継続的ファインチューニングにおける大規模言語モデルの破滅的忘却のメカニズム的分析
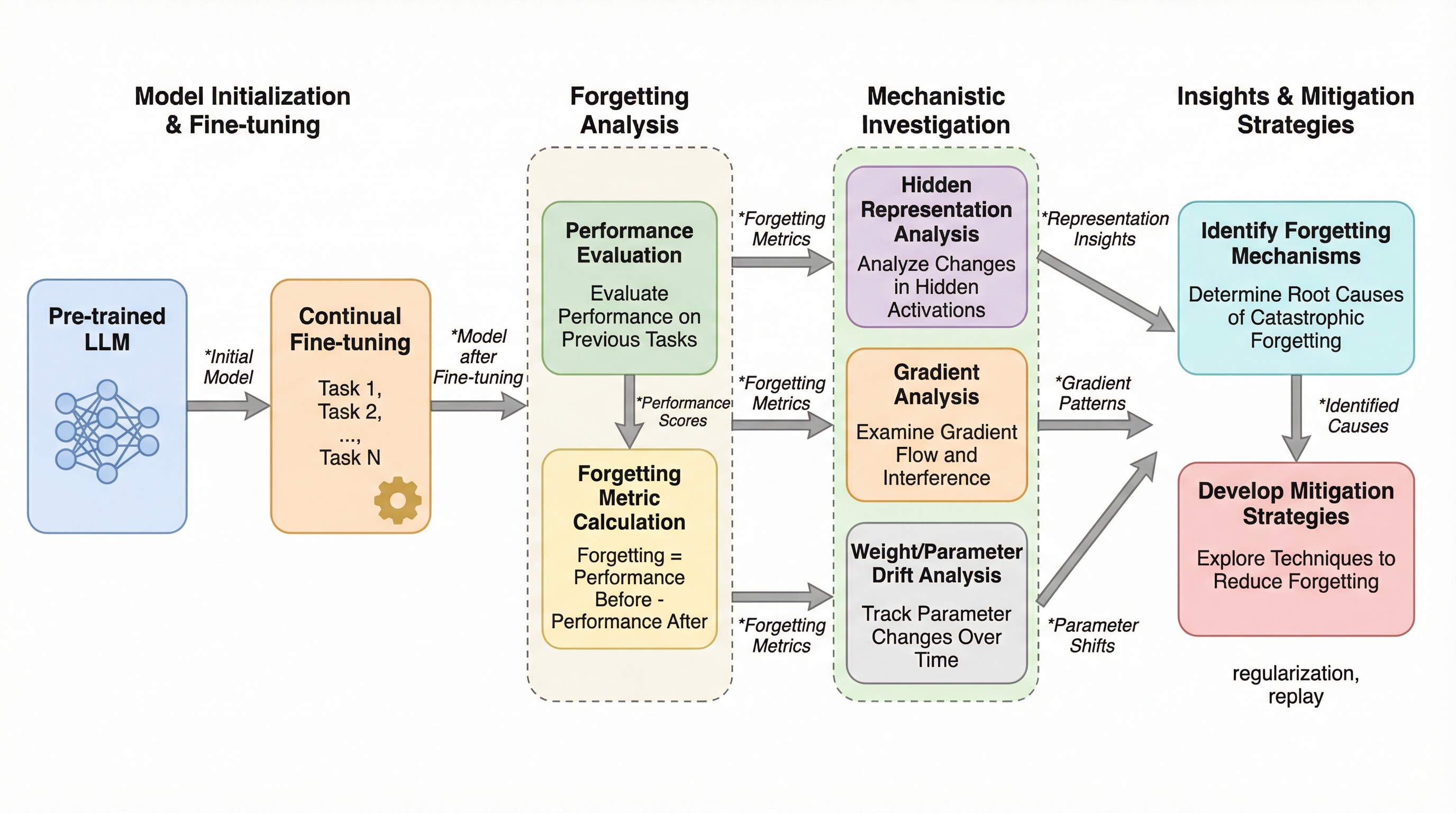
109Bから1.5T規模の大規模言語モデルを対象に、継続学習における破滅的忘却の内部メカニズムを分析し、下位層の注意機構での勾配干渉、中間層の表現ドリフト、損失曲面の平坦化という3つの主要要因を特定した。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
