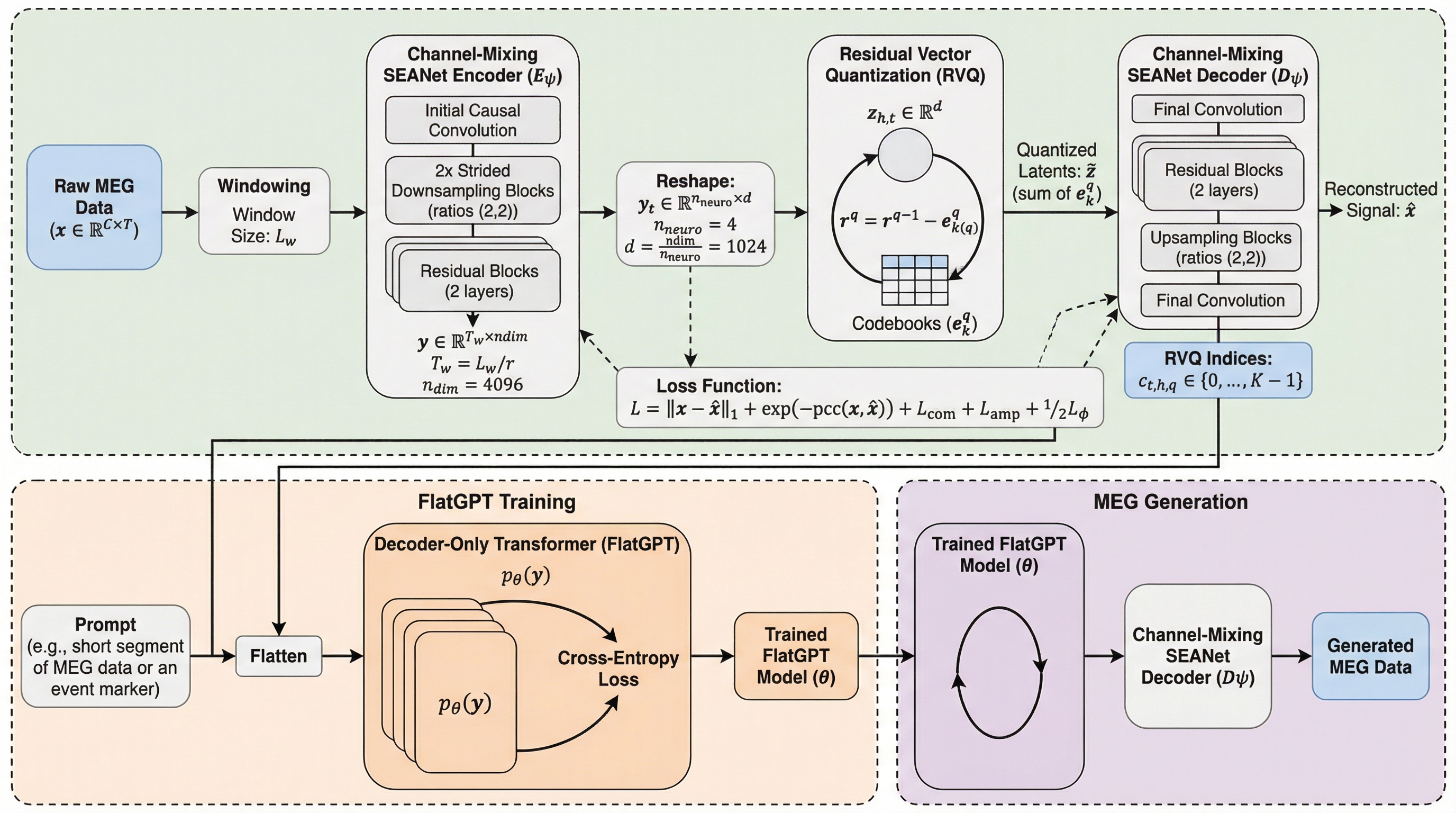
MEGのための次脳トークン予測のスケーリング
本研究では、500時間以上の大規模なMEG(磁気脳鳴図)データセットであるCamCAN、Omega、MOUSを統合し、多チャネルの脳信号を離散的なトークン列として予測する大規模自己回帰モデル「FlatGPT」を構築した。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
本研究では、500時間以上の大規模なMEG(磁気脳鳴図)データセットであるCamCAN、Omega、MOUSを統合し、多チャネルの脳信号を離散的なトークン列として予測する大規模自己回帰モデル「FlatGPT」を構築した。
