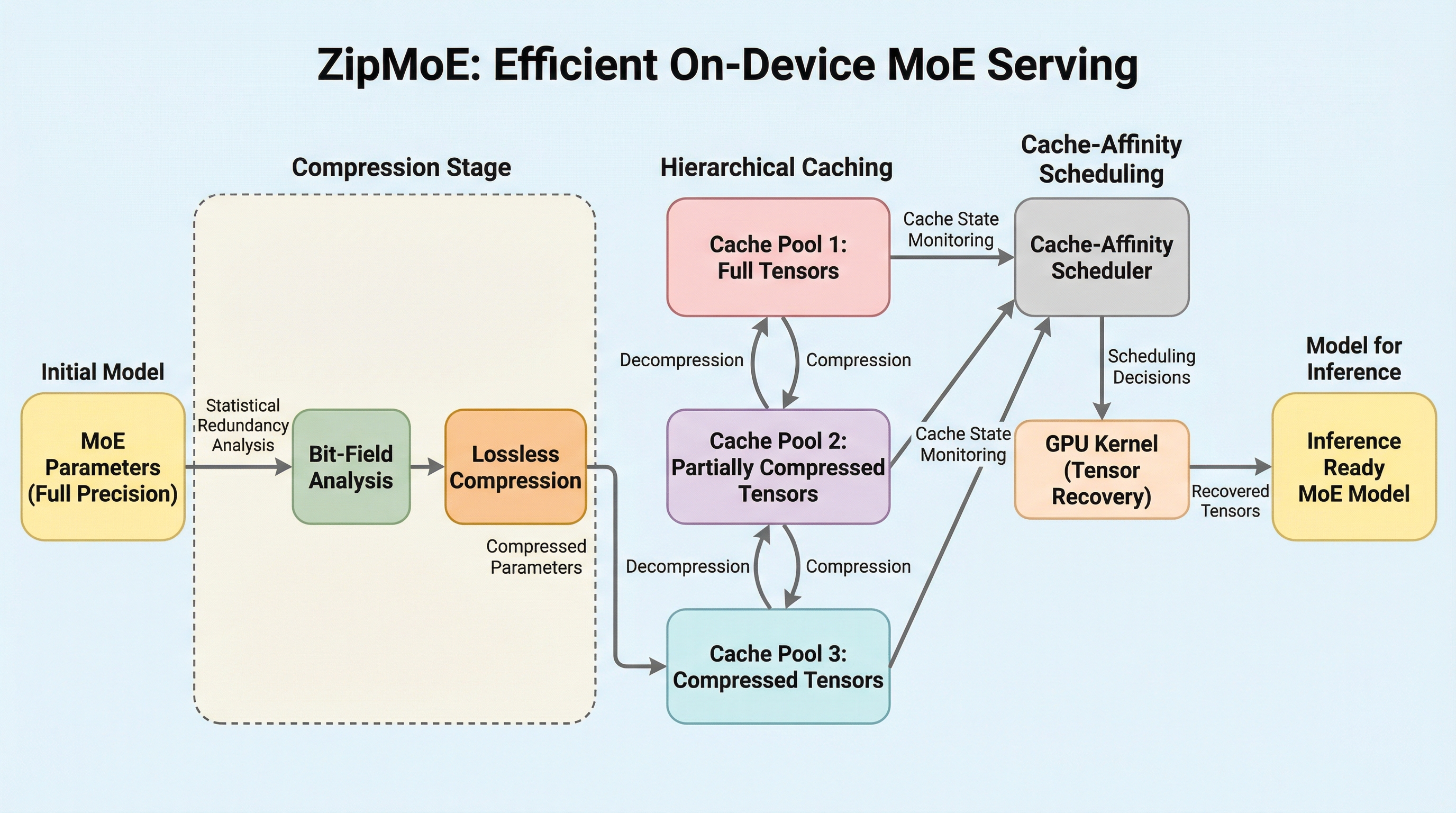
ZipMoE: 無損失圧縮とキャッシュアフィニティ・スケジューリングによる効率的なオンデバイスMoEサービング
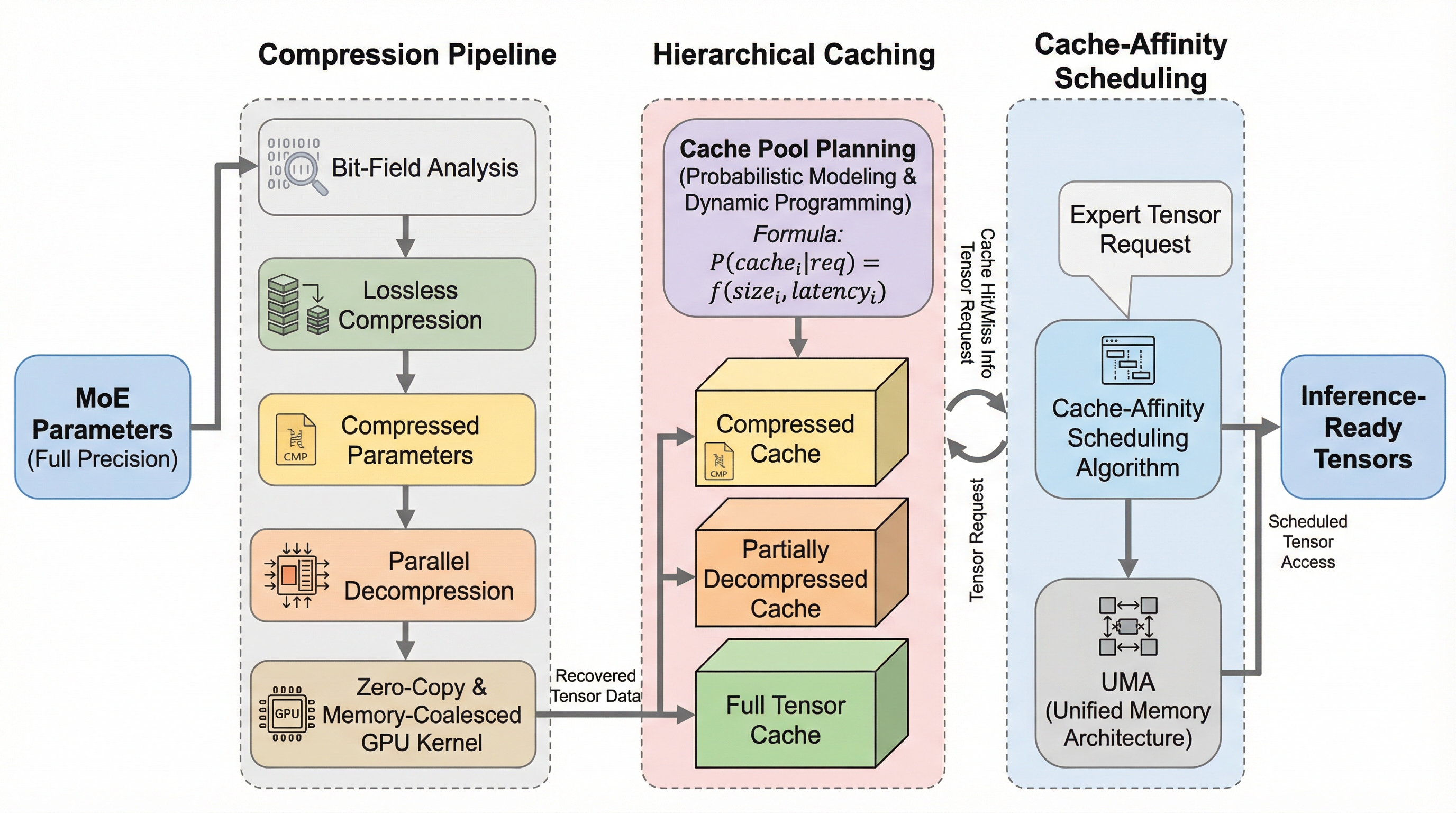
ZipMoEは、メモリ制約の厳しいエッジデバイスにおいて、Mixture-of-Experts(MoE)モデルを精度劣化なく高速に実行するための革新的な推論システムです。BF16形式のパラメータに含まれる統計的な冗長性を利用した無損失圧縮技術と、マルチコアCPUによる並列