109Bから1.5T規模の大規模言語モデルを対象に、継続学習における破滅的忘却の内部メカニズムを分析し、下位層の注意機構での勾配干渉、中間層の表現ドリフト、損失曲面の平坦化という3つの主要要因を特定した。
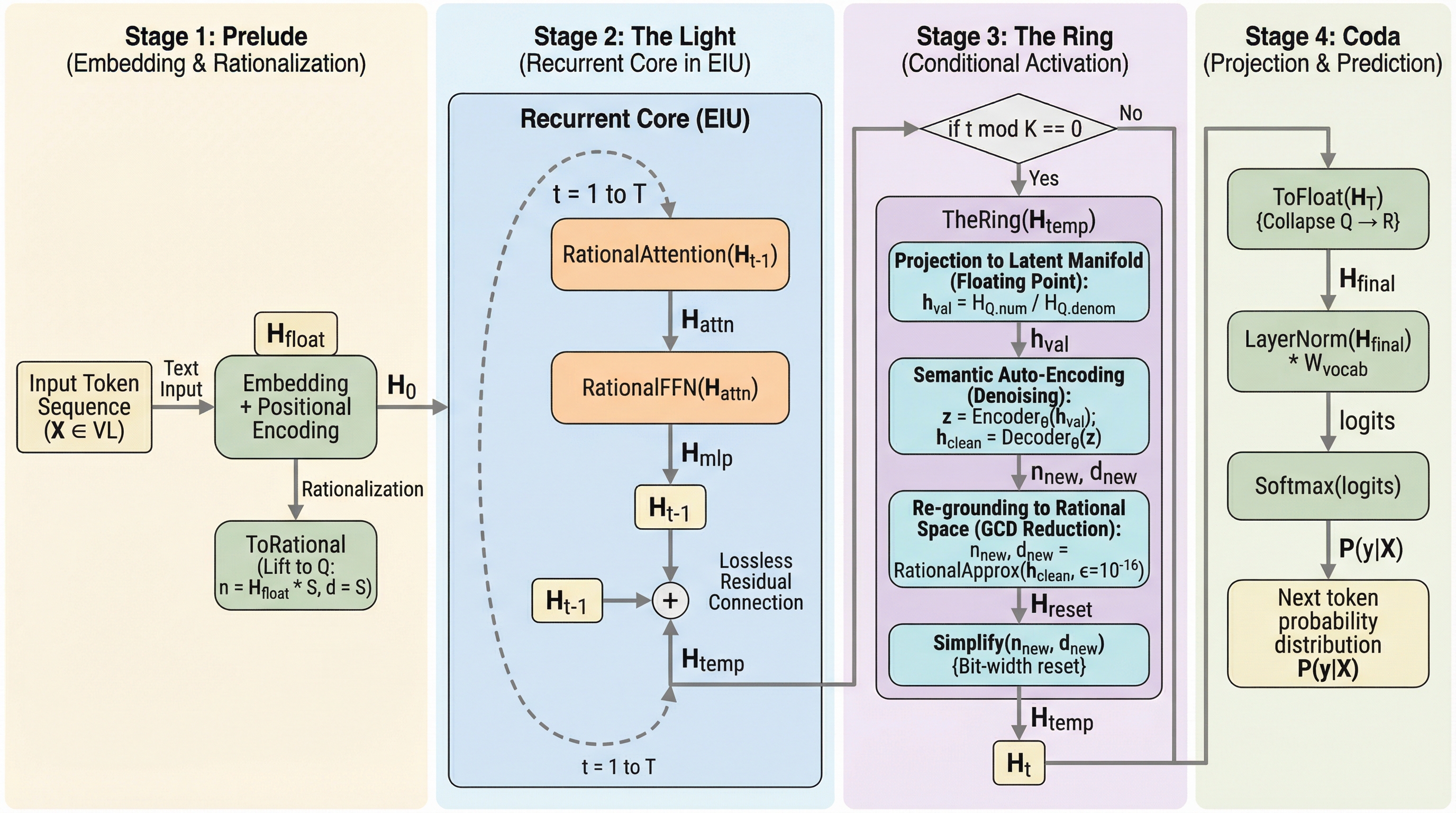
現在の深層学習が依存する浮動小数点演算の近似誤差が、深い推論における「論理的な幻覚」や「セマンティック・ドリフト」の根本原因であると特定し、これを排除するための新しい計算パラダイムを提案した。 有理数演算(Q)を基盤とする「Haloアーキテクチャ」と専用ハードウェア「Exact