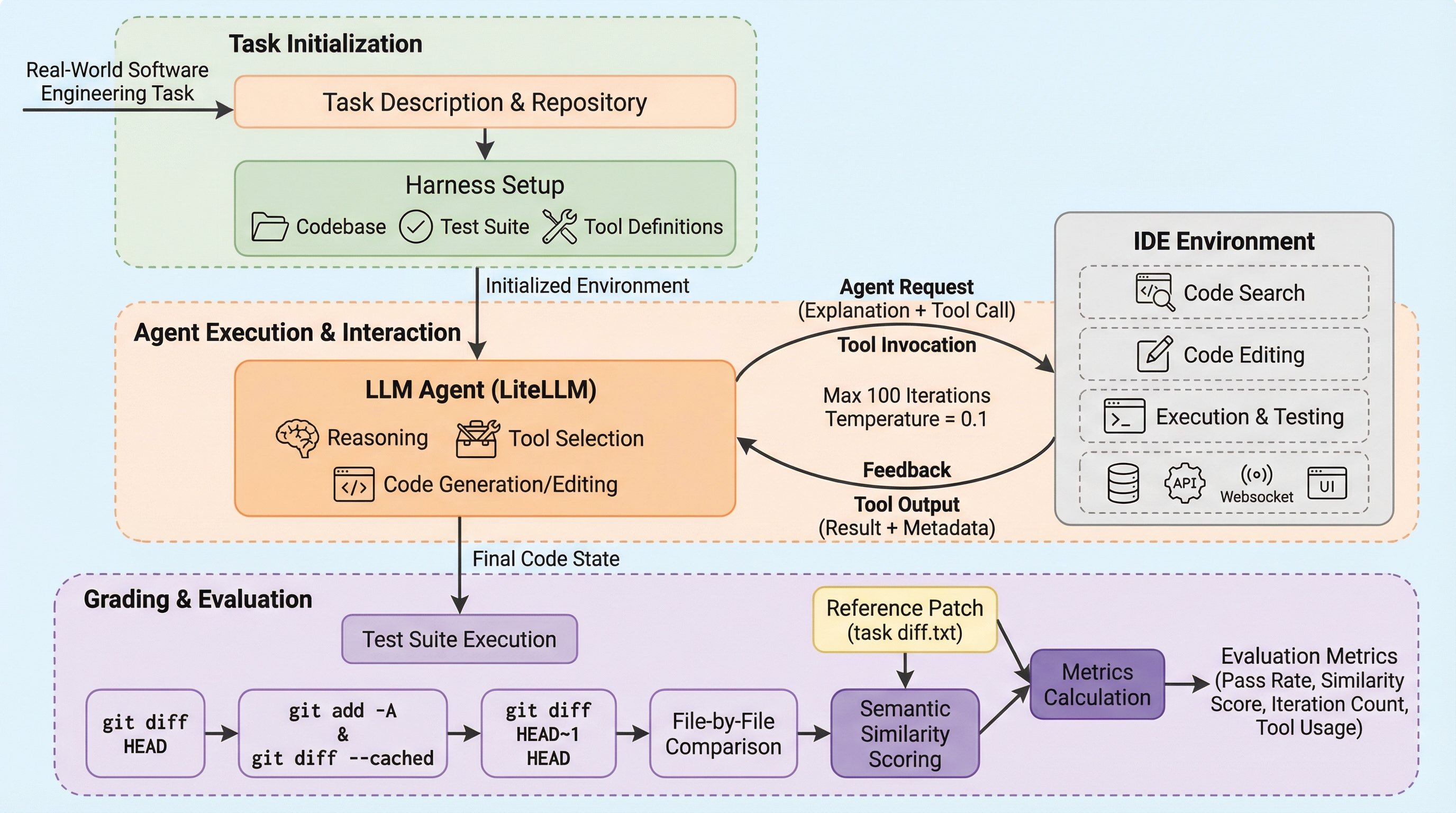
IDE-Benchは、CursorやWindsurfのようなAIネイティブIDEの動作を模した、LLMを「IDEエージェント」として評価するための新しいベンチマークフレームワークである。 学習データへの汚染を防ぐために作成された未公開の8つのリポジトリ(C/C++、Java、MERNスタック等)と80のタスクを用い、コード検索や編集、テスト実行といった17種類のツールを駆使した多段階の課題解決能力を厳密に測定する。 