展開を組み合わせることで、従来のI/Oボトルネックを計算中心のワークフローへと劇的に転換しました。NVIDIA Jetson AGX Orinを用いた広範な検証では、最新の既存システムと比較して推論遅延を最大72.77%削減し、スループットを最大6.76倍向上させるという圧倒的な性能向上を達成しており、プライバシーと精度が求められるオンデバイスAIの新たな可能性を切り拓いています。
ZipMoE: 無損失圧縮とキャッシュアフィニティ・スケジューリングによる効率的なオンデバイスMoEサービング
巨大なメモリを必要とするMixture-of-Experts(MoE)モデルを、エッジデバイスの限られたリソースで効率的に動作させるための推論エンジン「ZipMoE」が提案されました。 モデルの精度を損なう量子化に頼らず、BF16形式の指数ビットに含まれる統計的冗長性を活用した無損失圧縮と、CPUとGPUがメモリを共有するアーキテクチャに最適化した並列処理を導入しています。 実機検証では、既存の最新システムと比較して推論の遅延を最大72.77%削減し、スループットを最大6.76倍に向上させるという、極めて高いパフォーマンス改善を達成しました。
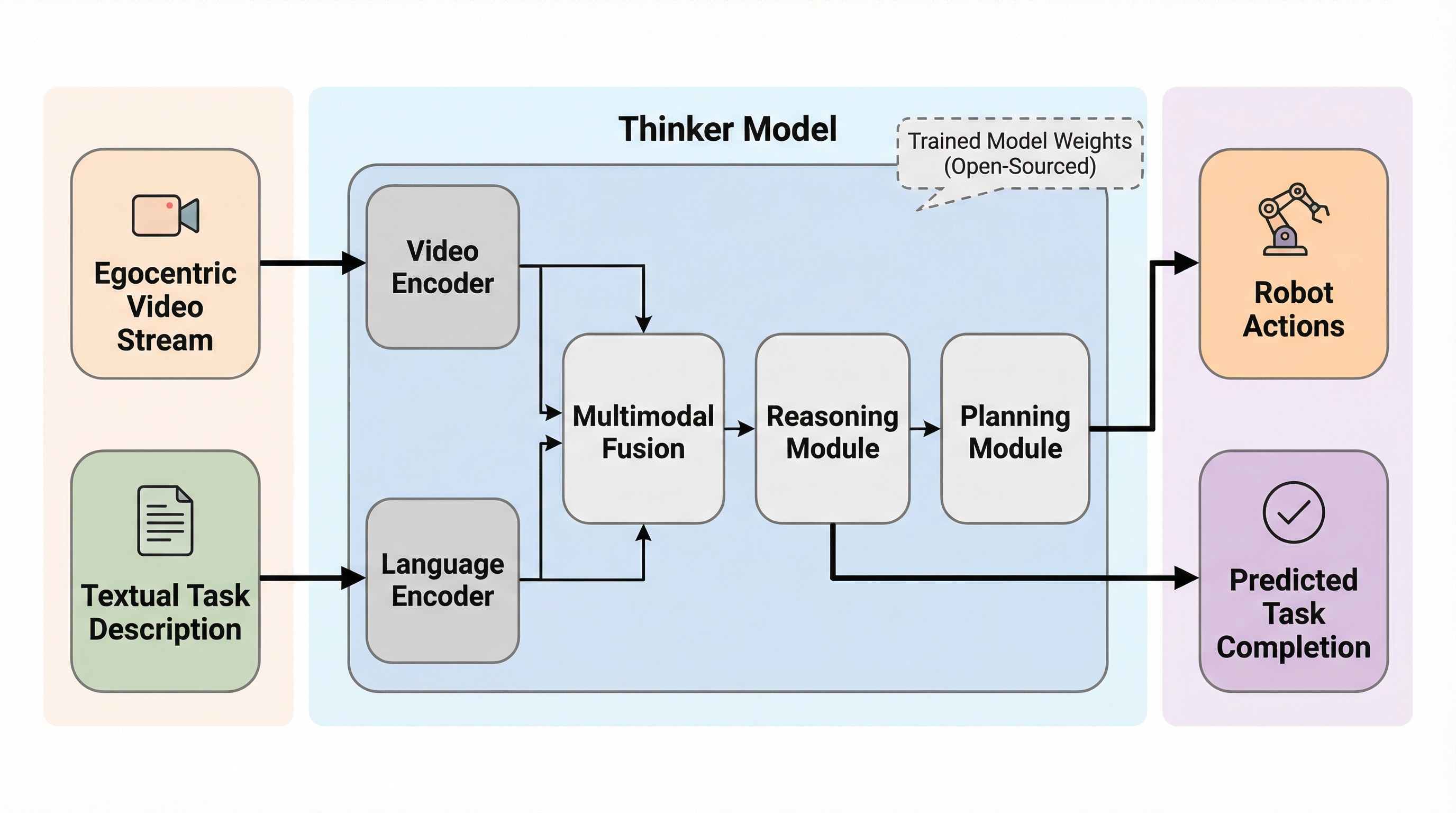