Inference Unit(EIU)」を導入することで、誤差の蓄積をゼロに抑え、理論上無限の深さを持つ論理推論を可能にする。 600Bパラメータ規模のモデルを用いた検証では、従来の浮動小数点形式がカオス的な系で崩壊する一方で、本提案手法は無限に精度を維持し、大規模モデルほど数値的に不安定になるという「次元の呪い」を克服した。
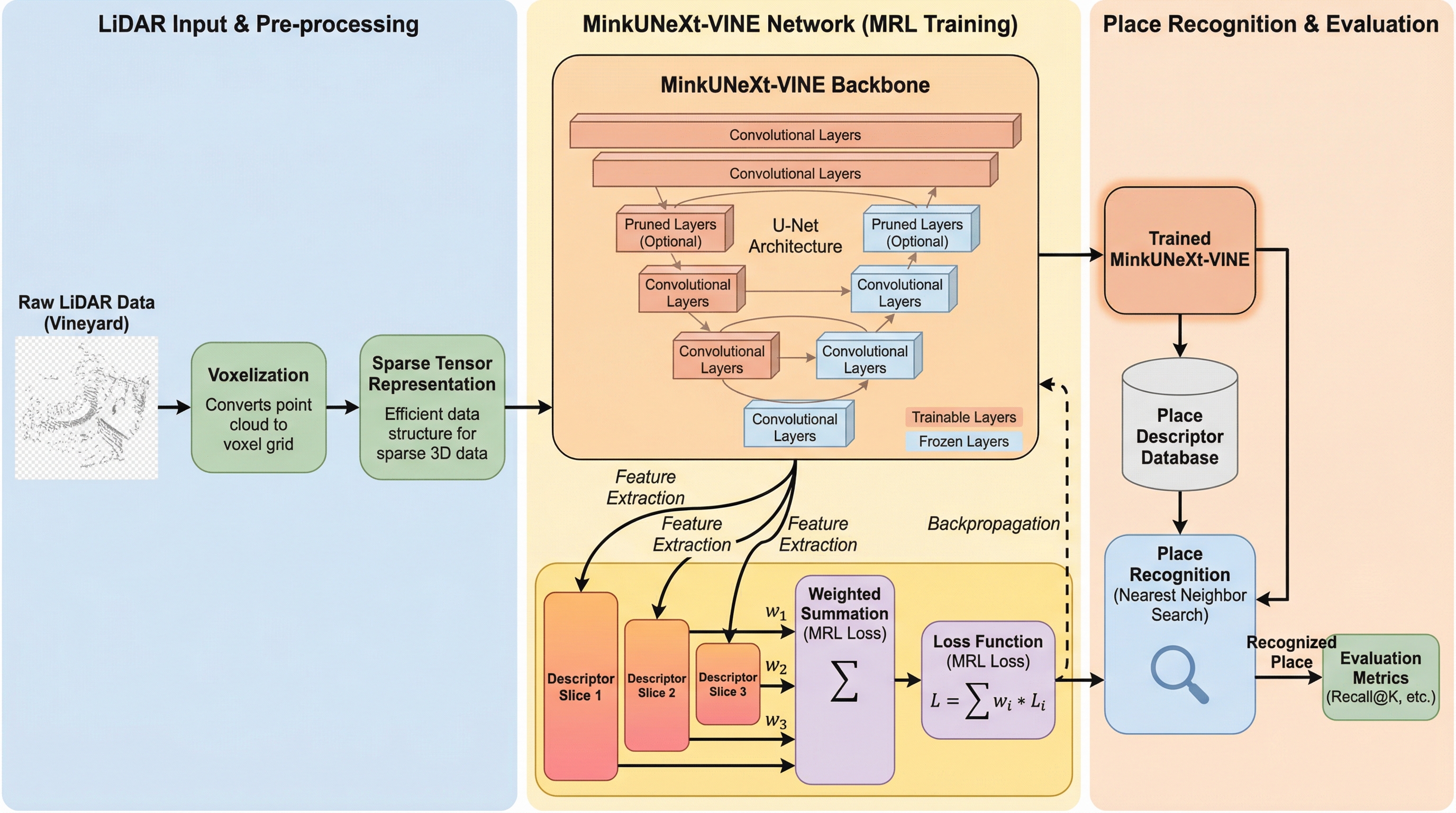
ブドウ園のような非構造的で特徴的な目印が乏しい農業環境において、ロボットが正確に自己位置を特定するための軽量な深層学習手法「MinkUNeXt-VINE」が提案されました。 