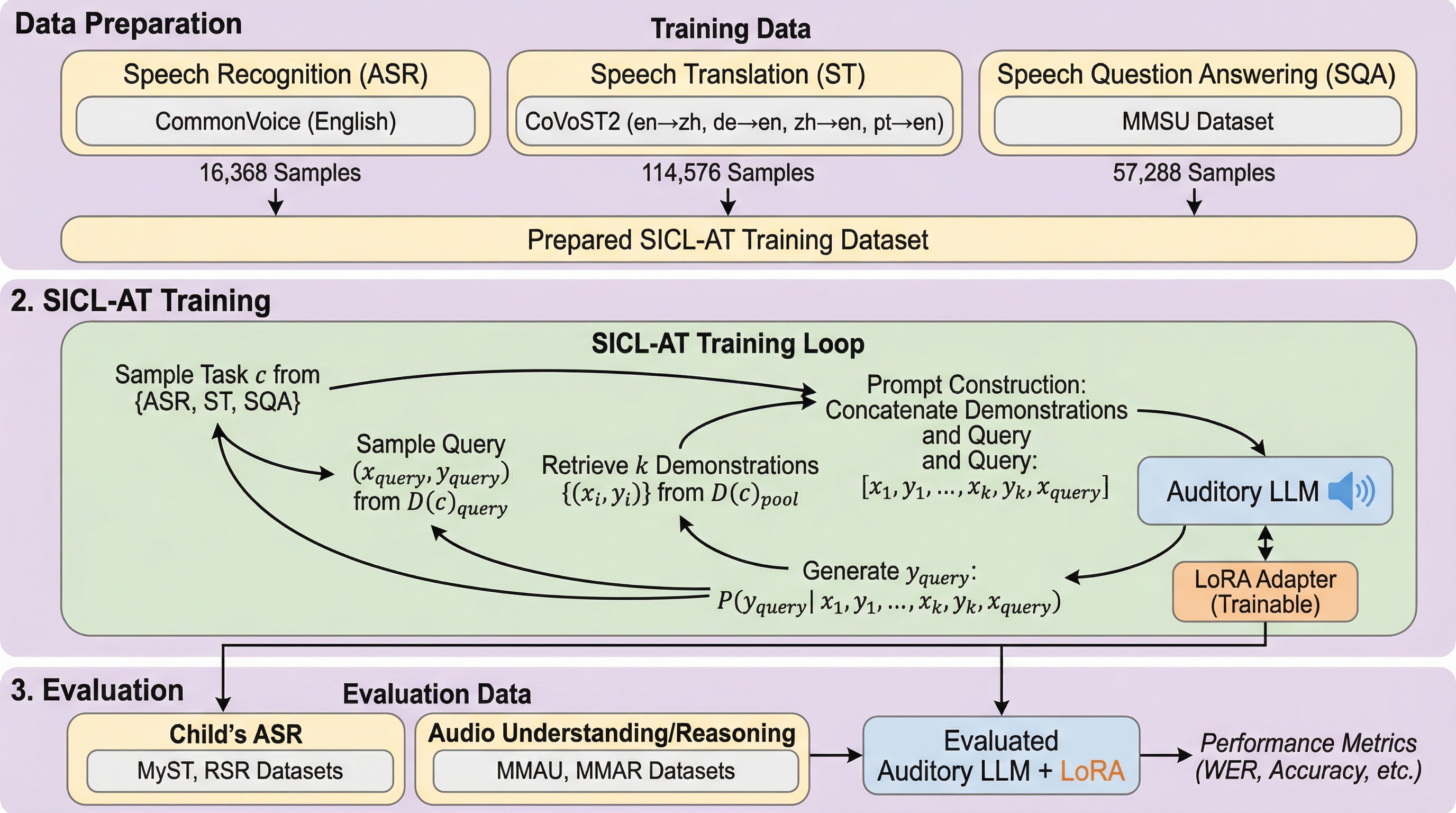
SICL-AT:聴覚LLMを低リソースタスクに適応させる新手法
聴覚大規模言語モデル(Auditory LLM)は、子供の音声認識や複雑な音声推論といったデータが乏しい低リソースタスクにおいて、直接的な微調整を行うと過学習や分布の不一致により性能が不安定になるという課題を抱えています。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
聴覚大規模言語モデル(Auditory