Thinker:身体的知能のための視覚言語基盤モデル
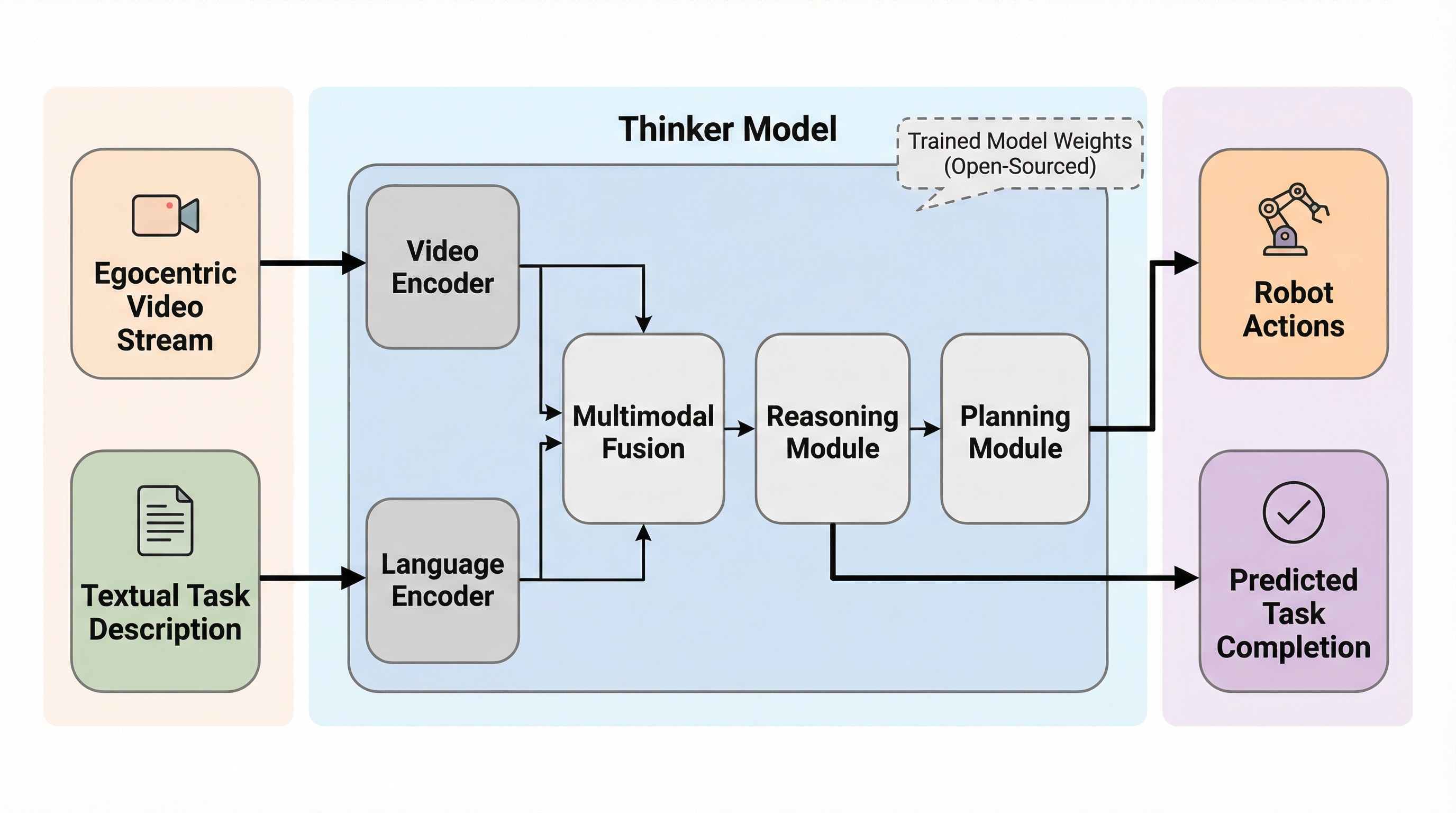
Thinkerは、ロボット工学における視覚と言語の統合を目的とした100億パラメータ規模の基盤モデルであり、従来のモデルが抱えていた三人称視点と一人称視点の混同や、ビデオ終盤情報の見落としといった課題を解決するために開発されました。
TL;DR(結論)
Thinkerは、ロボット工学における視覚と言語の統合を目的とした100億パラメータ規模の基盤モデルであり、従来のモデルが抱えていた三人称視点と一人称視点の混同や、ビデオ終盤情報の見落としといった課題を解決するために開発されました。 空間把握、時間的推論、物体接地、タスク計画の4つの核心能力を備え、ビデオ全編に加えて最終フレームを補助入力として活用する独自の手法と、一人称視点を含む大規模な独自データセットによって、高度な身体的知能を実現しています。 RobovqaおよびEgoplan-bench2という主要なベンチマークにおいて、GPT-4VやQwen2.5-VLなどの既存モデルを凌駕する世界最高水準の性能を達成し、日常生活から複雑な産業環境まで対応可能な計画能力を実証しました。
なぜこの問題か
現在のロボット工学において、大規模視覚言語モデル(VLM)の適用が急速に進んでいますが、人間にとっては容易な判断がモデルにとっては極めて困難であるという深刻な課題が浮き彫りになっています。既存の多くのVLMは、主に三人称視点で描かれた画像キャプションや視覚的質問応答のデータセットで学習されているため、ロボットが実際に活動する際の一人称視点(エゴビュー)での情報を正確に処理することができません。この視点の不一致は、ロボットが自身の現在の状態を把握し、将来の状態を予測する際の大きな障害となっており、特に空間的な関係性を自己中心的な座標系で理解する能力を制限しています。 また、従来のモデルはビデオを用いた推論において、時間的な経過を追う中でビデオの終盤に含まれる重要な情報を見落としてしまう傾向があり、これがタスクの完遂を妨げる要因となっていました。ロボット特有のタスク計画には、過去の観測結果を記憶し、それを現在の指示と統合して次の行動を決定するための時間的・空間的な情報が不可欠ですが、汎用的なモデルではこれらの情報が物理的な行動に結びついていません。…
核心:何を提案したのか
本研究では、身体化知能(エンボディド・インテリジェンス)のために特別に設計された大規模視覚言語基盤モデル「Thinker」を提案しています。Thinkerは、ロボットが直面する課題を解決するために、タスク計画、空間理解、時間的理解、および物体接地の4つの主要な能力を統合的に備えていることが特徴です。これらの能力を育成するために、研究チームはロボットの知覚と推論に特化した大規模かつ多様なデータセットを独自に構築しました。このデータセットには、一人称視点のビデオ、視覚的接地(グラウンディング)、空間把握、および思考の連鎖(Chain-of-Thought)に関するデータが含まれており、モデルが論理的な手順を踏んで推論を行うことを可能にしています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related