既存のネットワーク構造を剪定して計算負荷を下げつつ、マトリョーシカ表現学習(MRL)を導入することで、低次元から高次元まで柔軟かつ頑健な記述子を生成し、リアルタイムでの高い処理効率を実現しています。 複数のブドウ園で収集された長期的なデータセットを用いた検証により、季節による外観の変化や低コスト・低解像度なLiDAR入力に対しても、従来の最先端手法を上回る優れた認識精度と汎用性が実証されました。
現在の大規模言語モデルは英語以外の言語、特に学習データが少ない低リソース言語において推論能力が著しく低下するという深刻な課題を抱えていますが、本研究は対象言語のデータを一切使わずに英語の翻訳データと強化学習のみで能力を向上させる「SP3F」という革新的な二段階フレームワークを提案しました。
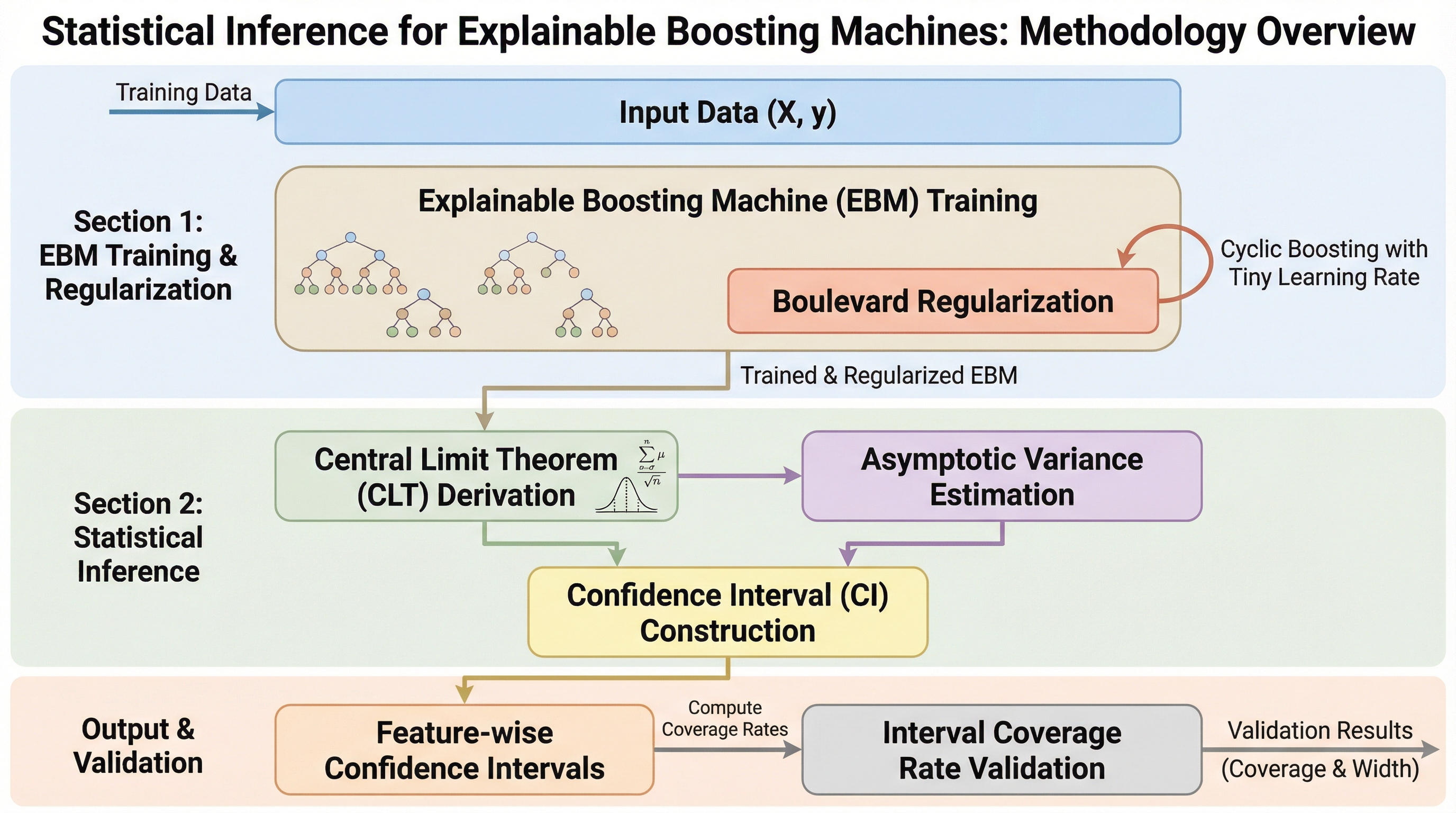
本研究は、解釈性の高い「グラスボックス」モデルである説明可能なブースティングマシン(EBM)に、移動平均を用いたブールバード正則化を導入することで、学習プロセスを特徴量ごとのカーネルリッジ回帰へと収束させる理論的枠組みを構築しました。