LLM)は、子供の音声認識や複雑な音声推論といったデータが乏しい低リソースタスクにおいて、直接的な微調整を行うと過学習や分布の不一致により性能が不安定になるという課題を抱えています。
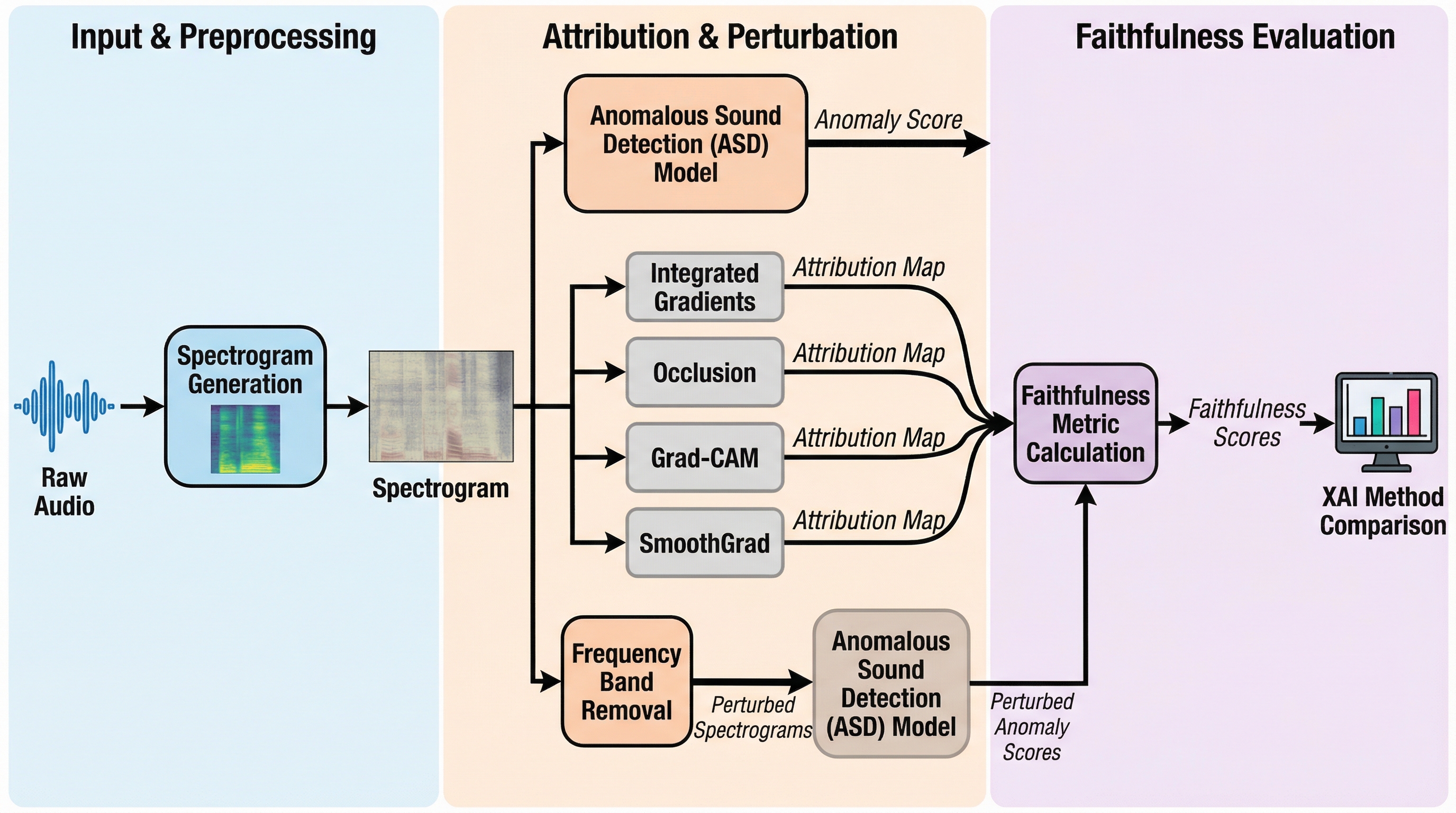
機械の異常音検知(ASD)において、AIの判断根拠を可視化する説明可能AI(XAI)がモデルの実際の挙動をどれだけ正確に反映しているか(忠実度)を定量的に評価する新しいフレームワークが提案されました。
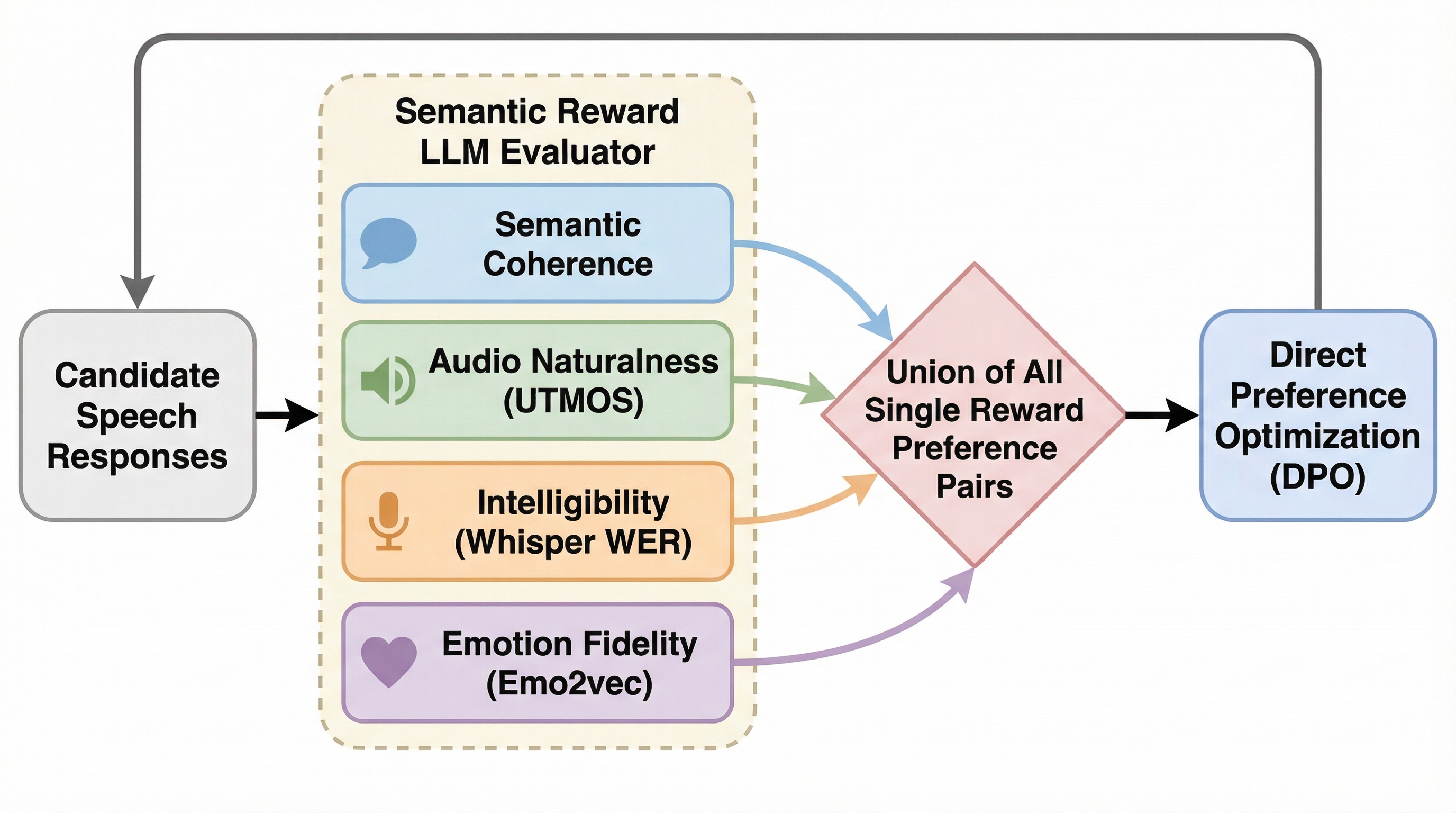
従来の音声対話システムにおける強化学習は、主に発話レベルの単一な意味的報酬に限定されており、音声の自然さや感情の一貫性といった多面的な品質を十分に最適化できていませんでした。