Thinker:身体的知能のための視覚言語基盤モデル
Thinkerは、ロボット工学における視覚と言語の統合を目的とした100億パラメータ規模の基盤モデルであり、従来のモデルが抱えていた三人称視点と一人称視点の混同や、ビデオ終盤情報の見落としといった課題を解決するために開発されました。
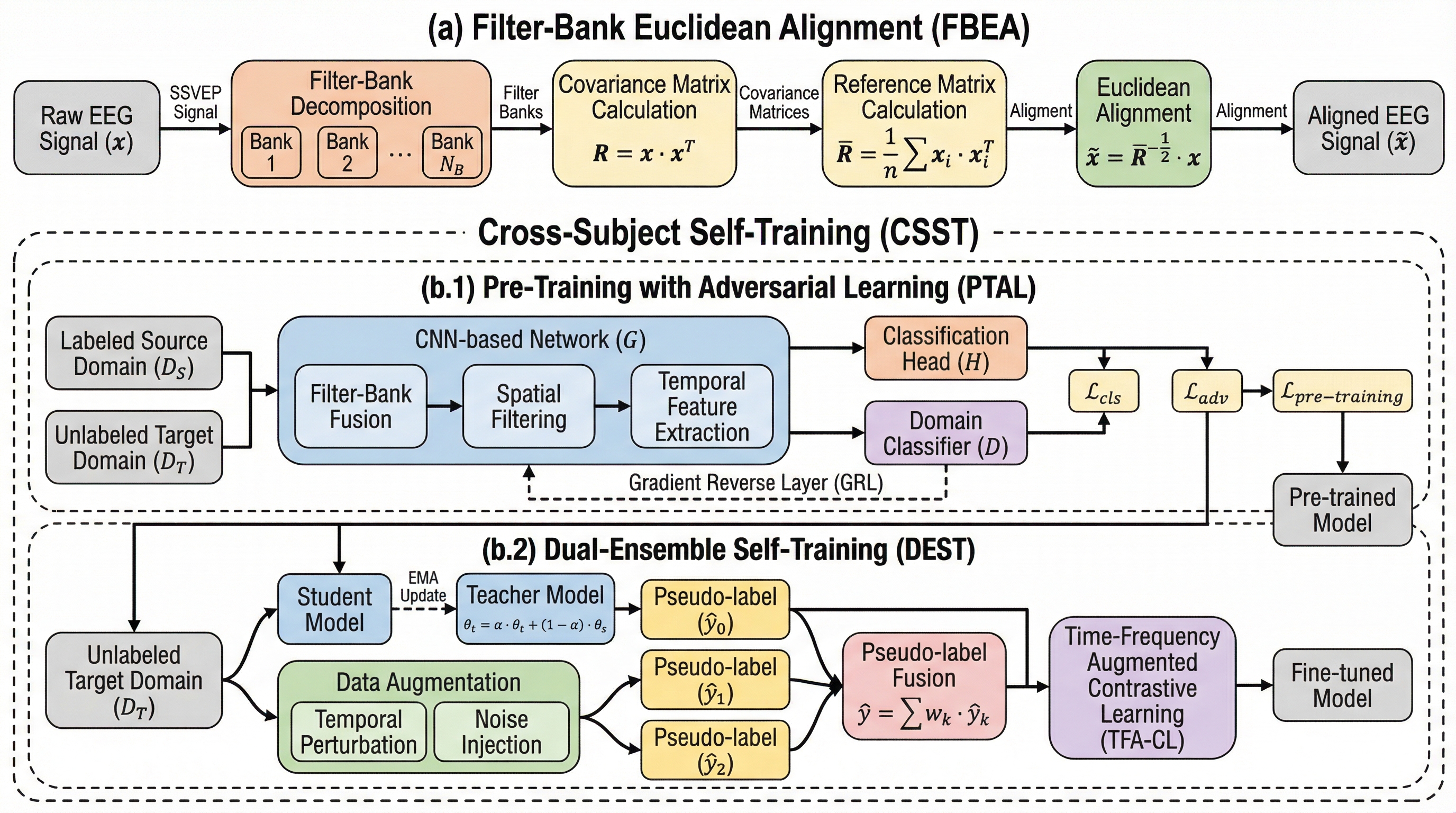
SSVEP分類のための自己学習に基づく被験者間ドメイン適応の再考