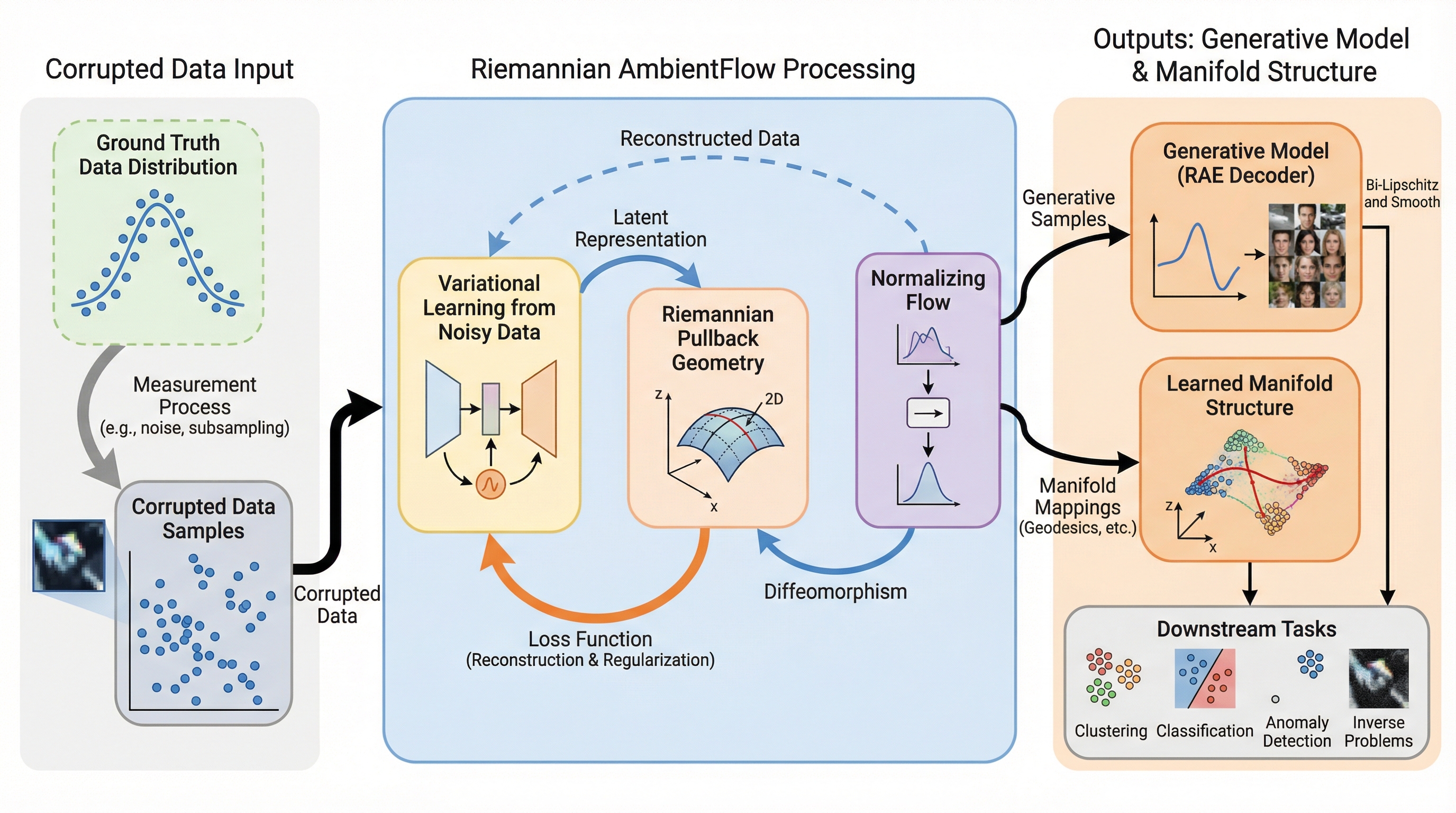
本研究は、ノイズや線形な汚染を含む観測データのみから、データの背後にある非線形な多様体構造と確率的生成モデルを同時に学習する新しい枠組み「Riemannian AmbientFlow」を提案しました。
Reflectは、大規模言語モデルを自然言語の原則(憲法)に適合させるための、追加学習や人間による注釈を一切必要としない推論時フレームワークである。 