IDE-Bench: 実世界のソフトウェア開発タスクにおけるIDEエージェントとしてのLLM評価
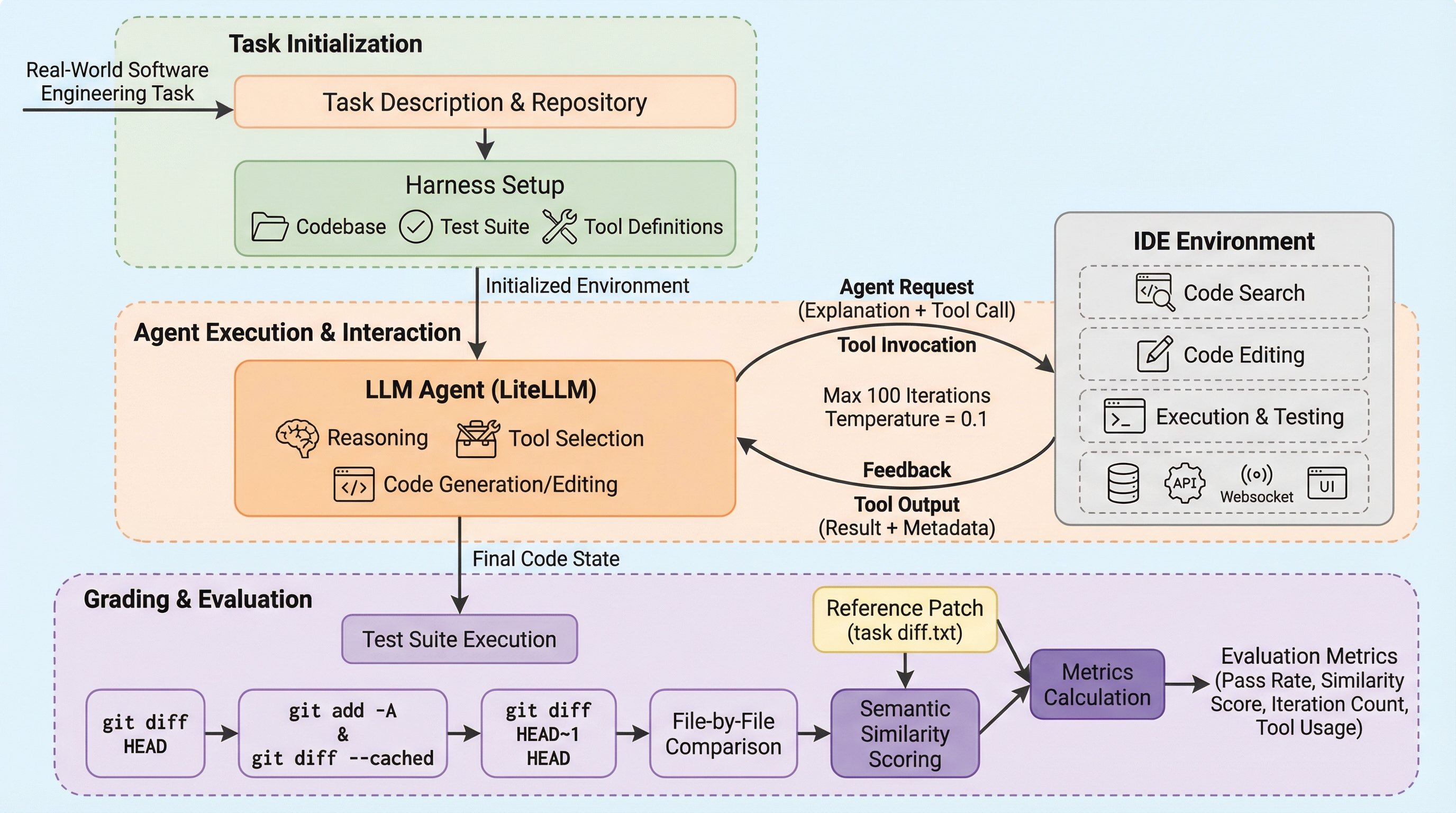
IDE-Benchは、CursorやWindsurfのようなAIネイティブIDEの動作を模した、LLMを「IDEエージェント」として評価するための新しいベンチマークフレームワークである。 学習データへの汚染を防ぐために作成された未公開の8つのリポジトリ(C/C++、Java、MERNスタック等)と80のタスクを用い、コード検索や編集、テスト実行といった17種類のツールを駆使した多段階の課題解決能力を厳密に測定する。 評価の結果、GPT 5.2が95%の成功率(pass@5)で首位となったが、多くのモデルで「アルゴリズムは正しいが形式や端的なケースで失敗する」という課題や、言語・フレームワークごとの得意不得意が顕著に現れた。
TL;DR(結論)
IDE-Benchは、CursorやWindsurfのようなAIネイティブIDEの動作を模した、LLMを「IDEエージェント」として評価するための新しいベンチマークフレームワークである。 学習データへの汚染を防ぐために作成された未公開の8つのリポジトリ(C/C++、Java、MERNスタック等)と80のタスクを用い、コード検索や編集、テスト実行といった17種類のツールを駆使した多段階の課題解決能力を厳密に測定する。 評価の結果、GPT 5.2が95%の成功率(pass@5)で首位となったが、多くのモデルで「アルゴリズムは正しいが形式や端的なケースで失敗する」という課題や、言語・フレームワークごとの得意不得意が顕著に現れた。
なぜこの問題か
近年、CursorやGitHub Copilotといったエージェント機能を備えたIDEの普及により、ソフトウェア開発のワークフローは劇的に変化している。2025年7月時点でGitHub Copilotの利用者は2,000万人を超え、Cursorの有料顧客も2025年11月までに36万人を突破した。開発者はこれらのツールを日常的なタスクに統合し、コードの反復作業を減らして生産性を向上させている。しかし、既存のLLM評価ベンチマークには、実際の開発者が直面するデバッグ、リファクタリング、機能開発、フルスタックのワークフローを、ツール呼び出しを通じて厳密にテストできるものが存在しなかった。 例えば、既存のSWE-BenchはGitHubのIssueやプルリクエストを利用しているが、モデルにIDE環境へのアクセスを許可しておらず、静的なコンテキスト取得が性能のボトルネックとなるシングルショットのパラダイムで評価を行っている。また、Terminal-Benchはターミナル操作の評価には優れているが、コードベースのインデックス作成やIDEレベルのナビゲーションといった、より高次のIDEネイティブな振る舞いを測定することはできない。…
核心:何を提案したのか
本論文は、実世界のソフトウェアエンジニアリングタスクにおいて、LLMをIDEエージェントとして評価するための包括的なフレームワーク「IDE-Bench」を提案している。このフレームワークの最大の特徴は、AIネイティブなIDEが提供する抽象化されたツールインターフェースをモデルに提供し、実際の開発環境を模したDockerコンテナ内でタスクを実行させる点にある。評価対象となるのは、単なるコード生成能力だけでなく、ツールを呼び出してコードベースを探索し、問題を特定して修正し、テストで検証するという一連の自律的なエージェント能力である。 IDE-Benchには、学習データへの汚染を完全に排除するために、インターネットやGitHubなどの公開プラットフォームに一度も掲載されたことのない8つの新規リポジトリが含まれている。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related