定常状態視覚誘発電位(SSVEP)を用いた脳コンピュータインターフェース(BCI)において、被験者間の信号変動とラベル付けの負担を解消するため、フィルタバンク情報を活用したユークリッド整列(FBEA)と、敵対的学習およびデュアルアンサンブルを統合した自己学習フレームワーク(CSST)が提案された。
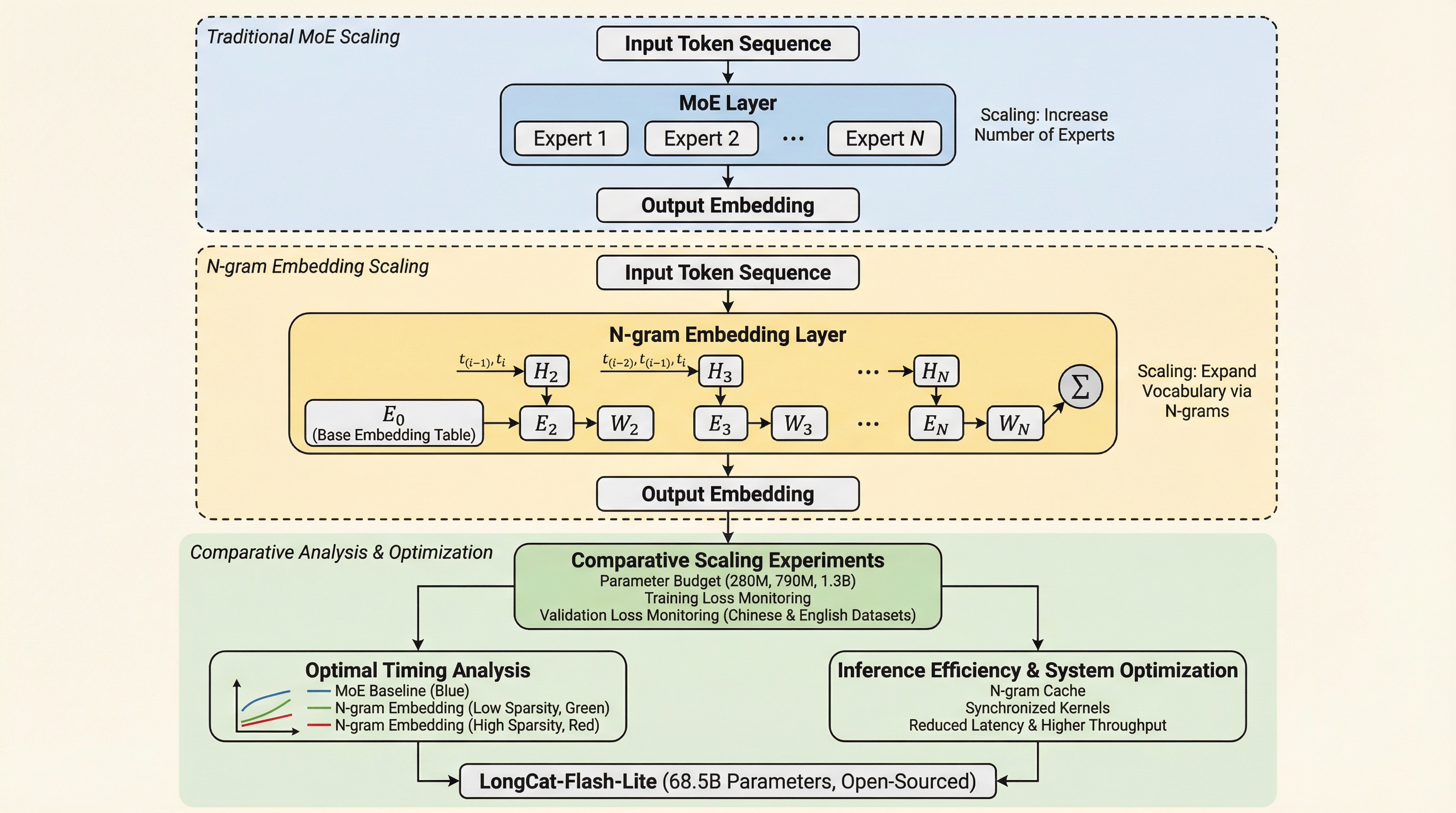
言語モデルにおけるエンベディングのスケーリングはエキスパートのスケーリングを凌駕する
大規模言語モデルの性能向上において主流であるMixture-of-Experts(MoE)は、計算効率の飽和やシステム上の通信負荷という課題に直面していますが、本研究は計算コストの極めて低いエンベディング層を拡張する「N-gram