評価の結果、GPT 5.2が95%の成功率(pass@5)で首位となったが、多くのモデルで「アルゴリズムは正しいが形式や端的なケースで失敗する」という課題や、言語・フレームワークごとの得意不得意が顕著に現れた。
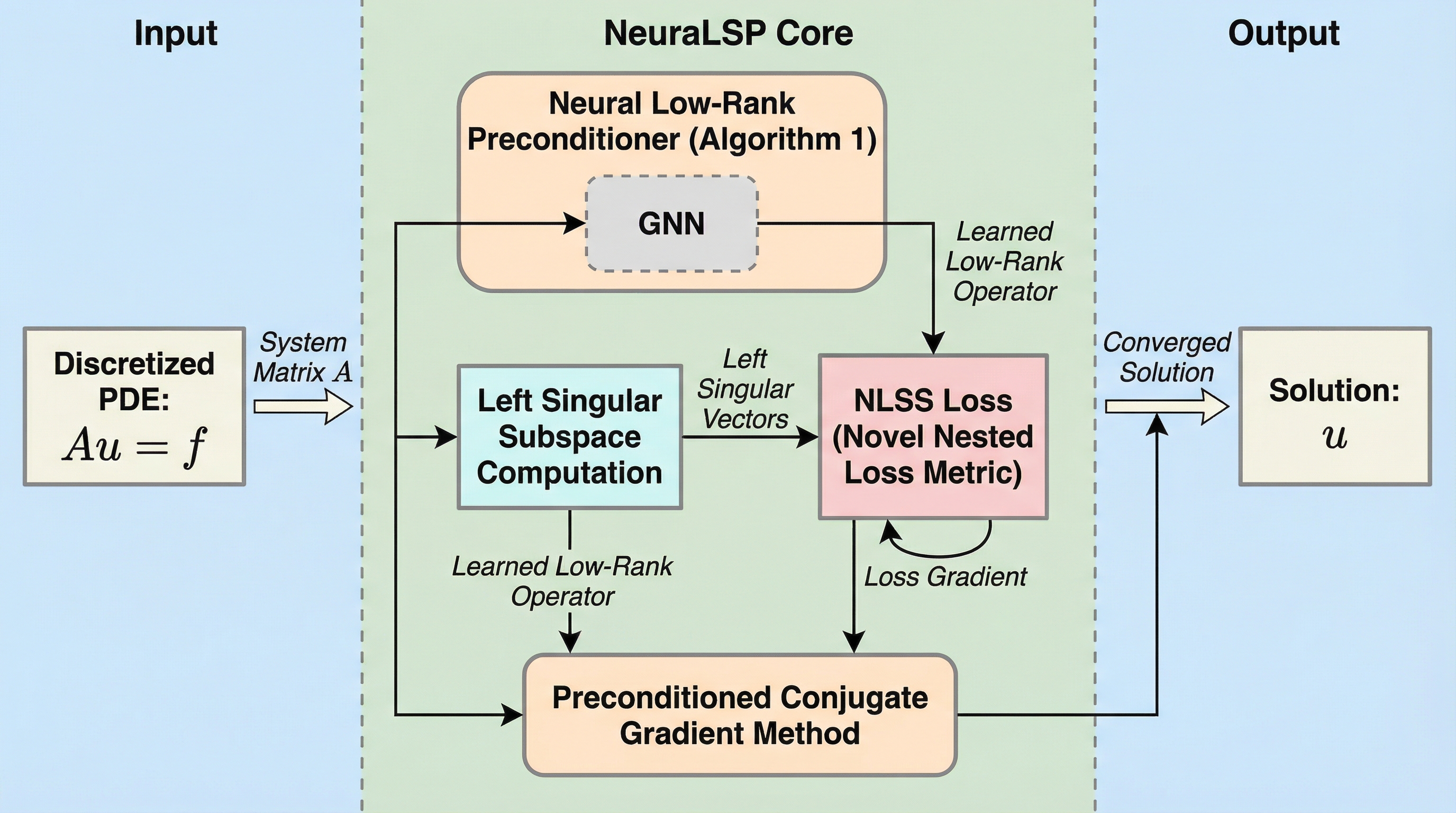
科学技術計算における偏微分方程式の数値解法を加速するため、従来の代数マルチグリッド法が抱えるランク膨張や収束率低下という課題を解決する新しいニューラルプリコンディショナ「NeuraLSP」が提案されました。
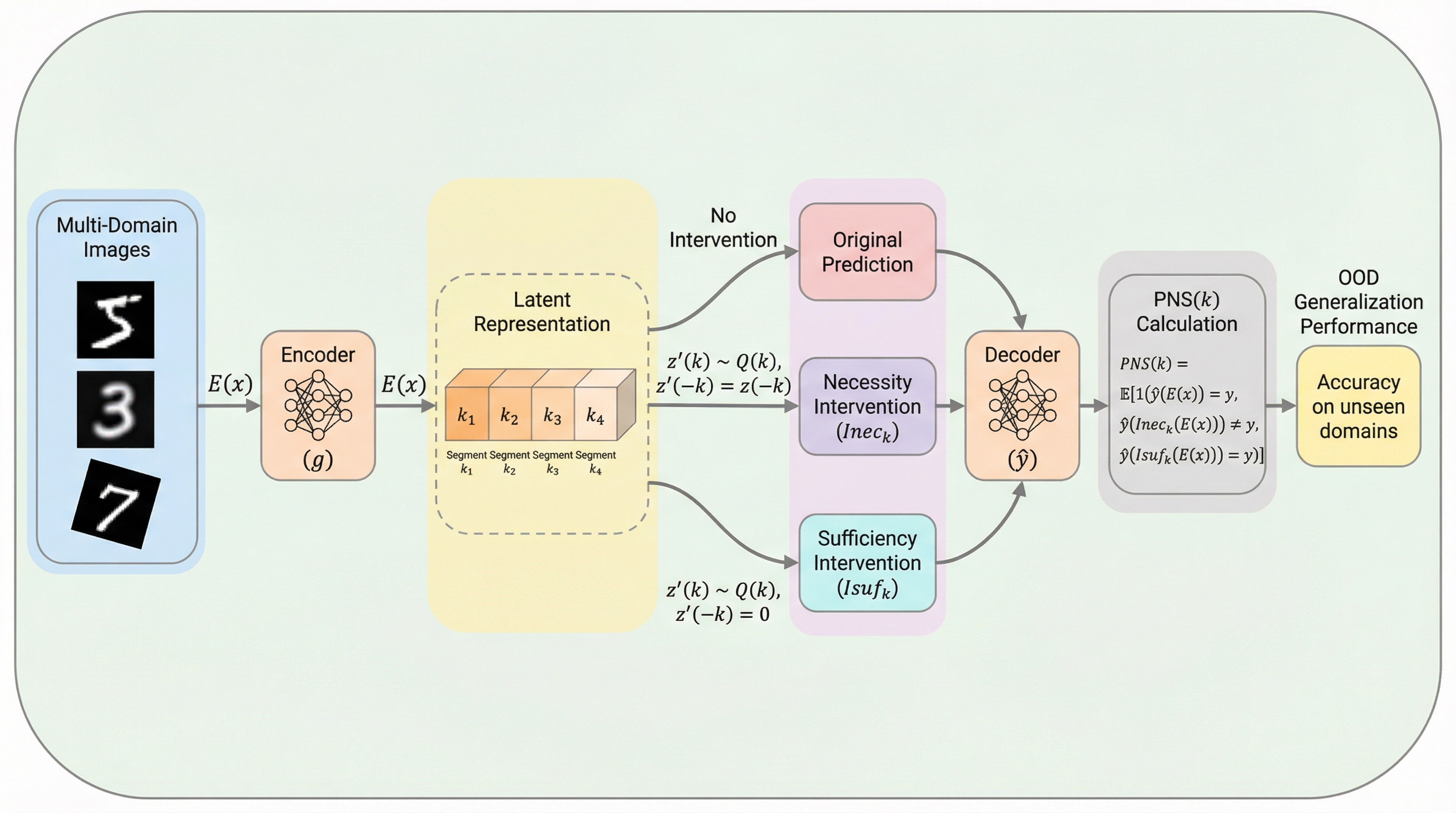
