継続的ファインチューニングにおける大規模言語モデルの破滅的忘却のメカニズム的分析
109Bから1.5T規模の大規模言語モデルを対象に、継続学習における破滅的忘却の内部メカニズムを分析し、下位層の注意機構での勾配干渉、中間層の表現ドリフト、損失曲面の平坦化という3つの主要要因を特定した。
TL;DR(結論)
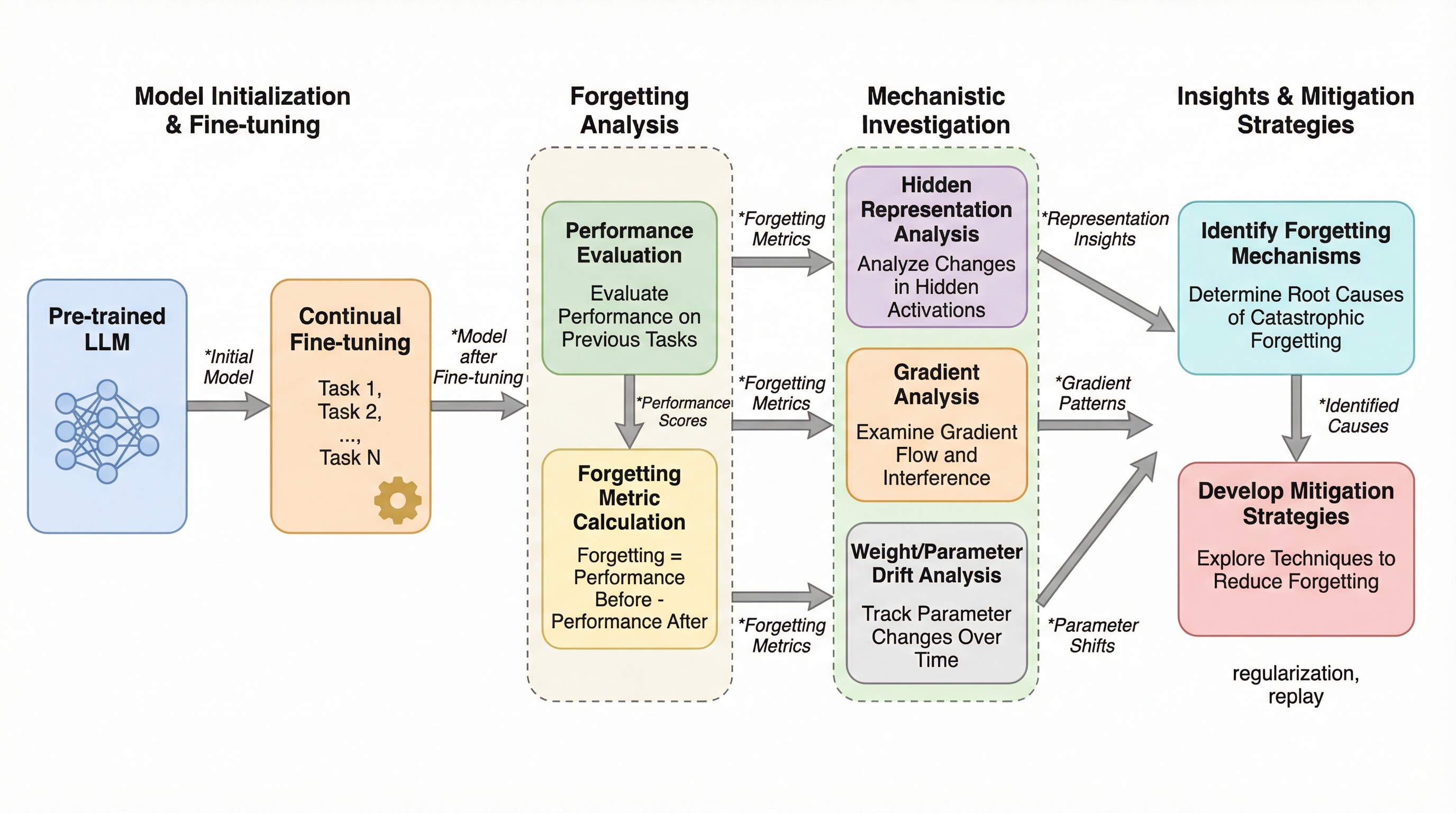
109Bから1.5T規模の大規模言語モデルを対象に、継続学習における破滅的忘却の内部メカニズムを分析し、下位層の注意機構での勾配干渉、中間層の表現ドリフト、損失曲面の平坦化という3つの主要要因を特定した。 注意ヘッドの15〜23%が深刻な破壊を受けていることを突き止め、注意重みの凍結により忘却を64%抑制できることや、学習開始直後の勾配整列指標から最終的な忘却の程度を高い精度で予測可能であることを示した。 破壊された特定の注意ヘッドの切除と、中間層の表現を幾何学的に再整列させる介入を組み合わせることで、過去のタスク性能を最大71%回復させることに成功し、モデル内部の特定の回路を保護する重要性を明らかにした。
なぜこの問題か
大規模言語モデル(LLM)は、膨大なデータセットを用いた事前学習と、その後の特定のタスクに適応させるためのファインチューニングという二段階のプロセスを経て、多様なドメインで優れた性能を発揮している。しかし、新しいタスクを順次学習させていく継続的なファインチューニングの過程において、新しく獲得した知識が以前に学習した能力を妨害し、過去のタスクの性能が劇的に低下する「破滅的忘却」という現象が大きな課題となっている。この現象はニューラルネットワークの研究初期から知られている根本的な問題であるが、現代のトランスフォーマーをベースとした巨大なモデルにおいて、内部でどのような機械論的なメカニズムが働いているのかという理解は依然として限定的である。 特に、GPT-5.1、Claude Opus 4.5、Gemini 2.5 Pro、Llama 4といった最新のモデルが、複雑な推論やコード生成、科学的タスクにおいて人間と同等の性能を示すようになっている現在、既存の能力を犠牲にすることなく、進化し続けるデータ分布や新しいユーザーの要件に適応し続ける必要性がかつてないほど高まっている。…
核心:何を提案したのか
本研究では、トランスフォーマーベースのLLMにおける破滅的忘却の包括的な機械論的分析を提案している。具体的には、109Bから1.5Tのパラメータ規模を持つ6つの主要なモデルを対象に、系統的な実験を行った。対象モデルには、オープンウェイトのLlama 4 Scout、Llama 4 Maverick、DeepSeek-V3.1に加え、プロプライエタリなGPT-5.1、Claude Opus 4.5、Gemini 2.5 Proが含まれる。研究の核心は、忘却を駆動する3つの主要なメカニズムを特定したことにある。第一に注意重みにおける勾配干渉、第二に中間層における表現ドリフト、第三に以前のタスクの極小値付近での損失曲面の平坦化である。 これらのメカニズムを解明するために、タスクの類似性が異なる12のファインチューニング軌道を設計し、モデル内部の状態を詳細に追跡した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related