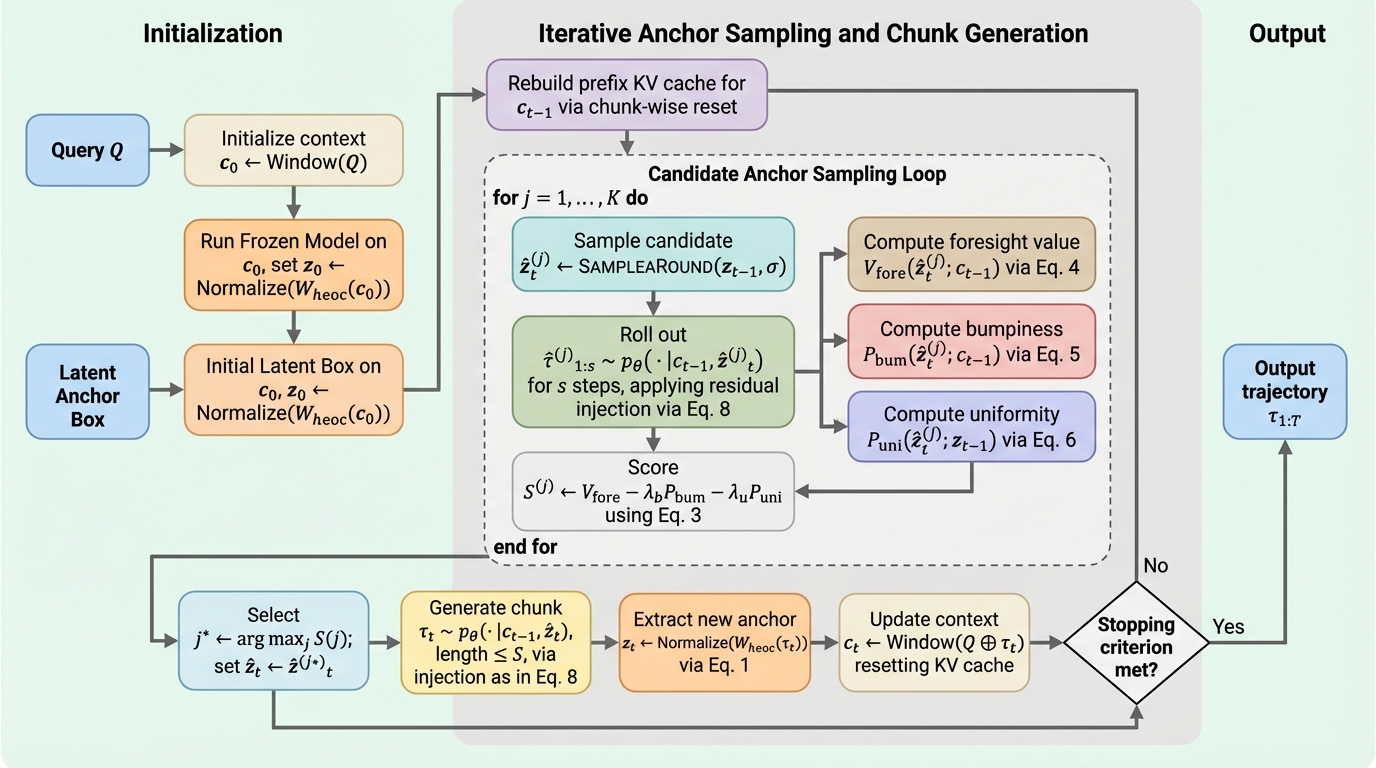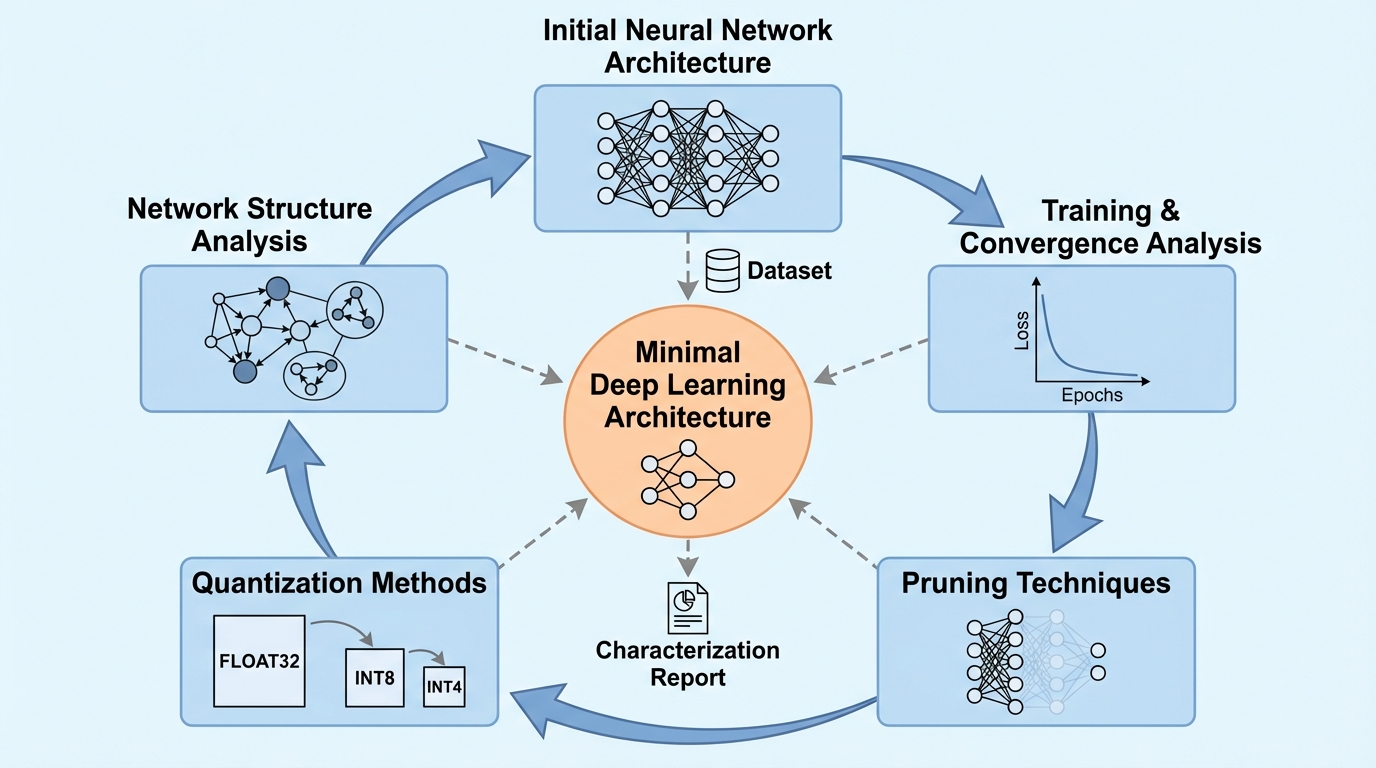