従来のドメイン汎化手法が依存していた「ドメイン間で不変な特徴は信頼できる」という仮定に対し、不変であっても予測に因果的な寄与をしない「偽の相関」が含まれる問題を指摘し、統計的な安定性ではなく因果的な有効性を評価の主軸に据える必要性を提唱しました。
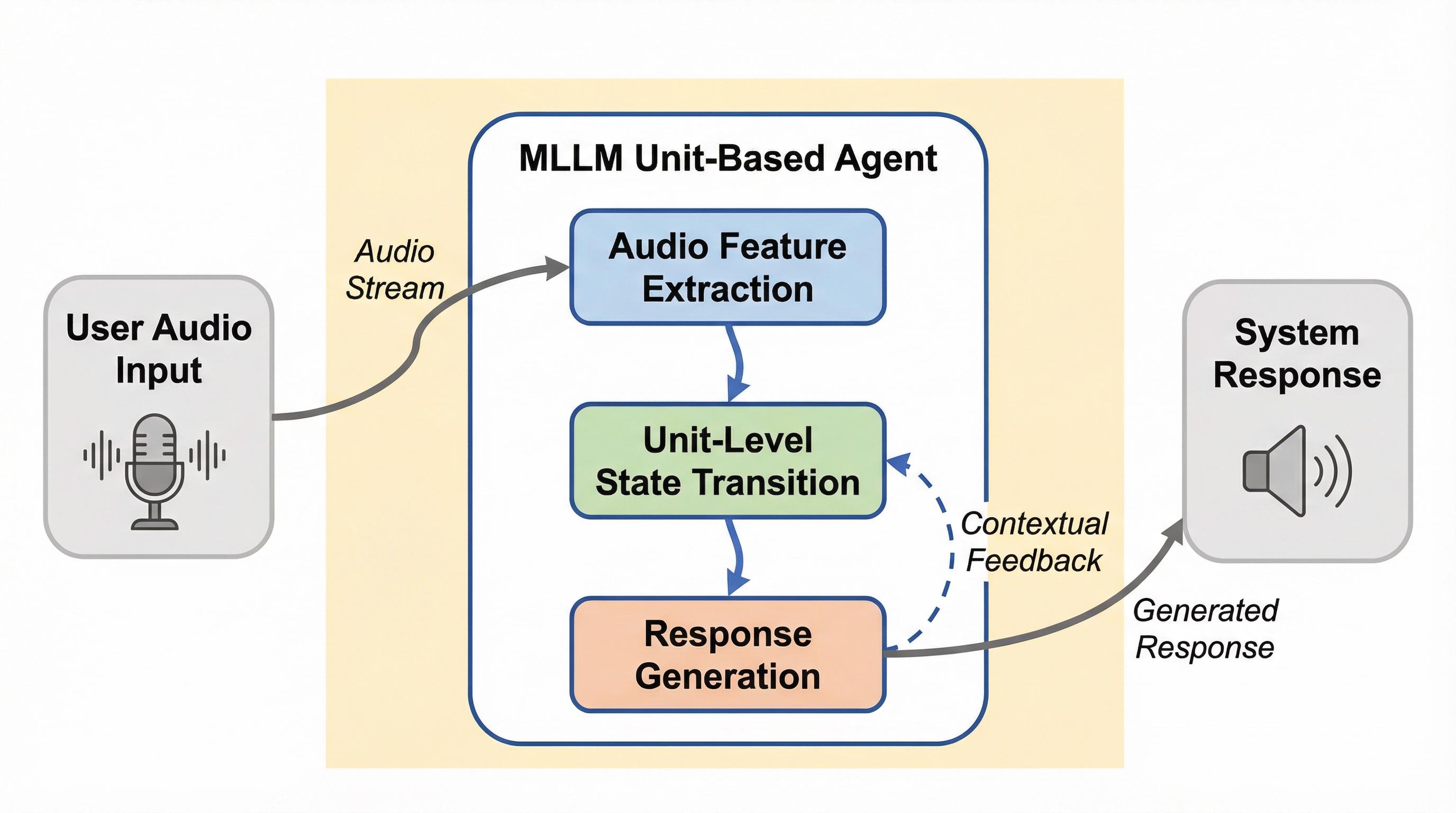
本研究では、複雑な音声対話を「対話ユニット」という最小単位に分解し、マルチモーダル大規模言語モデル(MLLM)が「継続」か「切り替え」かを判断することで、人間のように自然な同時双方向(全二重)対話を実現する新しいフレームワークを提案しました。