本研究では、意味的な整合性に加えて、音声品質(UTMOS)、明瞭性(WER)、感情の一貫性という複数の報酬を統合した、音声入出力対話システムのための新しいマルチ報酬RLAIFフレームワークを提案しています。この手法は、逐次的に応答を生成するデュプレックス(全二重)モデルにも対応しており、複数の評価指標において一貫した品質向上を実現するとともに、研究の再現性を支援するための大規模なデータセットも公開されます。
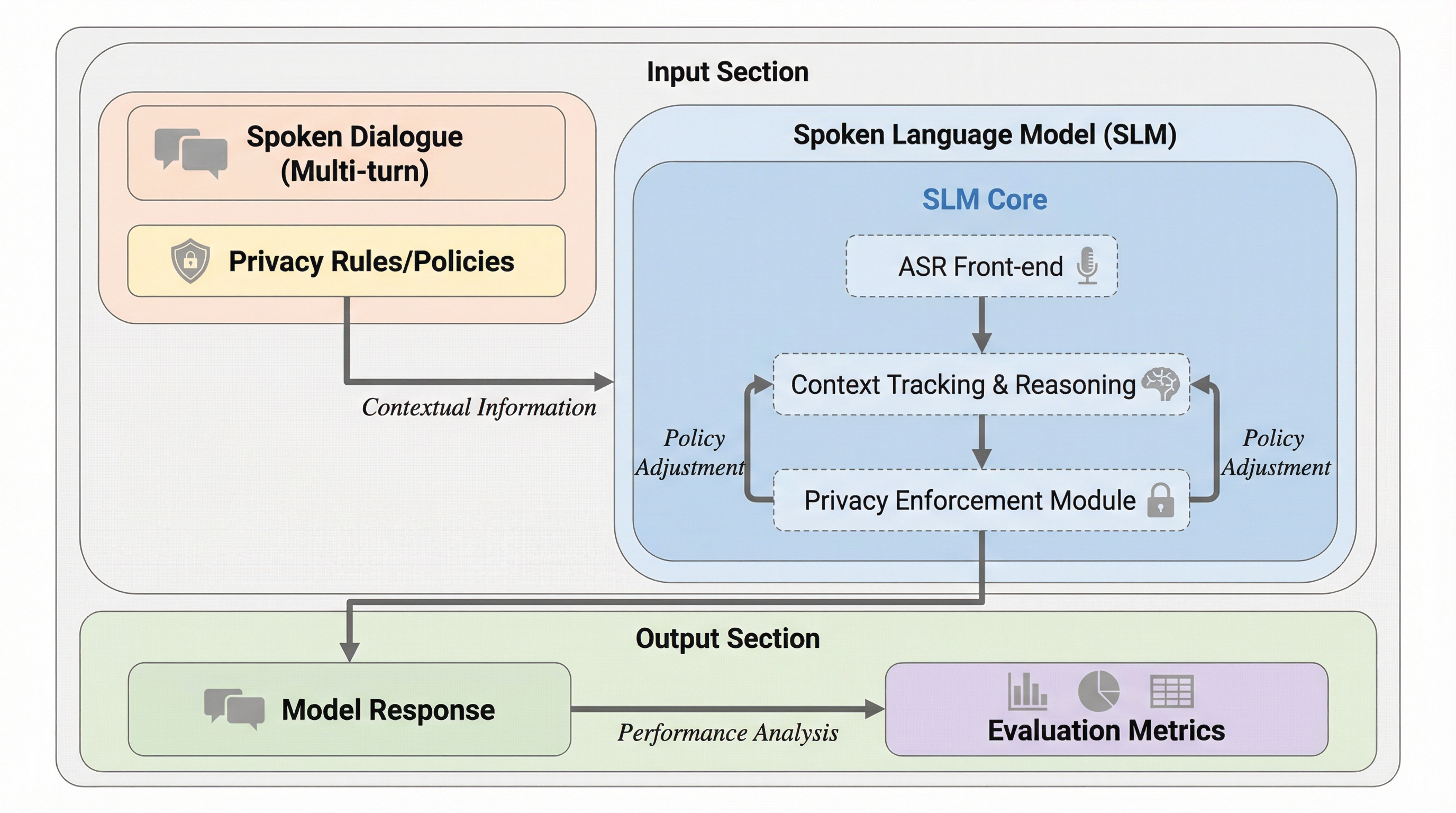