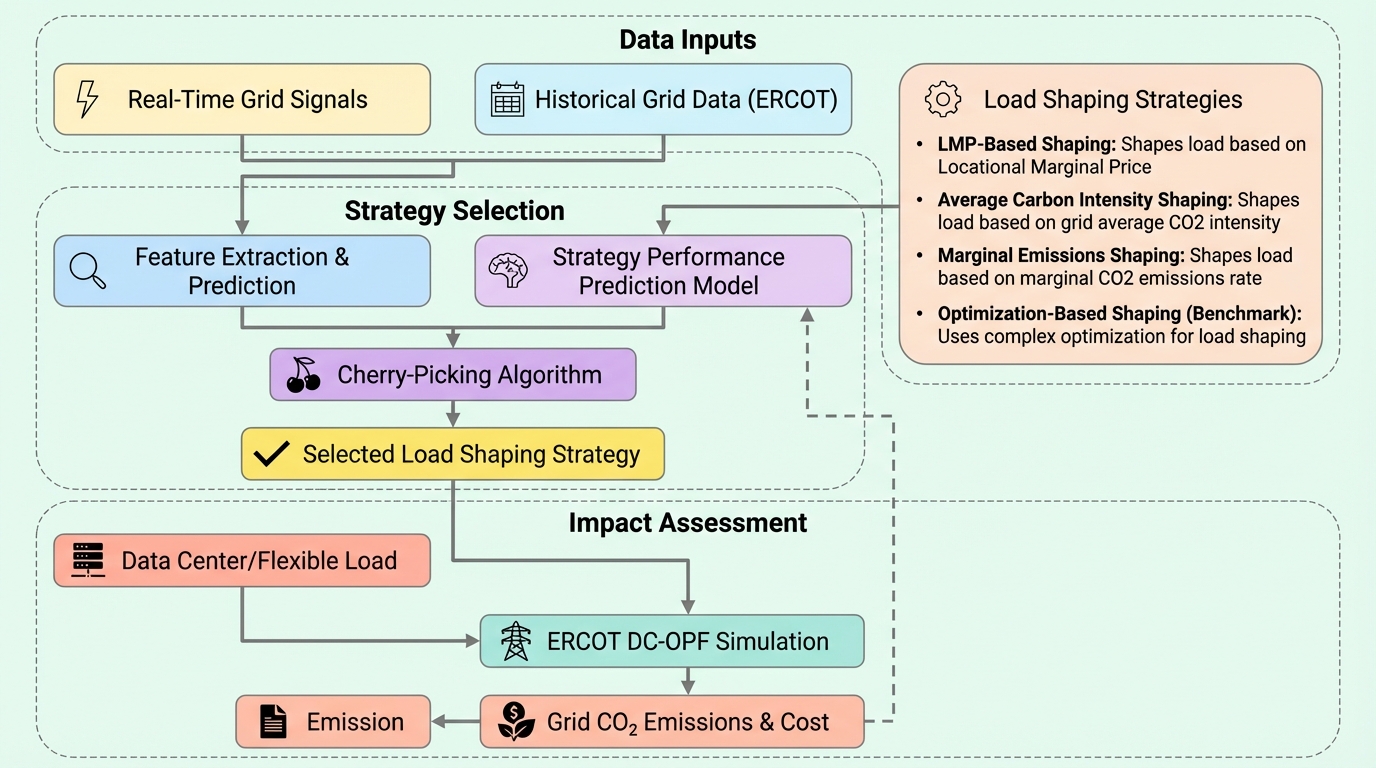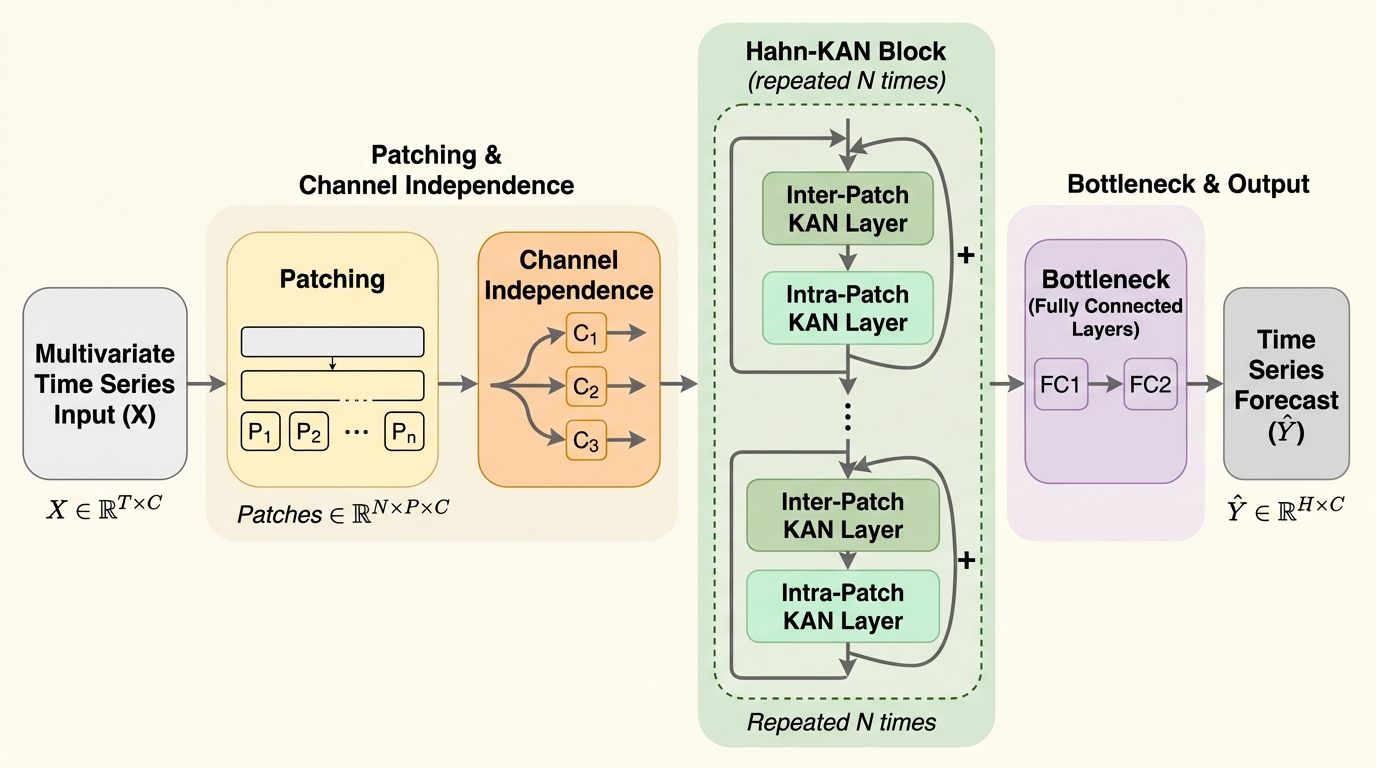