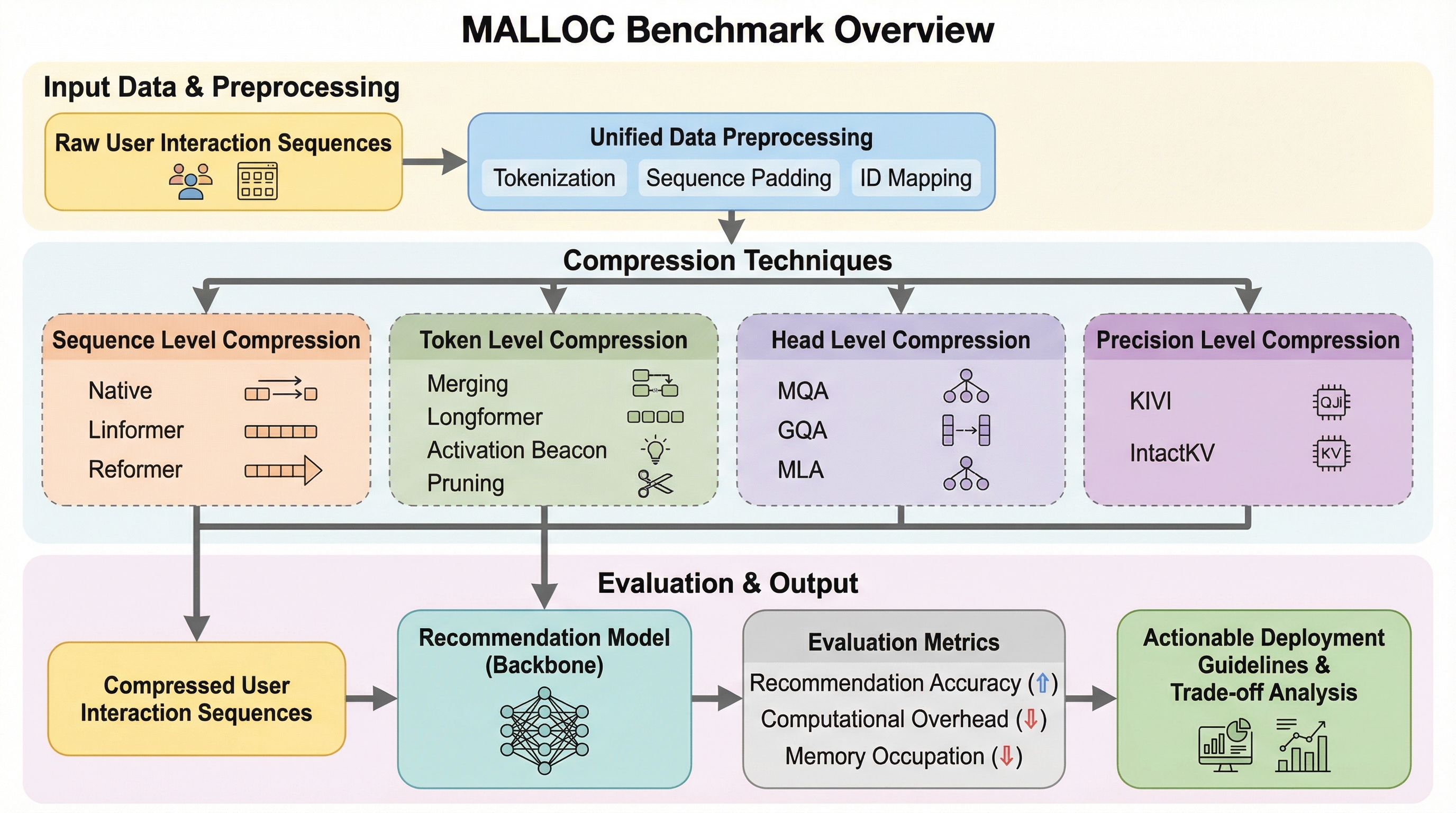
大規模推薦システムにおいて、ユーザーの長い行動履歴を処理する際の計算コストとメモリ消費の爆発的な増加(メモリ・レイテンシのジレンマ)を解決するため、メモリ効率を重視した長系列圧縮技術の包括的なベンチマークである「MALLOC」が提案されました。
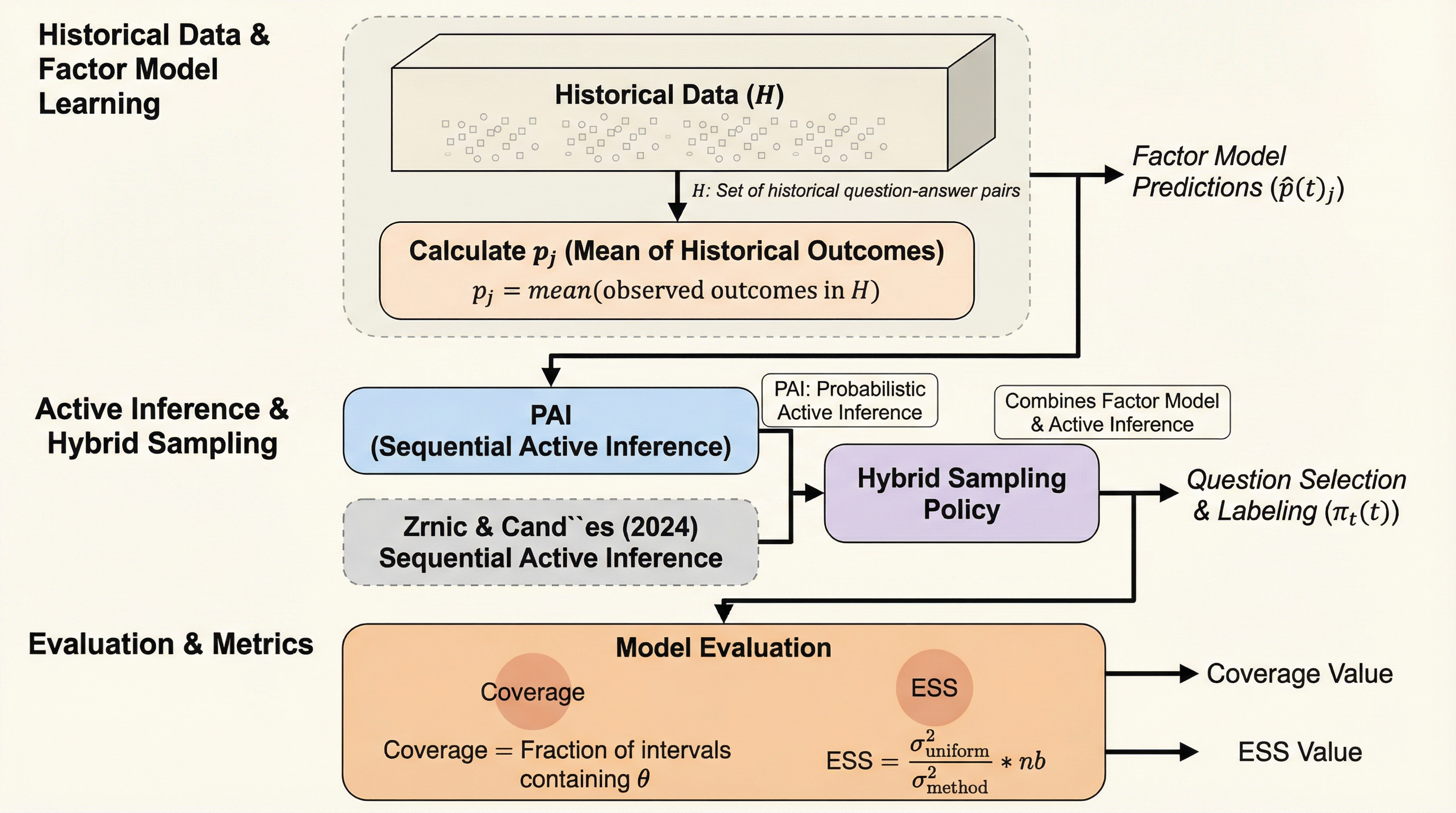
大規模言語モデル(LLM)の評価コストが急増する中、過去の評価データを活用して少ない質問数で高精度な性能推定を行う新手法「Factorized Active Querying (FAQ)」が開発されました。
