概念成分分析:LLMにおける概念抽出のための原理的なアプローチ
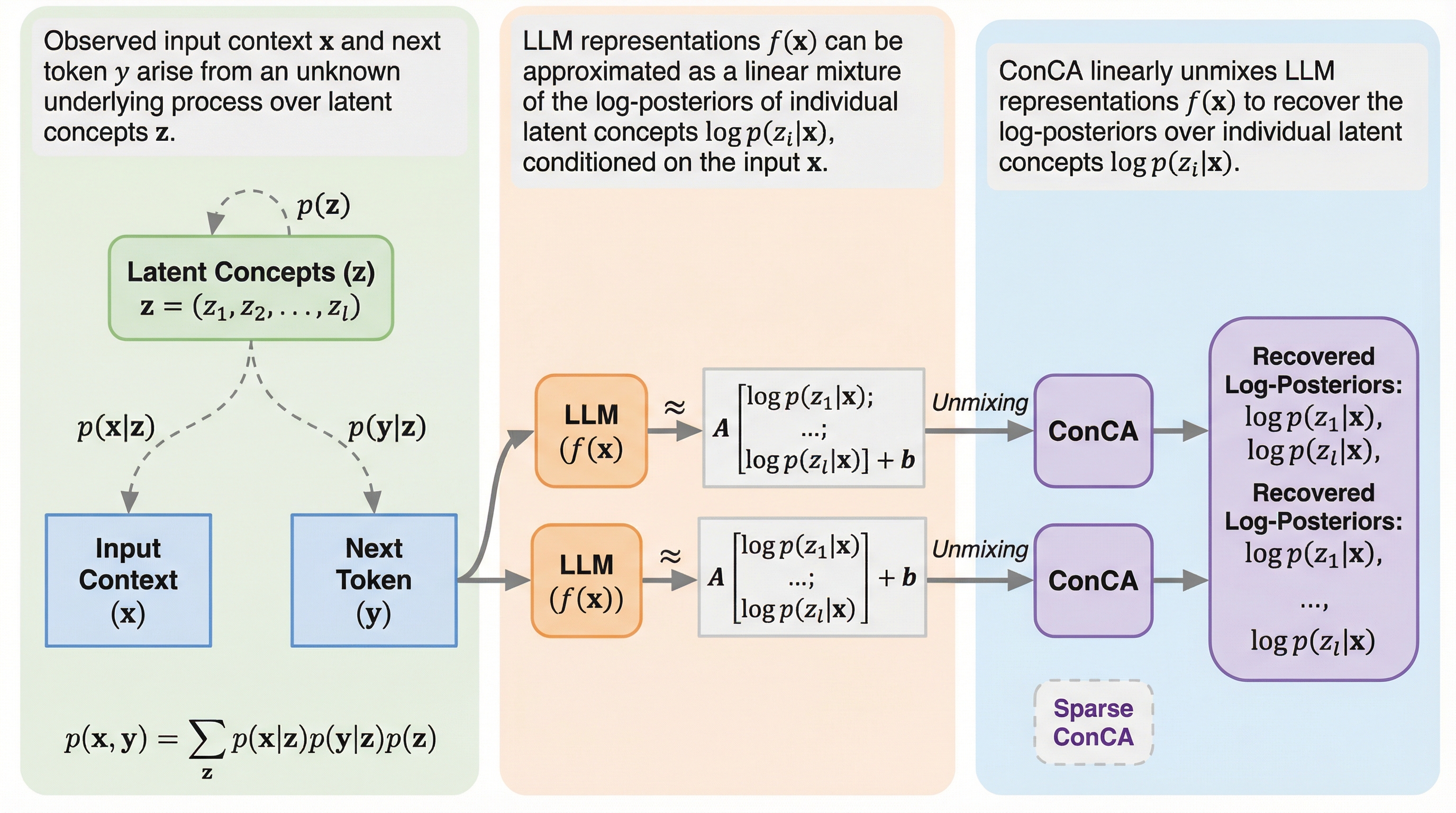
大規模言語モデル(LLM)の内部表現が、入力文脈における潜在的な概念の対数事後確率の線形混合として近似できることを理論的に証明し、この関係に基づき概念を抽出する「概念成分分析(ConCA)」を提案しました。
TL;DR(結論)
大規模言語モデル(LLM)の内部表現が、入力文脈における潜在的な概念の対数事後確率の線形混合として近似できることを理論的に証明し、この関係に基づき概念を抽出する「概念成分分析(ConCA)」を提案しました。 従来の自己符号化器(SAE)が経験的な仮説に依存していたのに対し、ConCAは数学的根拠に基づいて設計されており、スパース性を生の表現空間ではなく指数変換後の確率ドメインで課すことで、より正確な概念復元を可能にしています。 Pythia、Gemma3、Qwen3といった複数のモデルを用いた実験において、ConCAは113のデータセットにわたる下流タスクや反事実的テキストペアを用いた評価でSAEを上回る性能を示し、理論と実証の両面でその有効性が確認されました。
なぜこの問題か
大規模言語モデル(LLM)が社会の多種多様な領域で活用されるようになるにつれ、モデルがどのようなプロセスを経て意思決定を行っているのかを人間が理解可能な形で解釈することは、安全性と信頼性の観点から極めて重要な課題となっています。メカニスティックな解釈可能性の研究分野では、モデルの内部活性化から意味のある概念を抽出することで、この不透明性の解消を目指してきました。近年、そのための主要な手法として「稀な自己符号化器(SAE)」が広く採用されています。SAEは、LLMの内部表現を膨大な辞書成分に分解することで、単一の意味を持つ「モノセマンティック」な概念を取り出そうとする試みです。しかし、SAEの設計と成功は、主に「線形表現仮説」と「重ね合わせ仮説」という2つの経験的な仮説に基づいています。前者は概念がモデル内で線形に符号化されているという考えであり、後者はモデルが限られたニューロン数以上の特徴を表現するために、それらを重ね合わせて保持しているという考えです。…
核心:何を提案したのか
本研究の最大の貢献は、LLMの表現と人間が理解可能な概念との間の理論的な関係を定義し、それに基づいた「概念成分分析(Concept Component Analysis: ConCA)」という原理的な枠組みを提案したことです。研究チームはまず、テキストデータが未知の潜在的な概念によって生成されるという「潜在変数モデル(LVM)」の観点から、この関係を数学的に分析しました。ここでは、概念を離散的な潜在変数として定義し、それらがテキストの生成プロセスを制御していると仮定しています。この分析の結果、次単語予測によって学習されたLLMの内部表現は、穏やかな仮定の下で、入力文脈が与えられたときの各潜在概念の「対数事後確率」の線形混合として近似できることが証明されました。これは、LLMの内部に蓄積された数値群が、単なる抽象的な特徴ではなく、統計的な意味を持つ概念の確率分布に基づいていることを示唆する画期的な洞察です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related