推論モデルは埋め込みモデルを強化するのか?
RLVR(検証可能な報酬による強化学習)で最適化された推論モデルを基盤としても、テキスト埋め込みモデルの性能はベースモデルと比較して向上しないという「ゼロ効果」が、MTEBやBRIGHTなどの主要なベンチマーク評価によって明らかになりました。
TL;DR(結論)
RLVR(検証可能な報酬による強化学習)で最適化された推論モデルを基盤としても、テキスト埋め込みモデルの性能はベースモデルと比較して向上しないという「ゼロ効果」が、MTEBやBRIGHTなどの主要なベンチマーク評価によって明らかになりました。 階層的表現類似性分析(HRSA)を用いた調査により、RLVRは潜在多様体のグローバルな幾何構造や線形読み出し能力を維持しつつ、既存の意味的景観の中での軌跡のみを最適化しており、多様体そのものを根本的に作り変えていないことが判明しました。 埋め込みモデル作成時の対照学習プロセスが、ベースモデルと推論モデルの間の表現のずれを解消する「多様体再整列(Manifold Realignment)」を引き起こすため、最終的に得られる埋め込み表現は機能的に同質化するというメカニズムが特定されました。
なぜこの問題か
現代の自然言語処理において、テキストのベクトル表現である埋め込みは、検索やクラスタリングなど多岐にわたるタスクの中核をなす抽象化技術です。近年、埋め込みモデルの構築手法は、デコーダーのみの大規模言語モデル(LLM)をバックボーンとして採用し、対照学習を通じて適応させる方向へと進化してきました。これにより、LLMのパラメータに蓄積された豊かな意味論や世界知識を、ベクトル空間の構築に活用することが可能となっています。一方で、DeepSeek-AIなどの研究に代表されるように、RLVR(検証可能な報酬による強化学習)を用いて最適化された推論モデルが、複雑な問題解決や推論において飛躍的な進歩を遂げています。 この発展に伴い、表現学習の分野では「強化された推論能力は、より優れたテキスト埋め込み空間へと変換されるのか」という自然な仮説が浮上しました。直感的には、より深く「考える」ことができるモデルは、単語や文章間の意味的関係をより効果的に構造化できるはずだと『推測』されます。…
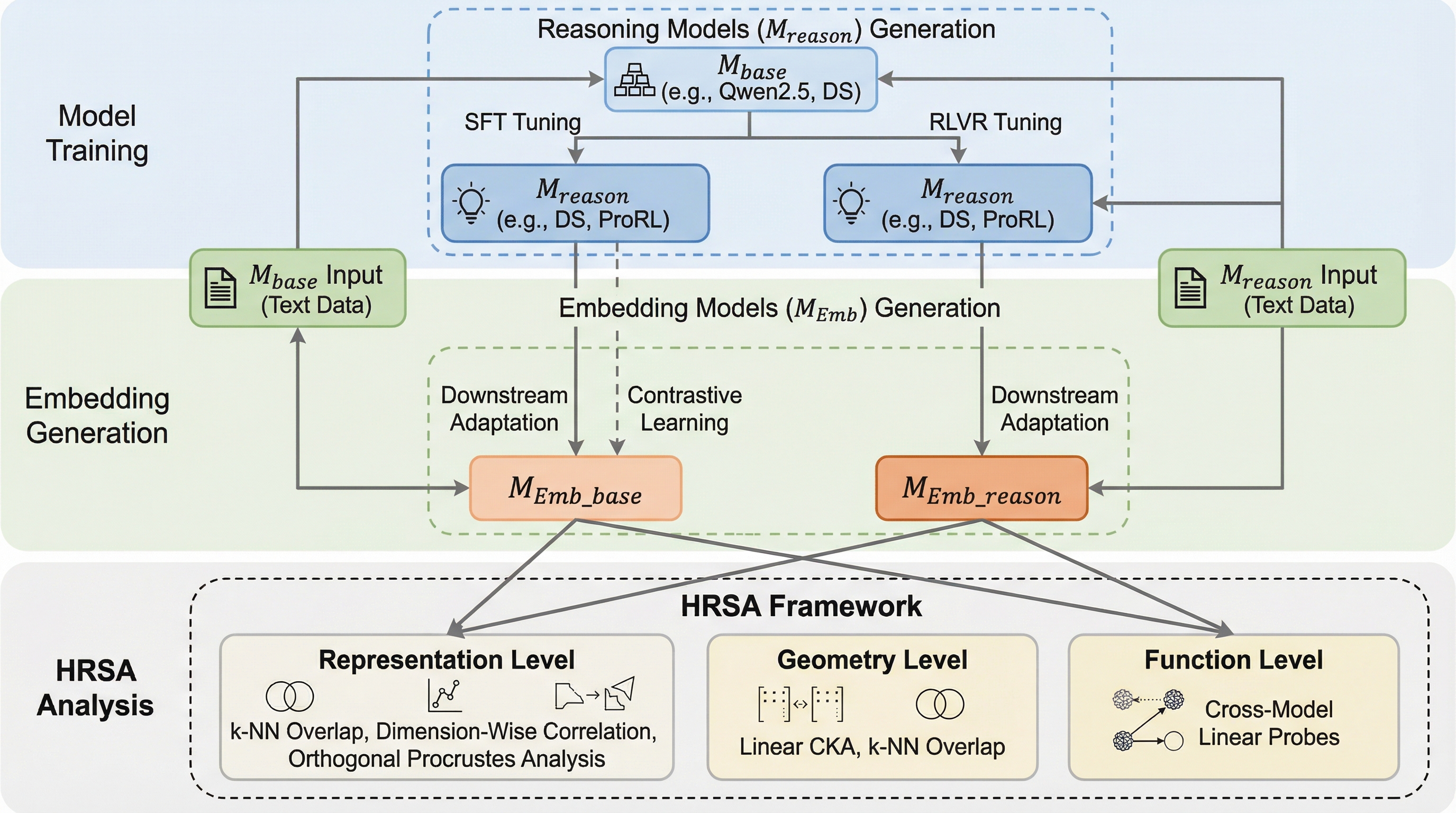
核心:何を提案したのか
本研究の主要な貢献は、モデル間の類似性を抽象度の異なる3つの階層で解剖する「階層的表現類似性分析(HRSA)」というフレームワークの提案です。HRSAは、表現レベル、幾何レベル、機能レベルという3つの入れ子状の段階で構成されており、従来の表現類似性分析(RSA)を統合・整理したツールキットとして機能します。このフレームワークを用いることで、単一のスコアでは隠されてしまう内部的な表現のシフトを、構造的に特定することが可能になります。 第一の「表現レベル」では、座標基底や特徴量そのものに焦点を当て、モデル間で特徴量が一対一で対応しているか、あるいは線形的な混合が生じているかを検証します。第二の「幾何レベル」では、特定の座標系に依存せず、潜在多様体の全体的な形状や局所的な近傍関係の維持を評価します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related