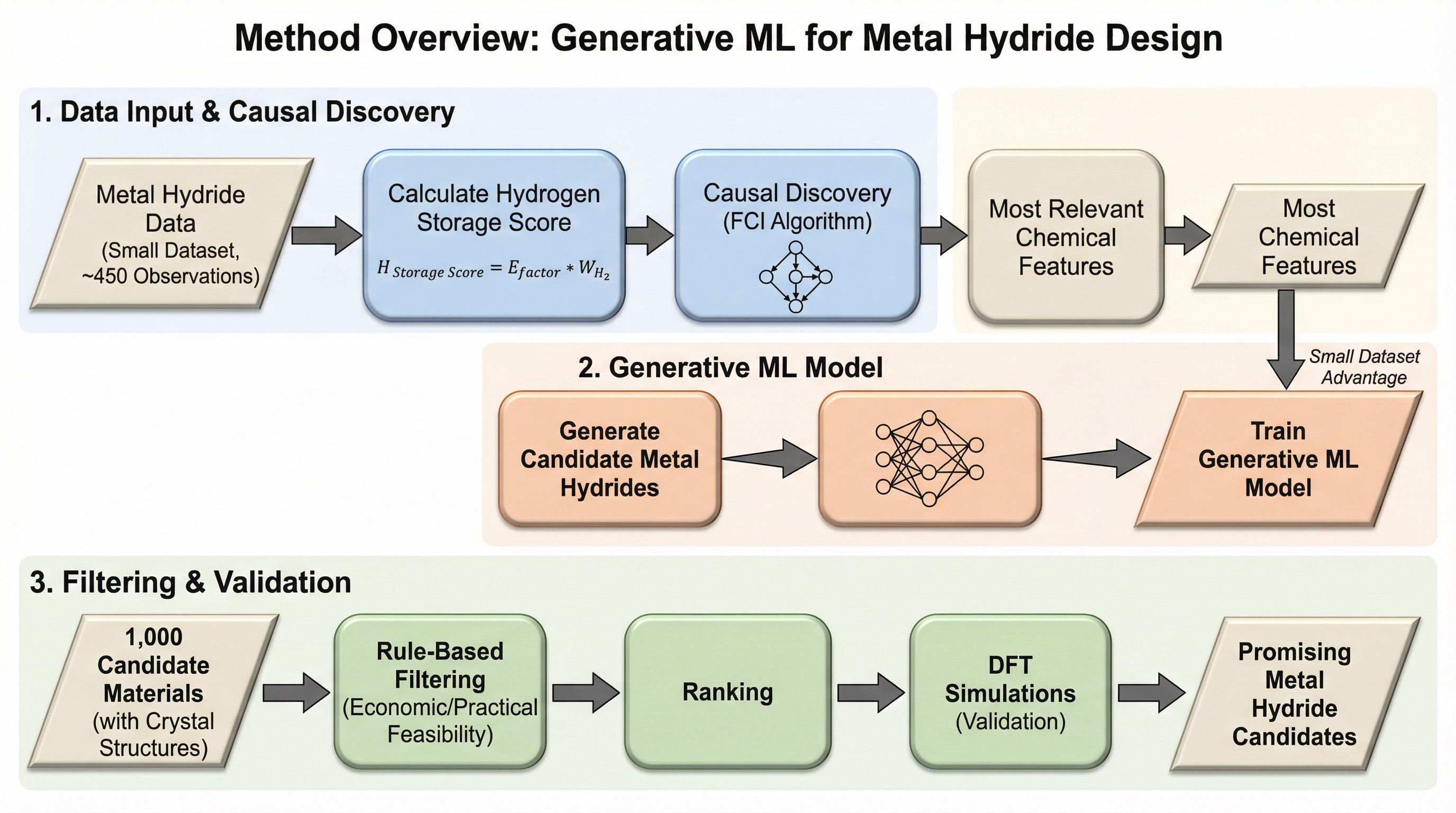
カーボンニュートラル実現に不可欠な水素貯蔵技術において、従来の実験や計算手法の限界を打破するため、因果探索アルゴリズム(FCI)と軽量な変分オートエンコーダ(VAE)を組み合わせた新しい材料設計フレームワークを開発しました。
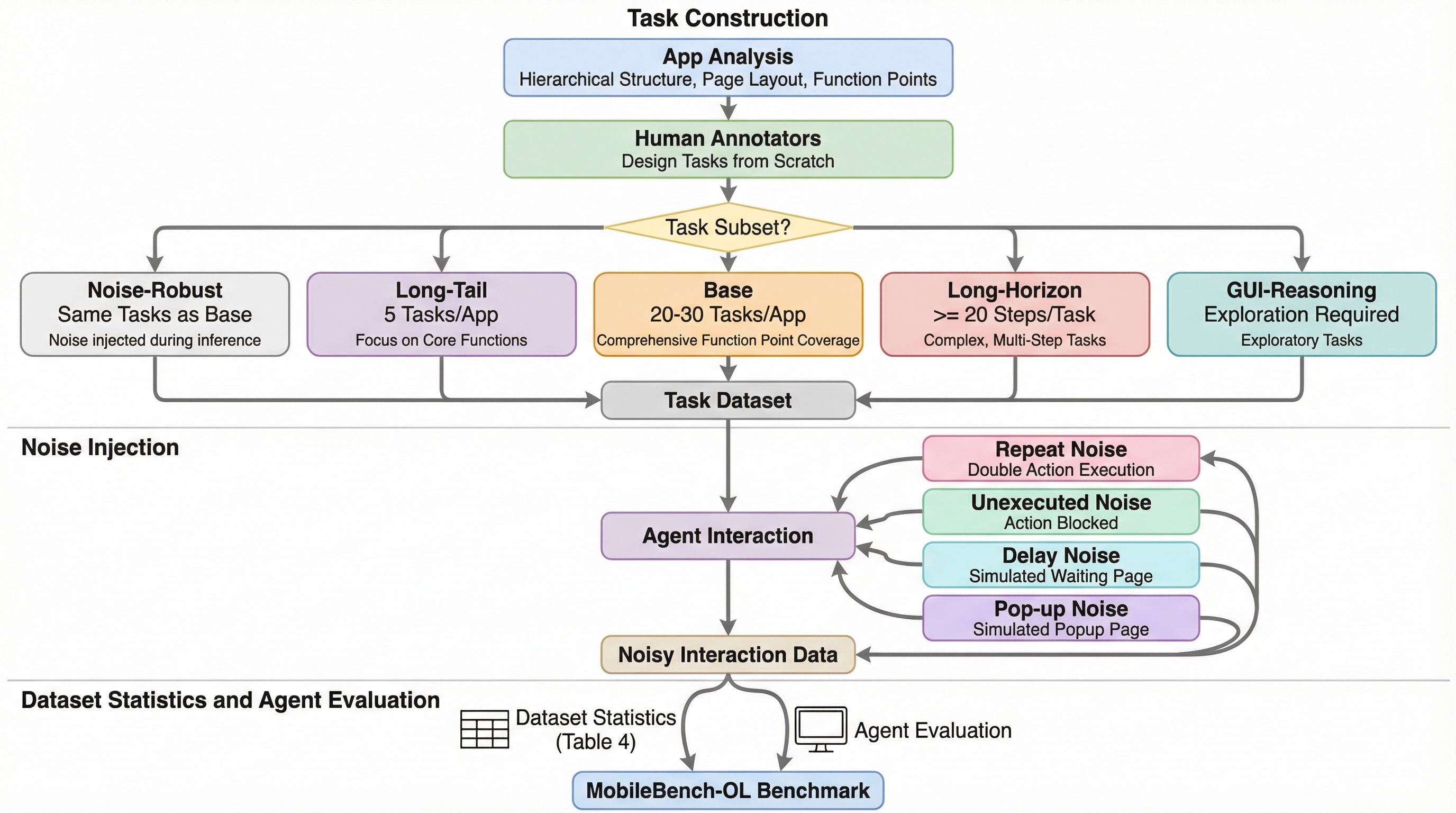
MobileBench-OLは、80個の中国語アプリから抽出された1080個のタスクで構成される、実環境におけるモバイルGUIエージェント評価のための包括的なオンラインベンチマークである。