Embedding」が、特定の高スパース性条件下でエキスパートの増量よりも優れた性能対コスト比(パレート境界)を実現することを解明しました。 モデルの総パラメータの最大50%までをエンベディングに割り当て、ハッシュ衝突を回避するために語彙サイズをベース語彙の整数倍から意図的にずらすといった具体的な設計指針を提示し、これにより計算量を抑えつつモデルの表現力を大幅に強化できることを示しました。 この理論に基づき、685億パラメータを持ちながら推論時には約30億パラメータのみを活性化させる「LongCat-Flash-Lite」を開発し、同規模のMoEモデルを凌駕する性能を達成するとともに、特に複雑な推論が求められるエージェントタスクやコーディングの領域で既存のモデルに対して高い競争力を示しました。
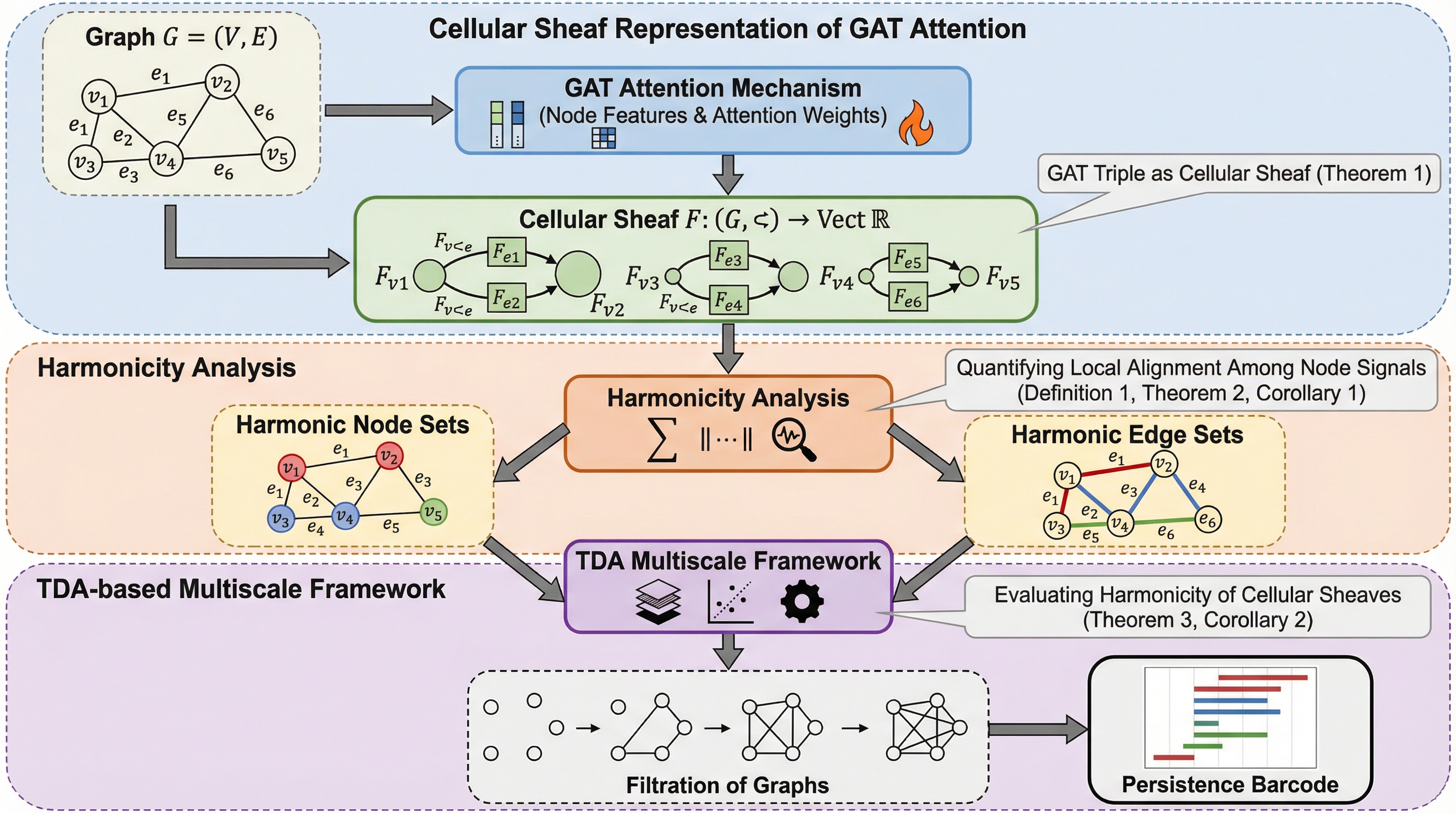
グラフニューラルモデルにおける複雑ネットワークモデリングと注意機構に関する層論的および位相幾何学的視点
グラフ注意ネットワーク(GAT)の注意機構を数学的な「細胞層(Cellular