音声言語モデル(SLM)がスマートホーム等の共有環境で、特定の利用者の機密情報を他者に漏洩させる「対話的プライバシー」の欠如を評価するための専用ベンチマーク「VoxPrivacy」が提案された。
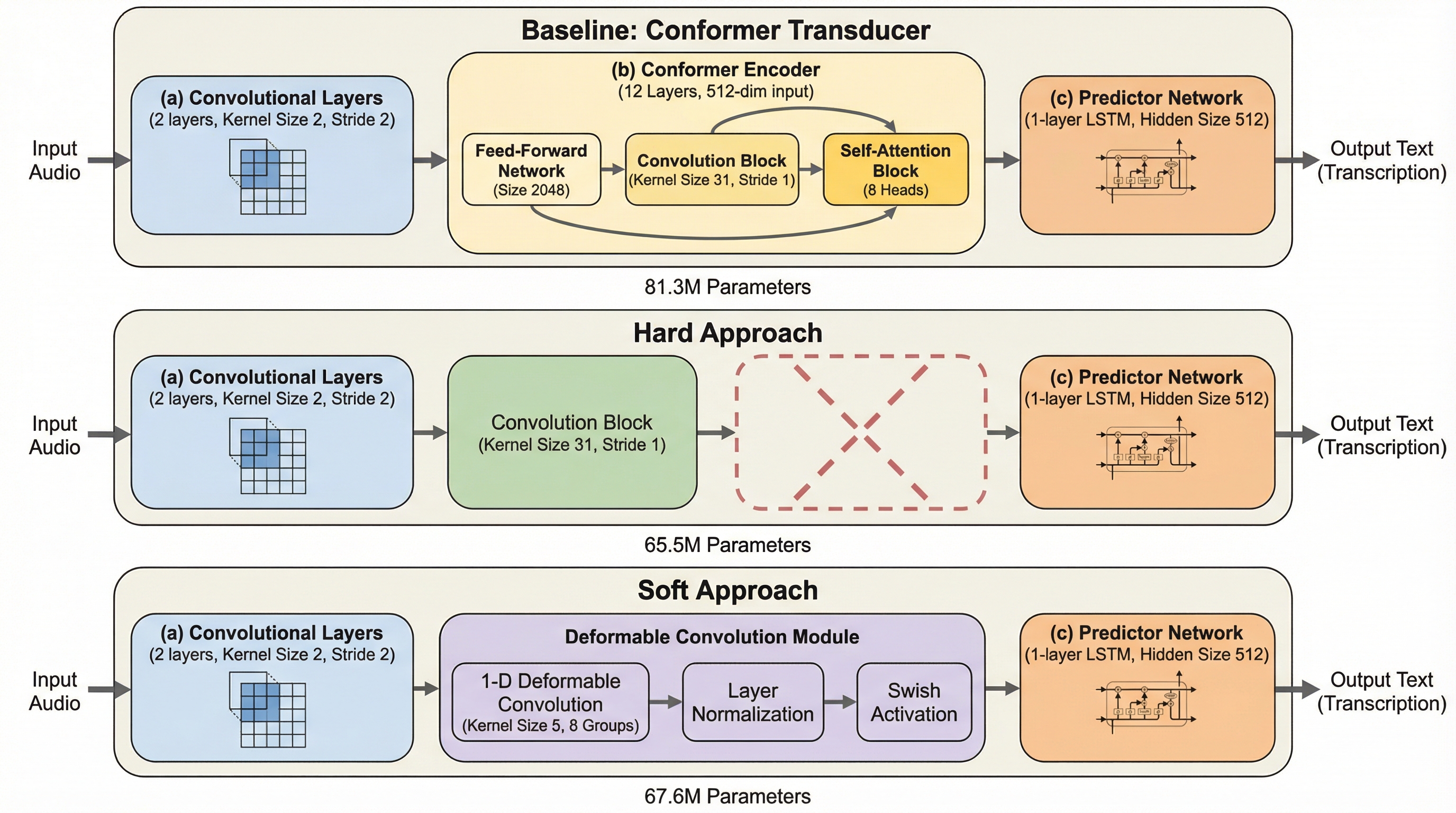
ストリーミング自動音声認識(ASR)において、Self-Attentionは全域的な依存関係を捉える設計でありながら、実際にはチャンク内の局所的な情報処理に終始していることが判明しました。 本研究では、Self-Attentionを軽量な可変形畳み込み(Deformable Convolution)に置き換える「ソフト手法」と、完全に削除する「ハード手法」を提案し、計算コストを大幅に削減しました。 