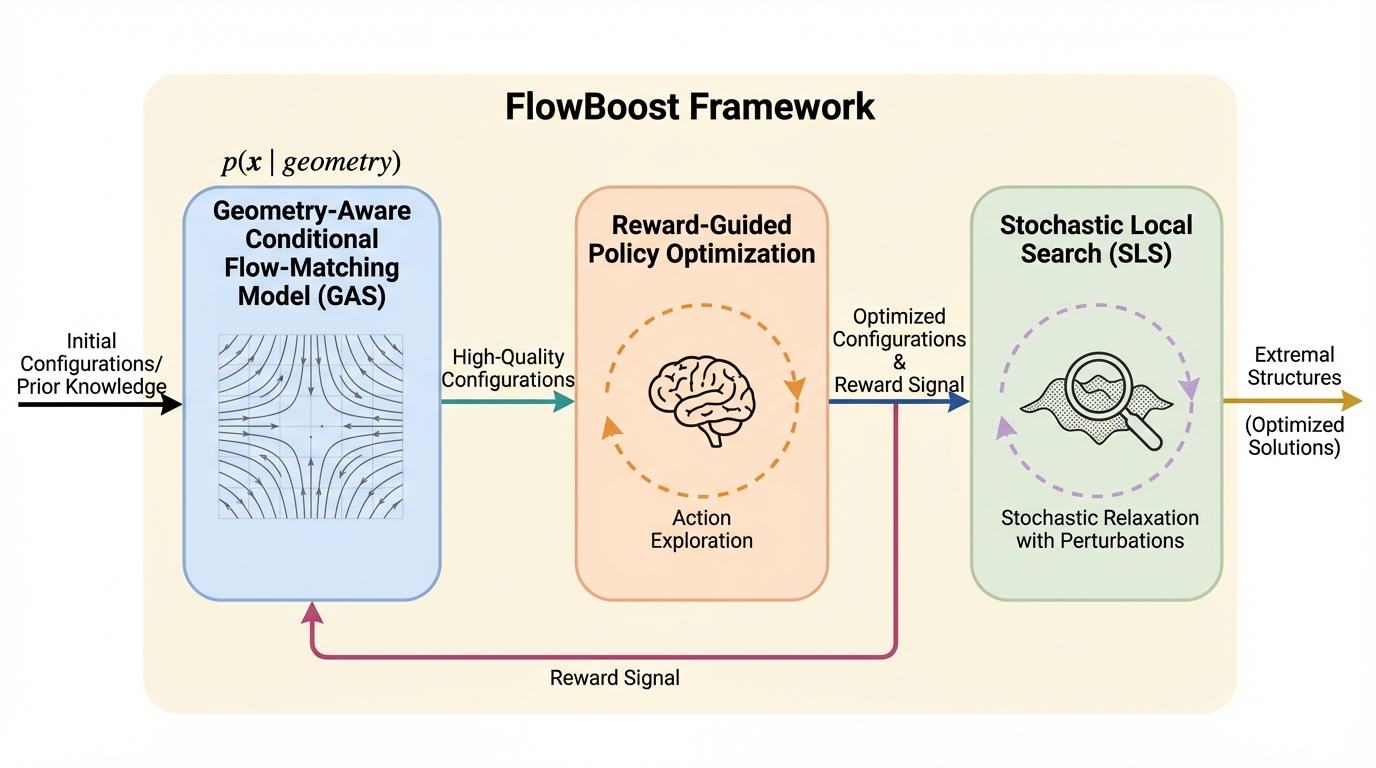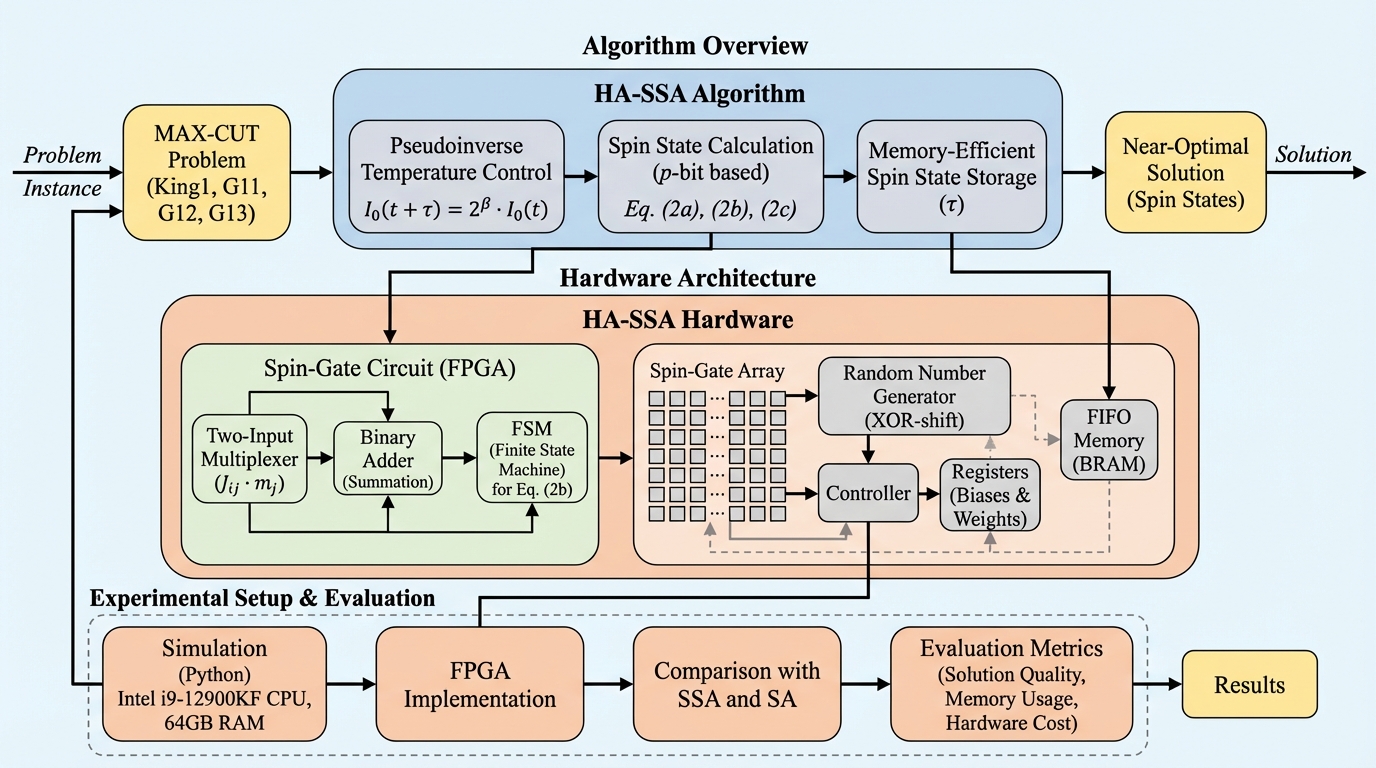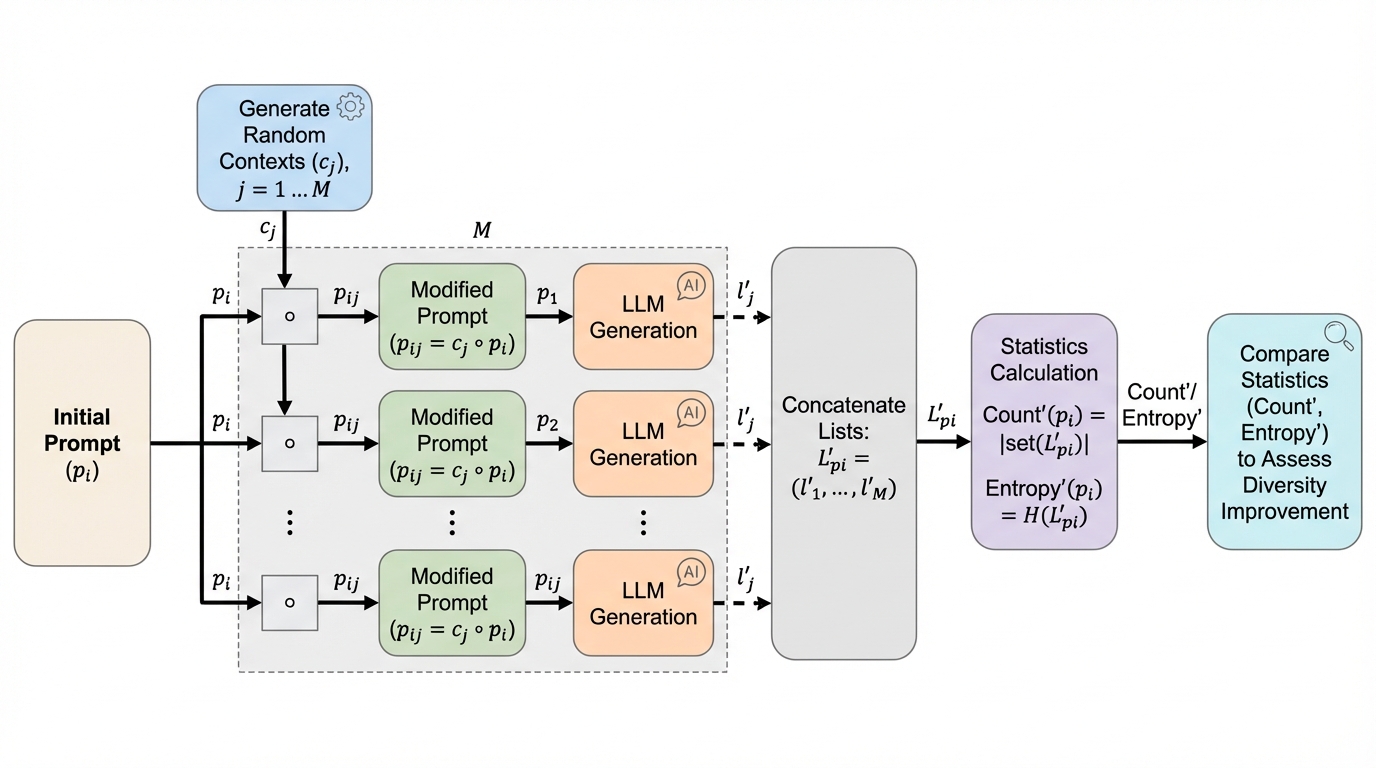