統計的保証を伴うLLM性能評価の効率化
大規模言語モデル(LLM)の評価コストが急増する中、過去の評価データを活用して少ない質問数で高精度な性能推定を行う新手法「Factorized Active Querying (FAQ)」が開発されました。
TL;DR(結論)
大規模言語モデル(LLM)の評価コストが急増する中、過去の評価データを活用して少ない質問数で高精度な性能推定を行う新手法「Factorized Active Querying (FAQ)」が開発されました。 この手法は、ベイズ因子モデルによる予測と能動的学習、さらに統計的妥当性を厳密に保証する「Proactive Active Inference (PAI)」を組み合わせることで、信頼区間の幅を維持したままクエリ数を最大5倍削減することに成功しています。 有限母集団に対する頻度主義的な被覆率を保証しており、APIコストや専門家による評価負荷を大幅に軽減しながら、モデルの正確な能力把握と迅速な意思決定を支援する画期的な枠組みとなっています。
なぜこの問題か
現在、大規模言語モデル(LLM)は医療、法律、教育といった専門性の高い重要な分野での導入が急速に進んでおり、それに伴い組織が評価・監視すべきモデルの数も爆発的に増加しています。 HuggingFaceのような公開プラットフォームには186万以上のモデルが存在し、そのうちテキスト生成タグが付与されたものだけでも30万を超えており、特定のベースモデルを微調整した派生モデルが日々大量に生み出されているのが現状です。 民間企業においても、内部で数百から数千のモデルバリエーションを保持することが珍しくなく、それぞれのモデルがクエリに依存した独自の強みや弱みを持っているため、これらを正確に評価することは極めて困難な課題となっています。 一般的な慣行として、候補となるモデルの性能を特定のベンチマークセットで評価しますが、これらのセットには専門家による高価な判定が必要な問題や、多段階の対話、長文の推論と検証を必要とする問題が増えています。…
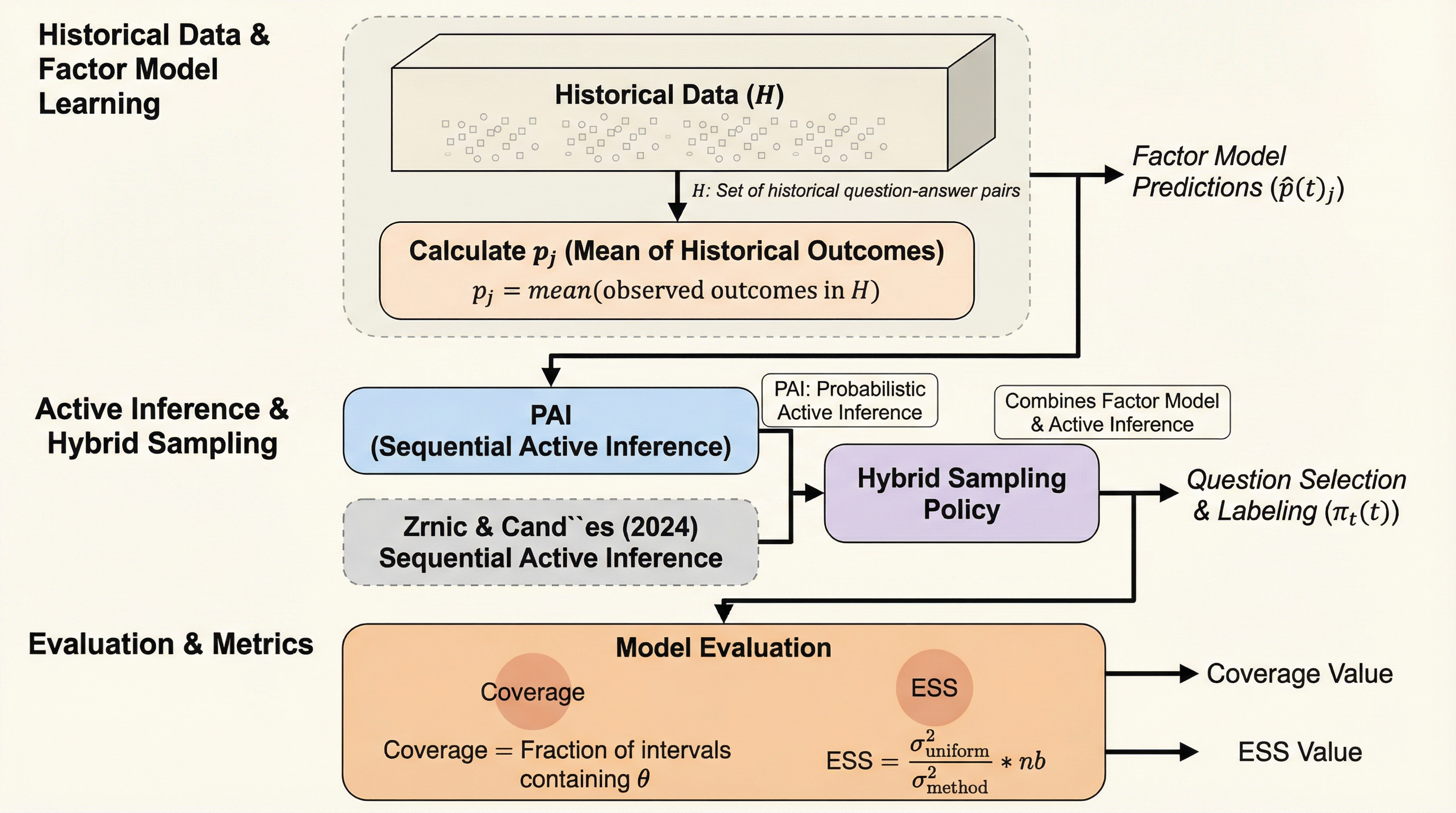
核心:何を提案したのか
本論文では、統計的な保証を維持しながらLLMの評価を劇的に効率化する手法として「Factorized Active Querying (FAQ)」を提案しています。 FAQの核心は、ベンチマーク評価を「有限母集団推論」の問題として捉え直し、固定されたクエリ予算の下で、モデルの精度に対して可能な限り狭い信頼区間を構築することにあります。 この手法は、過去の不完全な評価データから情報を抽出するベイズ因子モデル、分散減少と能動的学習を組み合わせたハイブリッドなサンプリングポリシー、そして統計的妥当性を守るための新しい枠組みである「Proactive Active Inference (PAI)」の3つの要素で構成されています。 最大の特徴は、従来のランダムサンプリングと比較して、同じ信頼区間の幅を維持しながらクエリ数を最大5倍削減できるという高い効率性にあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related