LibriSpeech等のデータセットを用いた検証の結果、単語誤り率(WER)の悪化を最小限に抑えつつ、パラメータ数を最大19.4%削減し、GPU上での処理速度を約2倍に高速化することに成功しました。
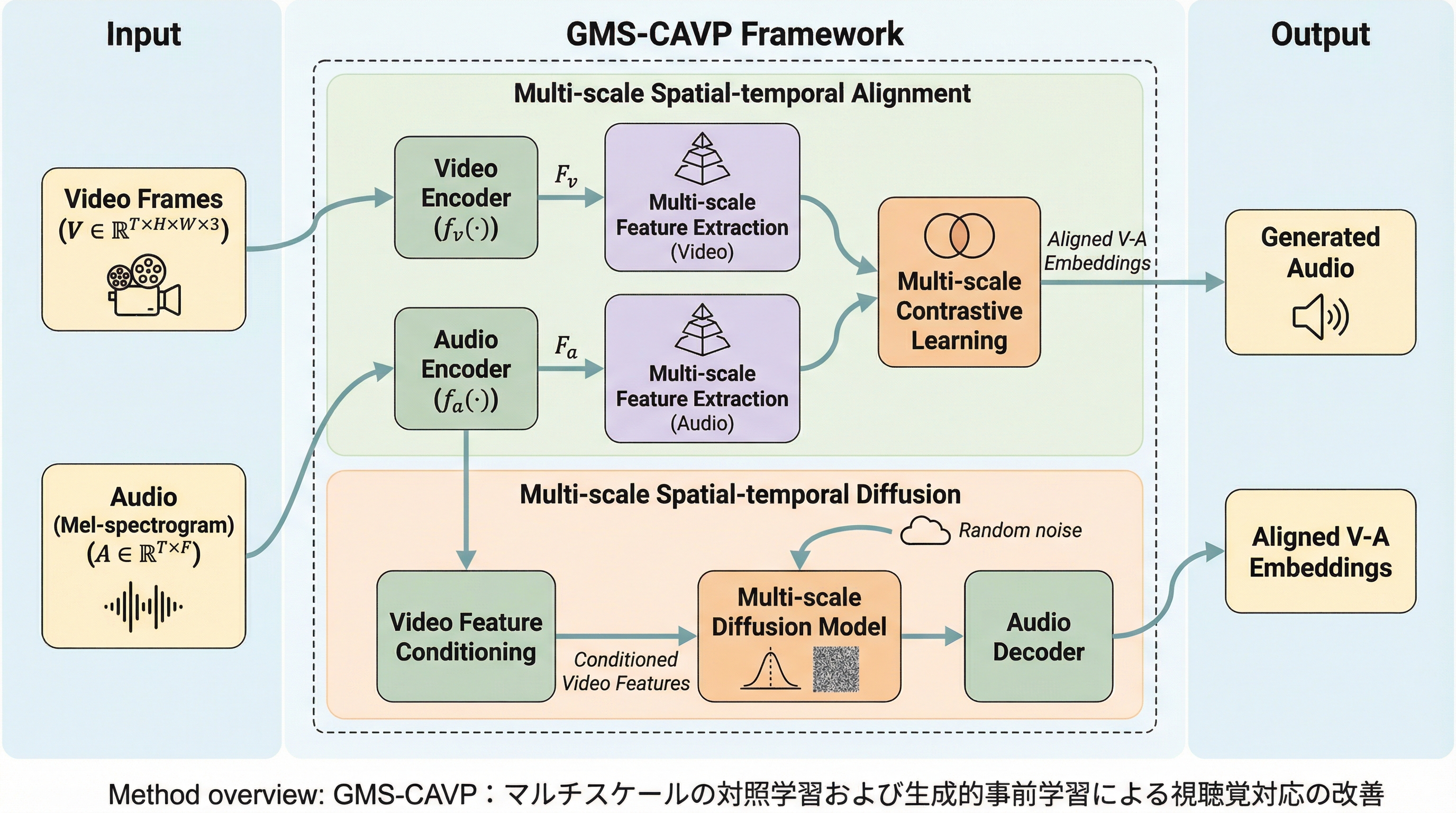
GMS-CAVPは、映像と音声の間の意味的・時間的な対応関係を高度にモデル化するため、マルチスケールでの対照学習と拡散モデルベースの生成学習を統合した新しい視聴覚事前学習フレームワークである。 