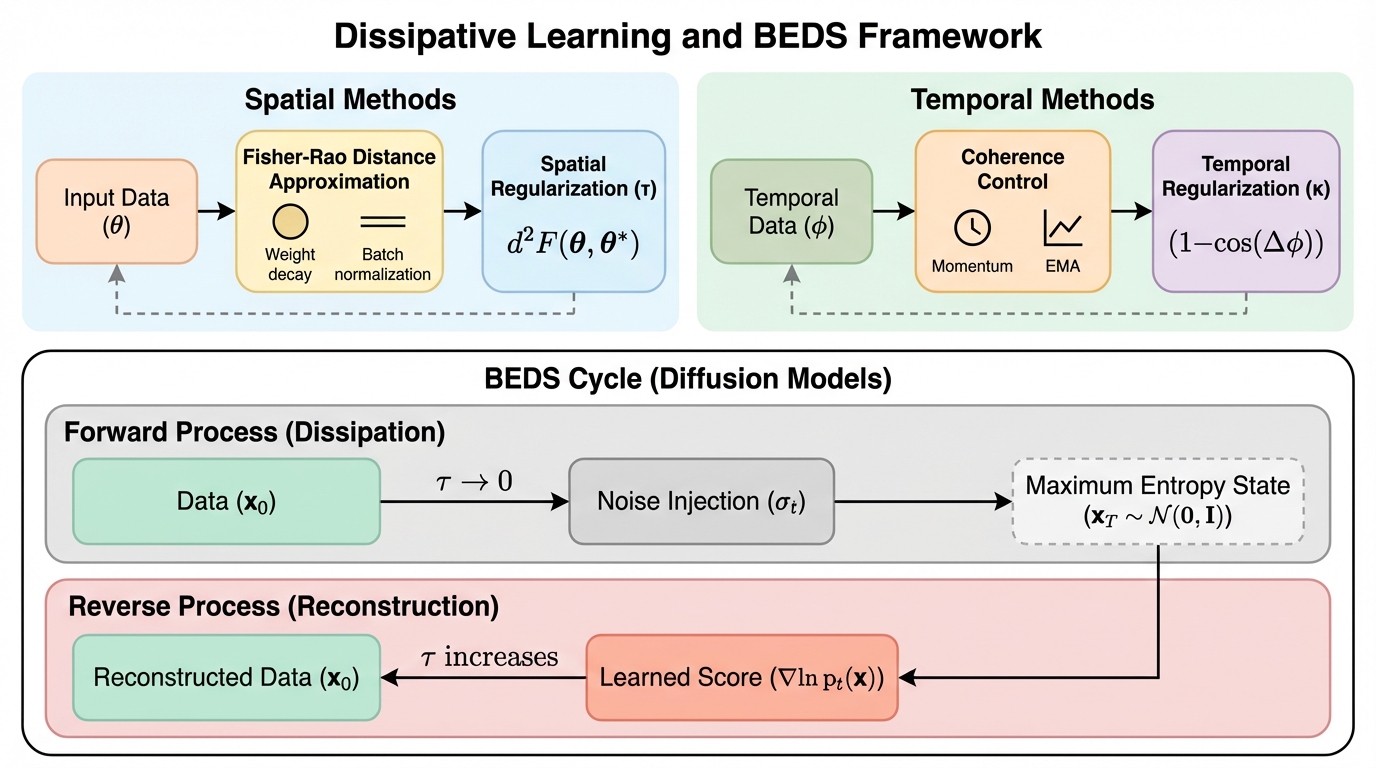
散逸学習:生存可能な適応システムのためのフレームワーク
学習を本質的にエネルギーを消費し情報を捨てる「散逸プロセス」と定義し、忘却や正則化をシステムの生存に不可欠な構造的要件として再構築するBEDSフレームワークを提案している。 情報幾何学と熱力学に基づき、フィッシャー・ラオ正則化が最小の散逸で学習を実現する唯一の最適戦略であることを理論的に証明し、既存の多様な機械学習手法を単一の方程式で統一的に説明することに成功した。 過学習を「過剰な結晶化」、壊滅的忘却を「散逸制御の不全」と捉え直し、有限のリソース下で精度と適応性のバランスを維持し続ける「生存可能性」を、従来の評価基準に代わる新たな指標として提示している。