従来のベンチマークが単純な指示への追従に偏っていたのに対し、本手法は複雑な推論や自律的な探索能力、そして実環境特有のランダムなノイズへの対応力を多角的に測定する。 本ベンチマークは、20ステップ以上の長期タスクや隠れた機能の探索、ポップアップやネットワーク遅延といった4種類のノイズを含む5つのサブセットを提供し、エージェントの堅牢性を厳格に評価する。また、デバイスの状態を初期化するリセット機構を備えた自動評価フレームワークを導入することで、実機を用いた安定かつ再現可能な検証プロセスを確立している。 12種類の主要なGUIエージェントを用いた実験の結果、現在のモデルは実世界の複雑な要求に対して依然として大きな改善の余地があることが明らかになり、人間による評価でも本指標の信頼性が確認された。このデータセットは、学術的な評価と実世界でのデプロイメントの間に存在するギャップを埋め、次世代のモバイルエージェント開発を促進する基盤となる。
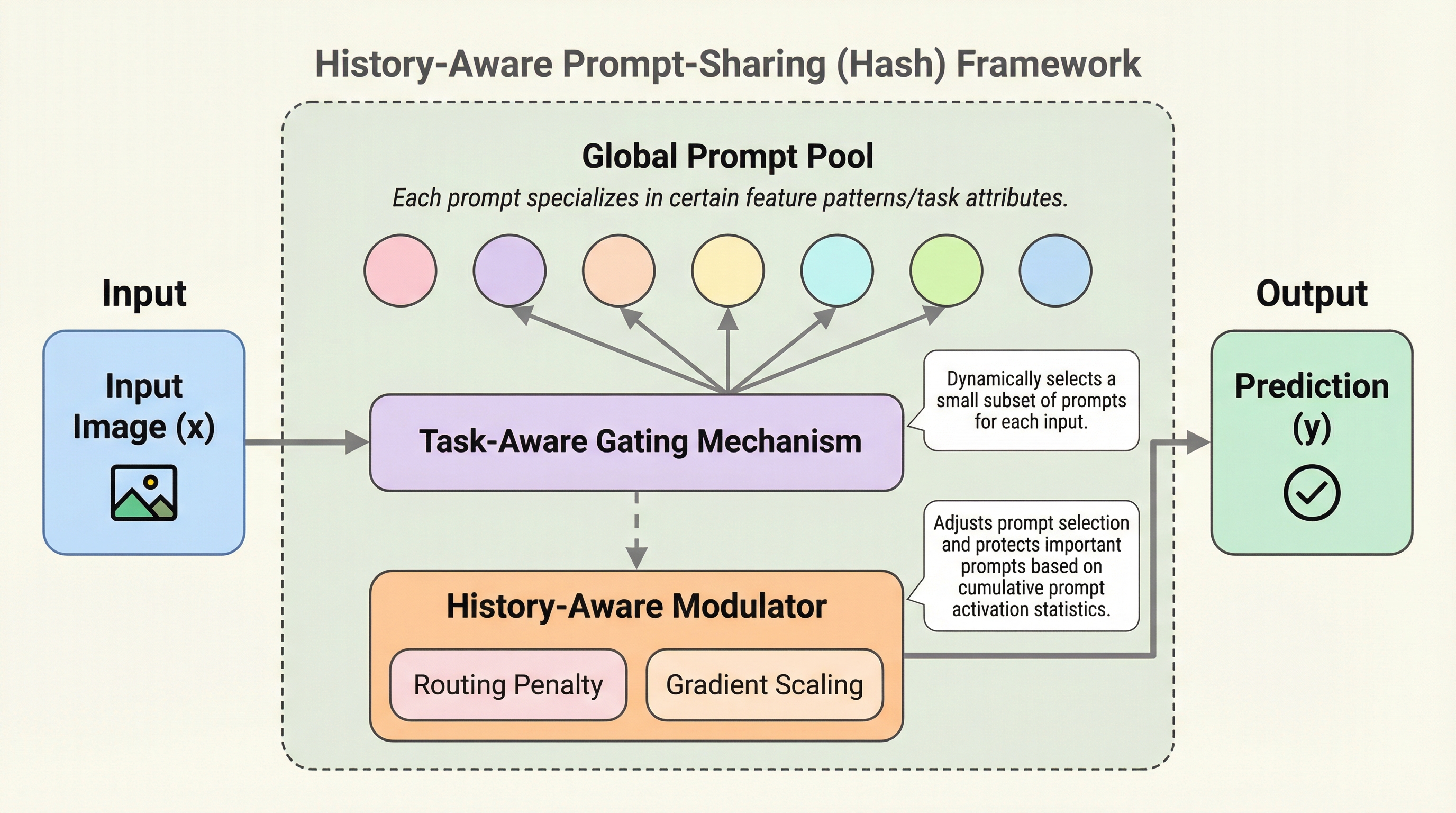
従来のプロンプトベース継続学習はタスクごとに独立したプロンプトを割り当てる手法が主流であったが、本研究では知識共有とパラメータ効率を向上させるために、グローバルなプロンプトプールを共有し、入力に応じて動的にプロンプトを選択するフレームワーク「Hash」を提案している。