従来の単一スケールによるグローバルな整列の限界を克服するため、階層的な空間・時間構造を捉える「マルチスケール空間・時間整列(MSA)」と、モダリティ間の翻訳能力を高める「マルチスケール空間・時間拡散(MSD)」を導入している。 VGGSound、AudioSet、Panda70Mを用いた大規模な実験において、映像からの音声生成および双方向検索の双方で従来手法を大幅に上回る世界最高水準の性能を達成し、高い同期性と音響品質を証明した。
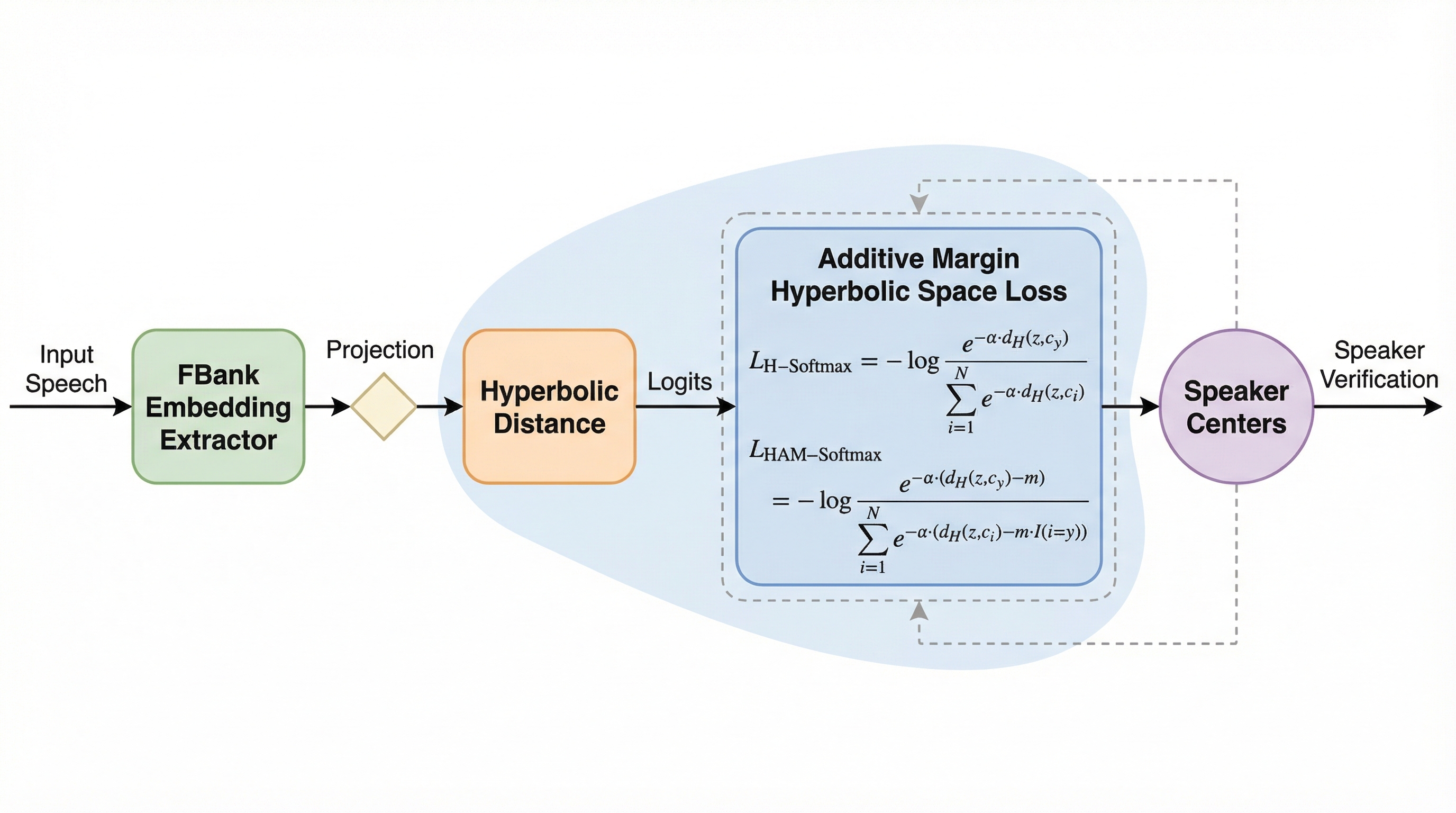
