言語モデルにおけるエンベディングのスケーリングはエキスパートのスケーリングを凌駕する
大規模言語モデルの性能向上において主流であるMixture-of-Experts(MoE)は、計算効率の飽和やシステム上の通信負荷という課題に直面していますが、本研究は計算コストの極めて低いエンベディング層を拡張する「N-gram Embedding」が、特定の高スパース性条件下でエキスパートの増量よりも優れた性能対コスト比(パレート境界)を実現することを解明しました。 モデルの総パラメータの最大50%までをエンベディングに割り当て、ハッシュ衝突を回避するために語彙サイズをベース語彙の整数倍から意図的にずらすといった具体的な設計指針を提示し、これにより計算量を抑えつつモデルの表現力を大幅に強化できることを示しました。 この理論に基づき、685億パラメータを持ちながら推論時には約30億パラメータのみを活性化させる「LongCat-Flash-Lite」を開発し、同規模のMoEモデルを凌駕する性能を達成するとともに、特に複雑な推論が求められるエージェントタスクやコーディングの領域で既存のモデルに対して高い競争力を示しました。
TL;DR(結論)
大規模言語モデルの性能向上において主流であるMixture-of-Experts(MoE)は、計算効率の飽和やシステム上の通信負荷という課題に直面していますが、本研究は計算コストの極めて低いエンベディング層を拡張する「N-gram Embedding」が、特定の高スパース性条件下でエキスパートの増量よりも優れた性能対コスト比(パレート境界)を実現することを解明しました。 モデルの総パラメータの最大50%までをエンベディングに割り当て、ハッシュ衝突を回避するために語彙サイズをベース語彙の整数倍から意図的にずらすといった具体的な設計指針を提示し、これにより計算量を抑えつつモデルの表現力を大幅に強化できることを示しました。 この理論に基づき、685億パラメータを持ちながら推論時には約30億パラメータのみを活性化させる「LongCat-Flash-Lite」を開発し、同規模のMoEモデルを凌駕する性能を達成するとともに、特に複雑な推論が求められるエージェントタスクやコーディングの領域で既存のモデルに対して高い競争力を示しました。
なぜこの問題か
大規模言語モデル(LLM)の能力を拡張するための標準的な手法として、Mixture-of-Experts(MoE)アーキテクチャが広く採用されてきました。MoEは、入力トークンを一部のエキスパートにのみルーティングすることで、計算コストを一定に保ちながらモデルの総パラメータ数を増大させることを可能にしました。しかし、モデルの規模やスパース性が極限まで高まるにつれて、パラメータを増やしても性能が向上しにくくなる「収穫逓減」の現象が顕著に報告されるようになっています。また、システムレベルの視点では、分散学習時におけるエキスパート間の通信オーバーヘッドや、メモリ帯域幅への負荷が深刻なボトルネックとなっており、単純なエキスパートの拡張には物理的な限界が見え始めています。 このような背景から、フィードフォワードネットワーク(FFN)を拡張する従来のMoEとは異なる、計算効率に優れた新しいスケーリングの次元を探索する必要性が急速に高まっていました。そこで注目されたのが、計算複雑度がO(1)のルックアップ操作のみで完結するエンベディング層です。…
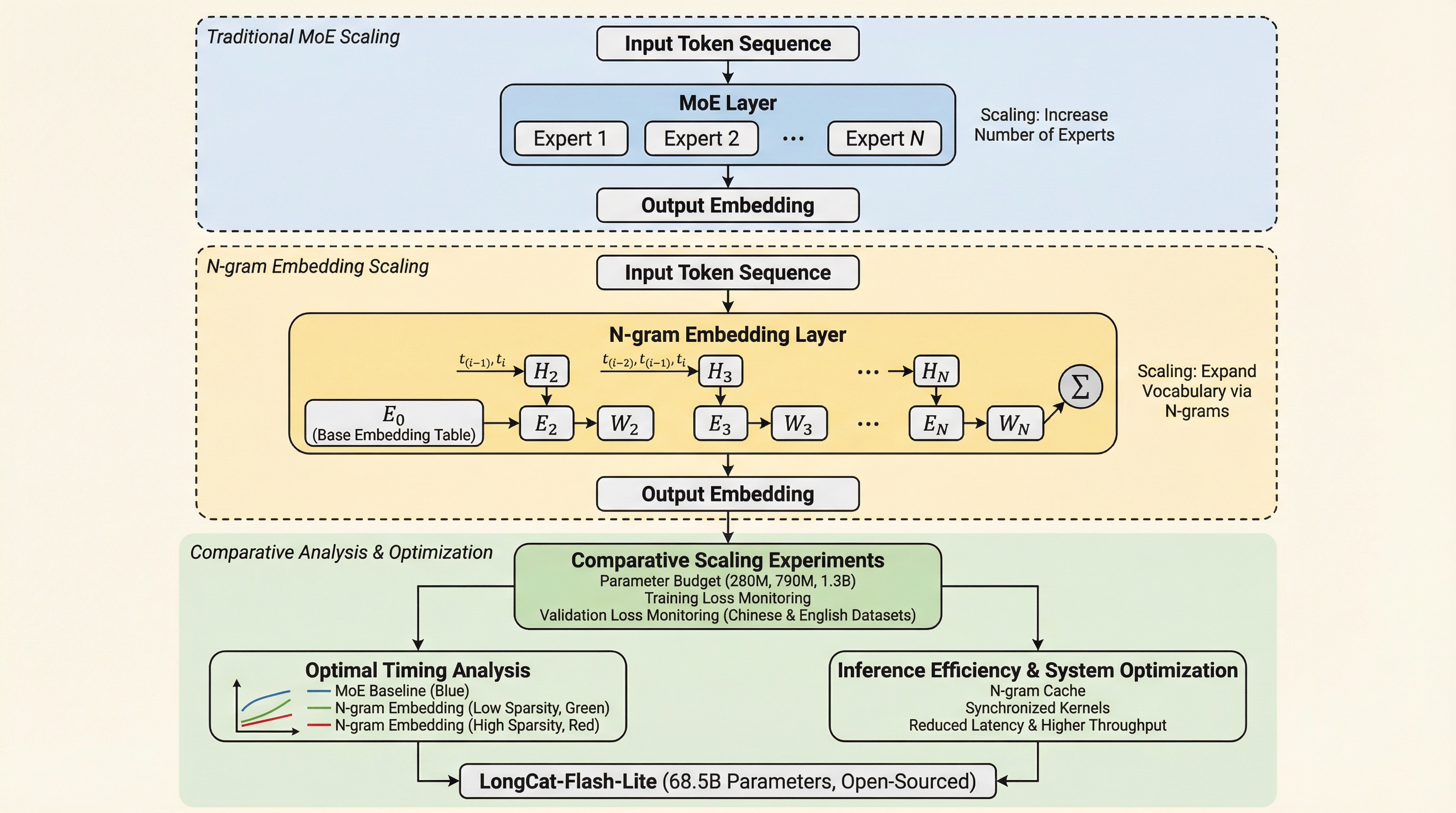
核心:何を提案したのか
本研究の核心は、エンベディング層をスケーリングする手法である「N-gram Embedding」が、従来の「エキスパートのスケーリング」を上回る効率を発揮する領域を特定し、そのための最適な設計フレームワークを構築したことにあります。具体的には、単一のトークンだけでなく、直前の複数のトークンの並び(N-gram)に基づいた巨大なエンベディングテーブルを導入することで、モデルの表現力を大幅に強化する手法を提案しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related