初期回答の生成、自己評価、自己批判、最終修正という4段階のプロセスをインコンテキストで実行することで、モデルの判断を透明化し、複雑な価値観への適合性を大幅に向上させる。
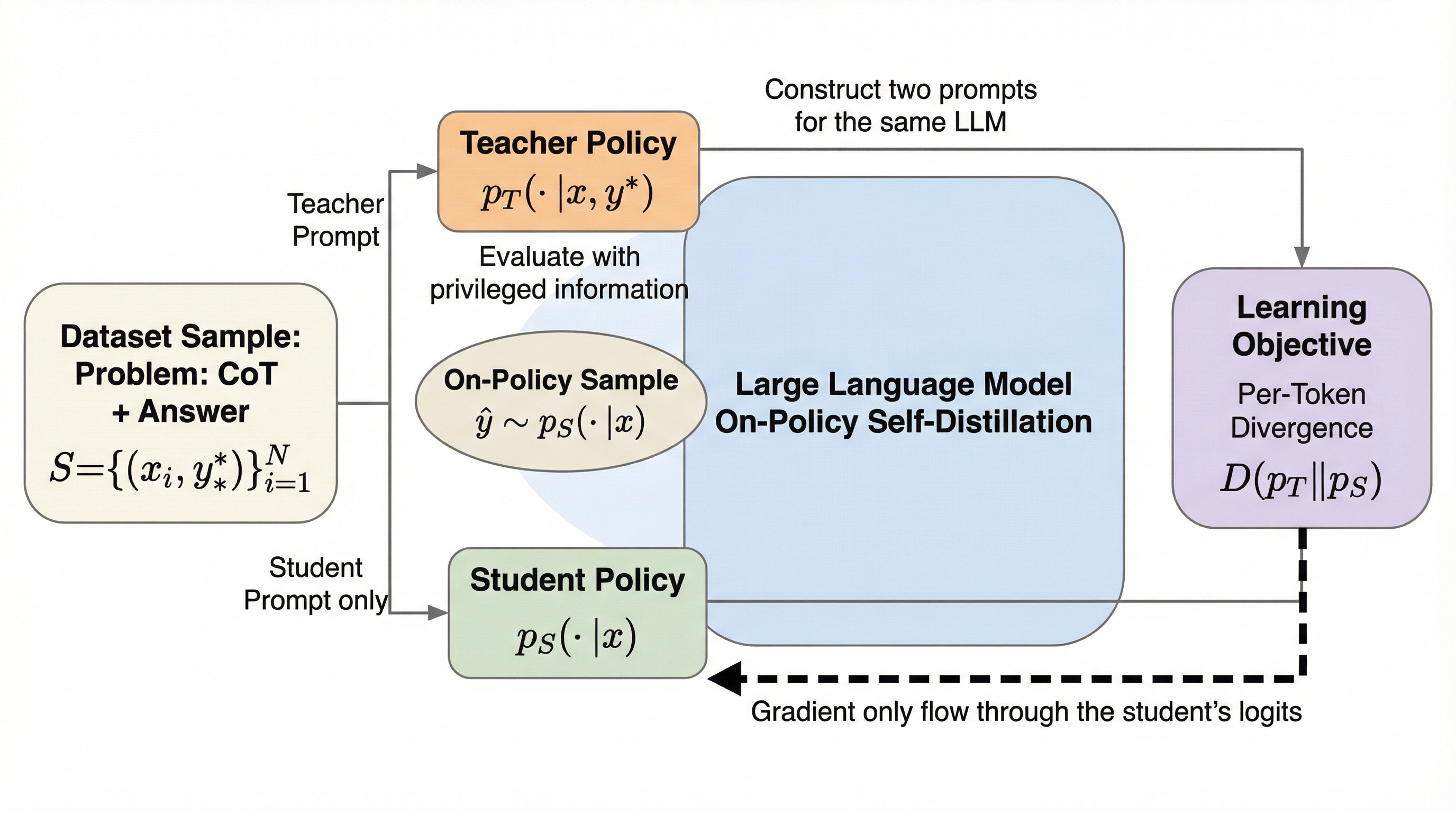
大規模言語モデルの推論能力を向上させるため、外部の教師モデルを必要とせず、単一のモデルが特権情報を活用して自分自身を教育する「オンポリシー自己蒸留(OPSD)」という新しい学習枠組みが提案されました。
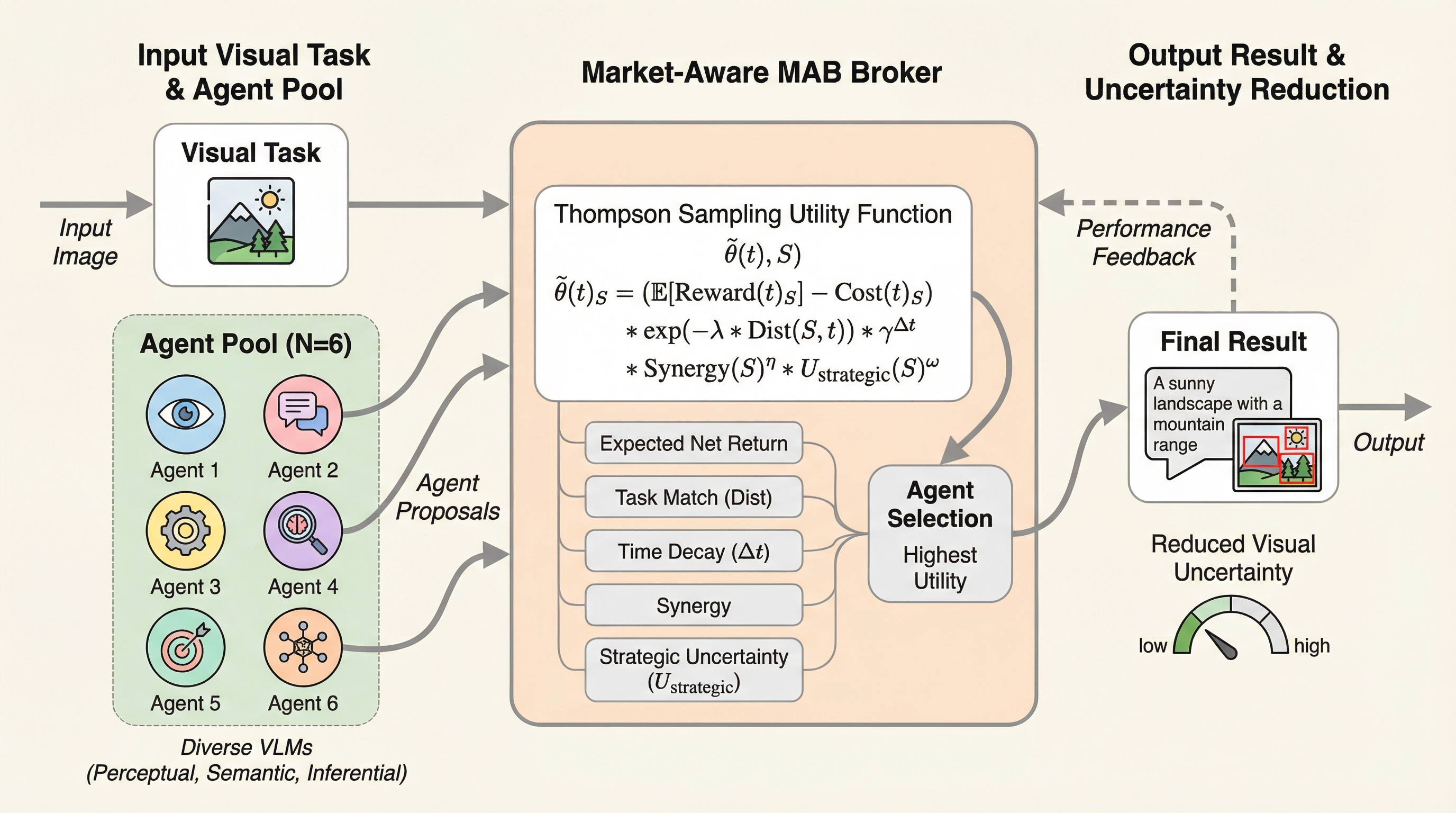
