推論モデルは埋め込みモデルを強化するのか?
検証可能な報酬を用いた強化学習(RLVR)で訓練された推論モデルを初期値として用いても、埋め込みモデルの性能はベースモデルと比較して統計的に有意な向上を示さない「無効果(Null Effect)」が確認された。
TL;DR(結論)
検証可能な報酬を用いた強化学習(RLVR)で訓練された推論モデルを初期値として用いても、埋め込みモデルの性能はベースモデルと比較して統計的に有意な向上を示さない「無効果(Null Effect)」が確認された。 新しく提案された階層的表現類似性分析(HRSA)により、RLVRは潜在多様体の大域的な幾何構造と線形読み出し機能を保持しつつ、局所的な幾何構造のみを不可逆的に再編成していることが明らかになった。 対照学習を行うことで、RLVRによって生じた可逆的な座標基底のズレが修正される「多様体リアライメント(Manifold Realignment)」現象が発生し、最終的な埋め込みモデルはベースモデルと強く整列する結果となる。
なぜこの問題か
大規模言語モデルから埋め込みモデルへの転用 近年、テキスト埋め込み(Text Embeddings)の分野では、デコーダのみの大規模言語モデル(LLM)をバックボーンとして採用し、対照学習(Contrastive Learning)によって適応させる手法が主流となりつつあります。LLMがパラメータ内に保持している豊富な意味論的知識や世界知識を活用することで、より高品質なベクトル表現が得られると考えられているためです。 推論モデルの台頭と自然な疑問 さらに直近の動向として、ベースモデルに対して「検証可能な報酬を用いた強化学習(RLVR: Reinforcement Learning with Verifiable Rewards)」を適用することで最適化された「推論モデル」が登場しています。DeepSeek-R1などのモデルに代表されるように、これらのモデルは複雑な問題解決や推論能力において質的な飛躍を遂げています。 ここで、表現学習の観点から一つの自然な仮説が浮かび上がります。「より深く『思考』できるモデルは、意味的な関係性もより効果的に構造化できるのではないか?」というものです。…
核心:何を提案したのか
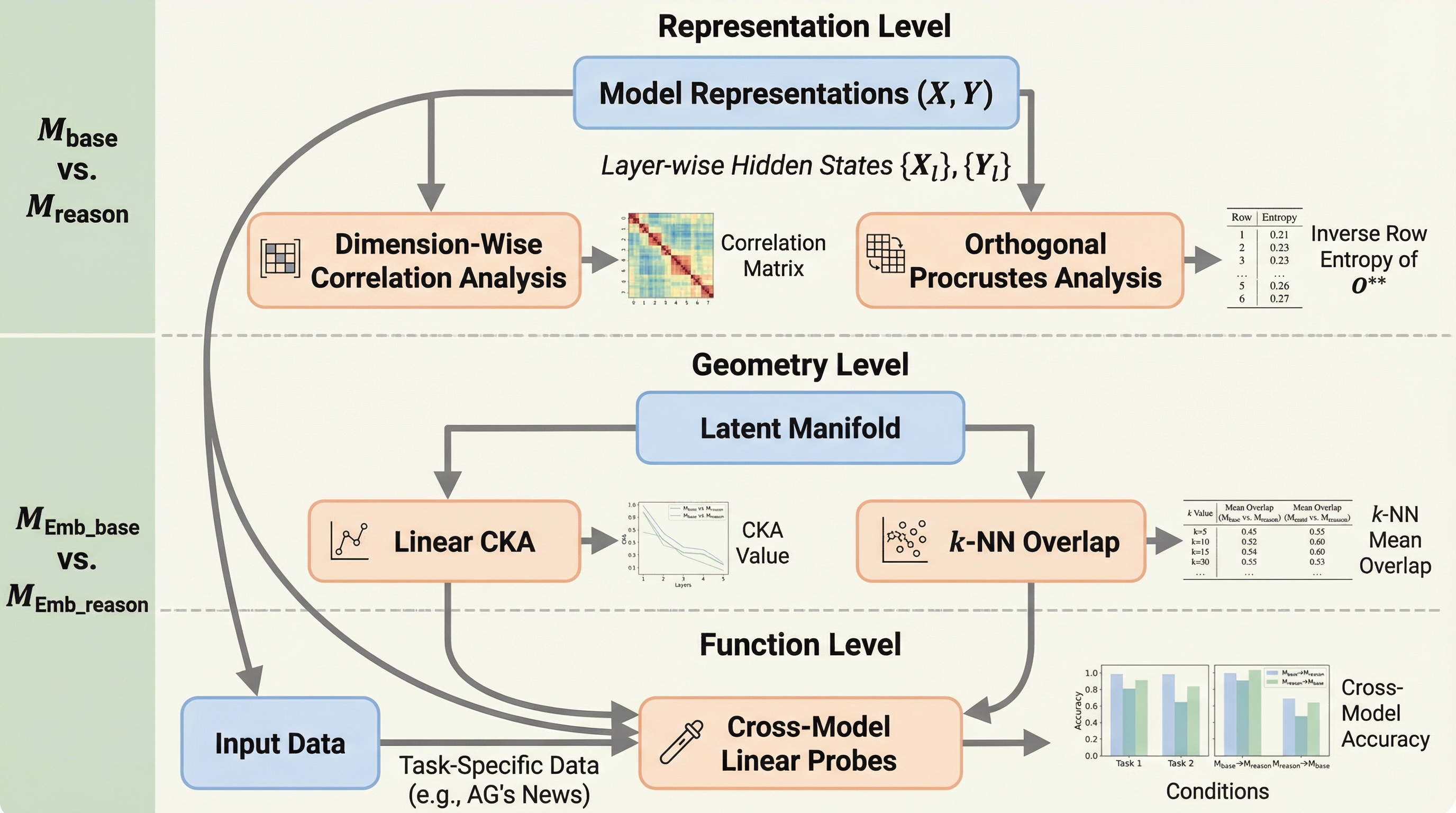
「無効果」のパラドックスの解明 本研究の核心は、RLVRによって強化された推論モデルが埋め込みタスクにおいてベースモデルと変わらない性能しか発揮しないという「無効果」の現象を発見し、その原因を体系的に解明した点にあります。単にベンチマークスコアを比較するだけでは見えてこない、モデル内部の表現の力学を診断する必要がありました。 HRSAフレームワークの導入 既存の性能指標では内部表現の変化を十分に診断できないという課題に対し、著者らは「階層的表現類似性分析(HRSA: Hierarchical Representation Similarity Analysis)」という新しい分析フレームワークを提案しました。これは、モデル間の類似性を以下の3つの抽象レベルで分解して分析する手法です。 1.…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related