Sheaf)」として再定義し、学習された重みがグラフ上の信号の整合性をどのように規定するかを位相幾何学的に解釈する理論的枠組みを提案しました。
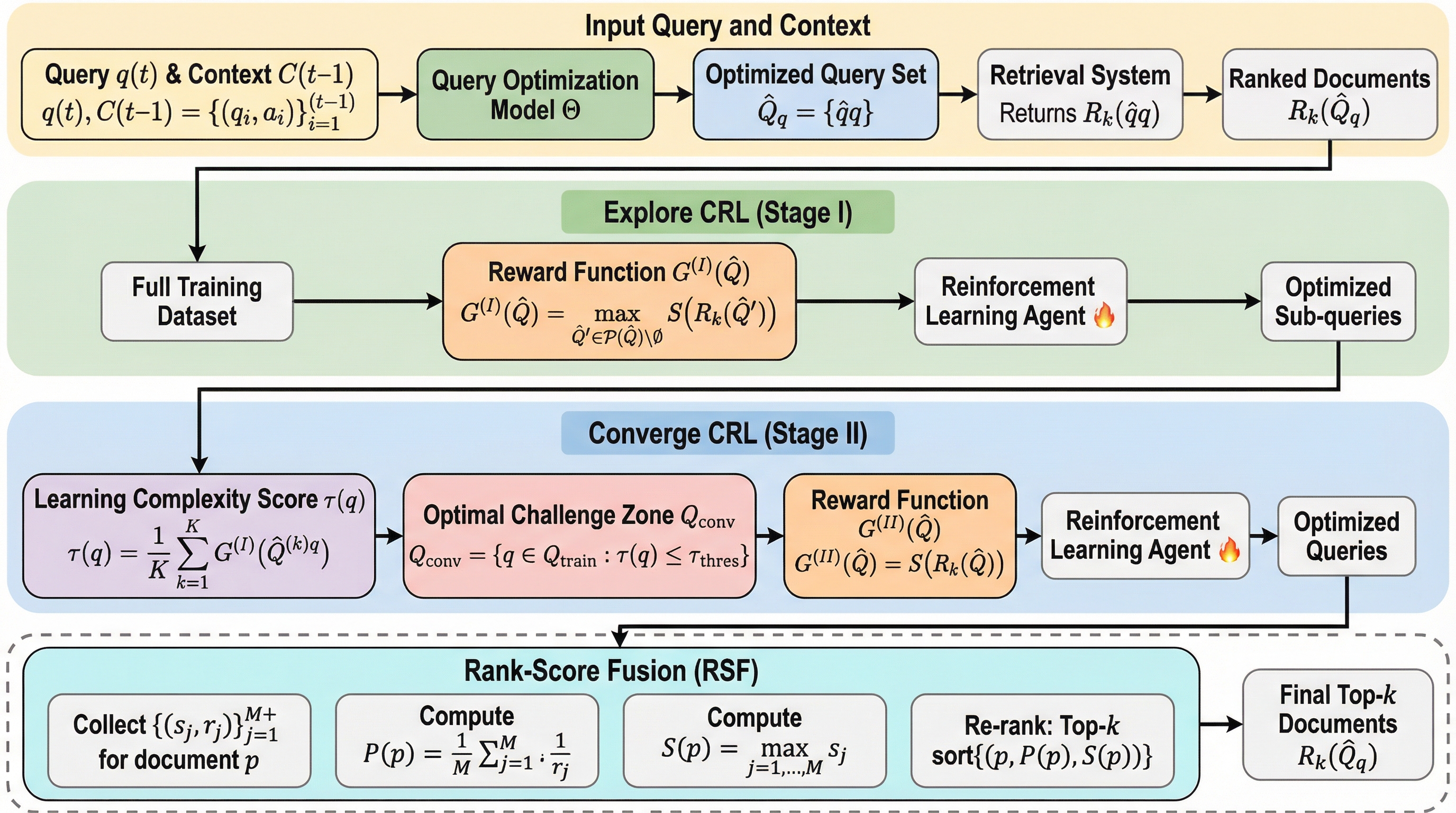
いつより多く探索すべきか:強化学習による適応的な複雑なクエリ最適化
検索拡張生成(RAG)において、複雑なユーザーの質問を適切に分解・明確化して検索精度を高めるための新しい強化学習フレームワーク「ACQO」が提案されました。従来の単一クエリの拡張手法とは異なり、クエリの複雑さに応じて適応的に検索プロセスを拡張するかどうかを判断し、複数のサブクエリを生成する仕組みを備えています。