視覚言語モデル(VLM)を用いたマルチエージェントシステムにおいて、情報の非対称性と調整コストの増大という経済的課題を解決するため、不確実性を「取引可能な資産」と定義する分散型市場フレームワーク「Agora」が提案されました。
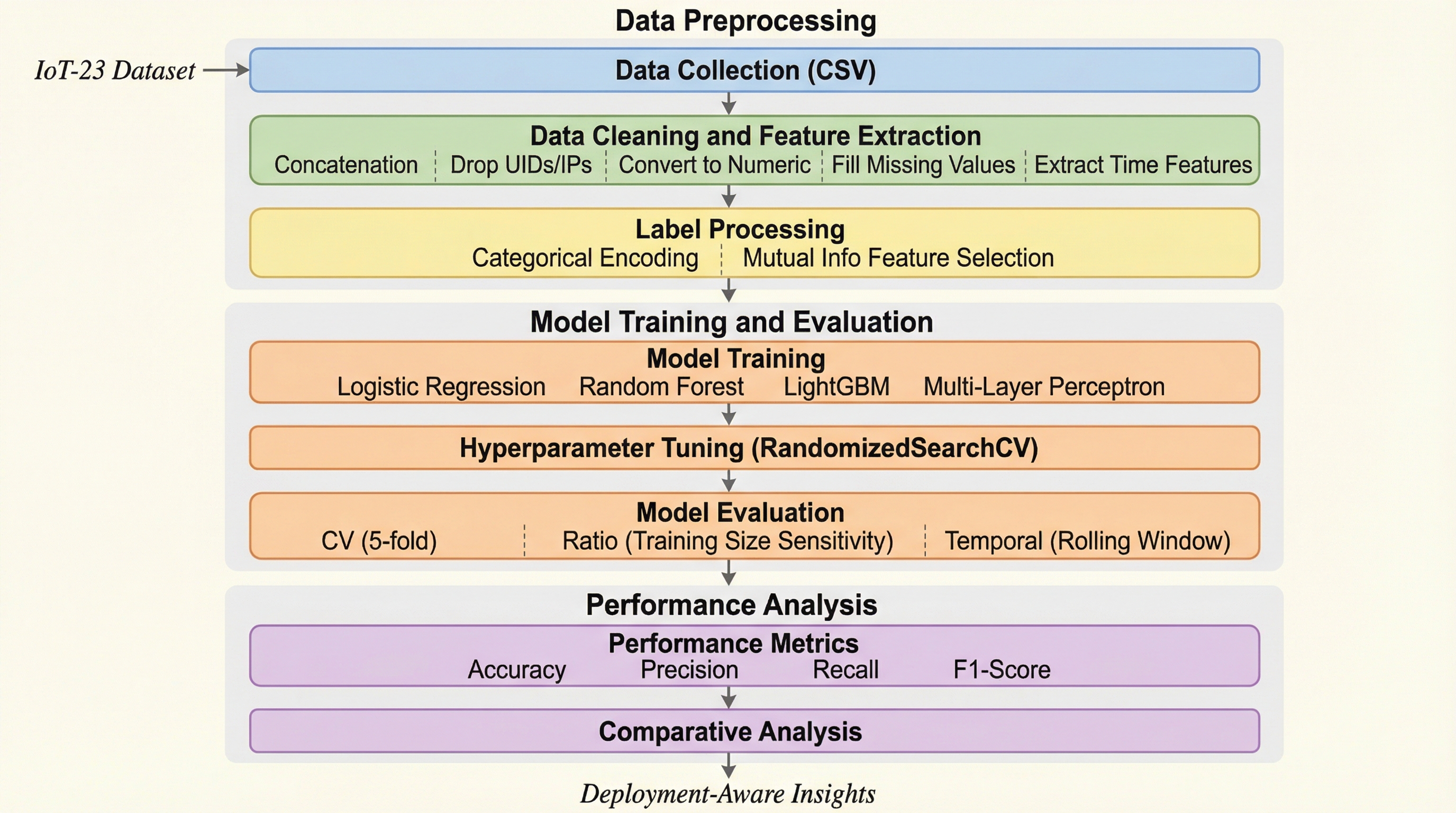
スマートシティや産業インフラで急増するIoTデバイスを保護するため、IoT-23データセットを用いてロジスティック回帰、ランダムフォレスト、LightGBM、多層パーセプトロンの4モデルを、バイナリおよびマルチクラス分類の観点から詳細に評価した。