従来の話者照合はユークリッド空間での学習が主流であったが、基本周波数やフォルマント構造といった話者特徴が持つ木構造のような階層的な情報を十分に表現できないという課題があった。本研究では、負の曲率を持ち有限の体積内で指数関数的なデータ配置が可能な双曲空間(ポアンカレ球モデル)を導入し、階層構造を効率的にモデル化するH-Softmaxと、クラス間の分離性を高めるマージン制約を加えたHAM-Softmaxを提案した。実験の結果、VoxCelebやCNCeleb等のデータセットにおいて、従来のSoftmaxやAM-Softmaxと比較して等価誤り率(EER)を大幅に削減することに成功し、特に複雑なクロスドメインデータにおいて高い性能と階層情報の保持能力を示した。
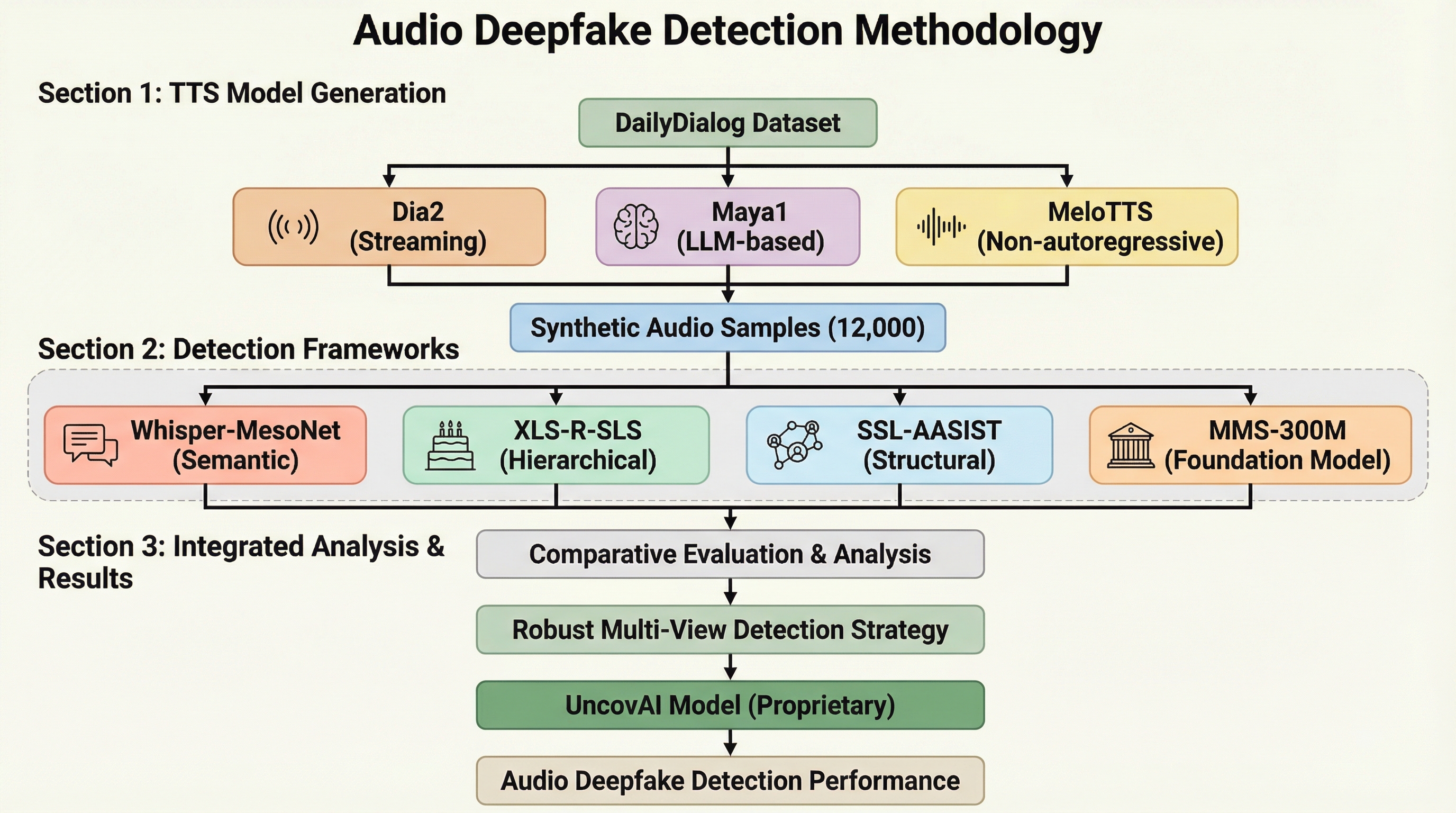
最新のText-to-Speech(TTS)技術であるDia2、Maya1、MeloTTSは、大規模言語モデルやフローマッチング、階層型コーデックを採用することで、従来の検出器では識別が困難な極めて自然な音声を生成する。
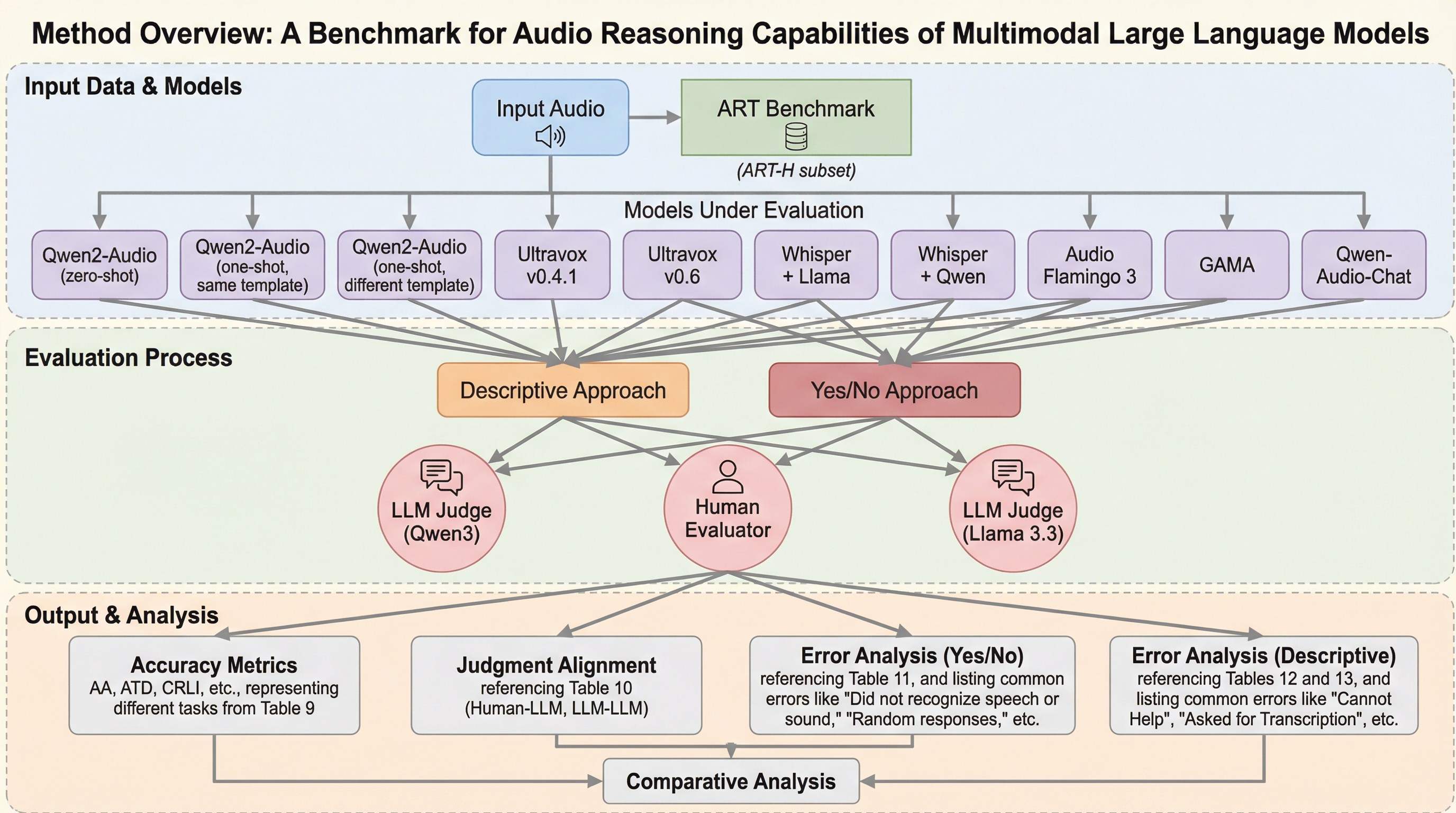
現在のマルチモーダル大規模言語モデル(MLLM)の音声評価指標は、話者識別や性別判定といった個別のタスクに偏っており、複数の音声情報を組み合わせて論理的に思考する「推論能力」を十分に測定できていない。