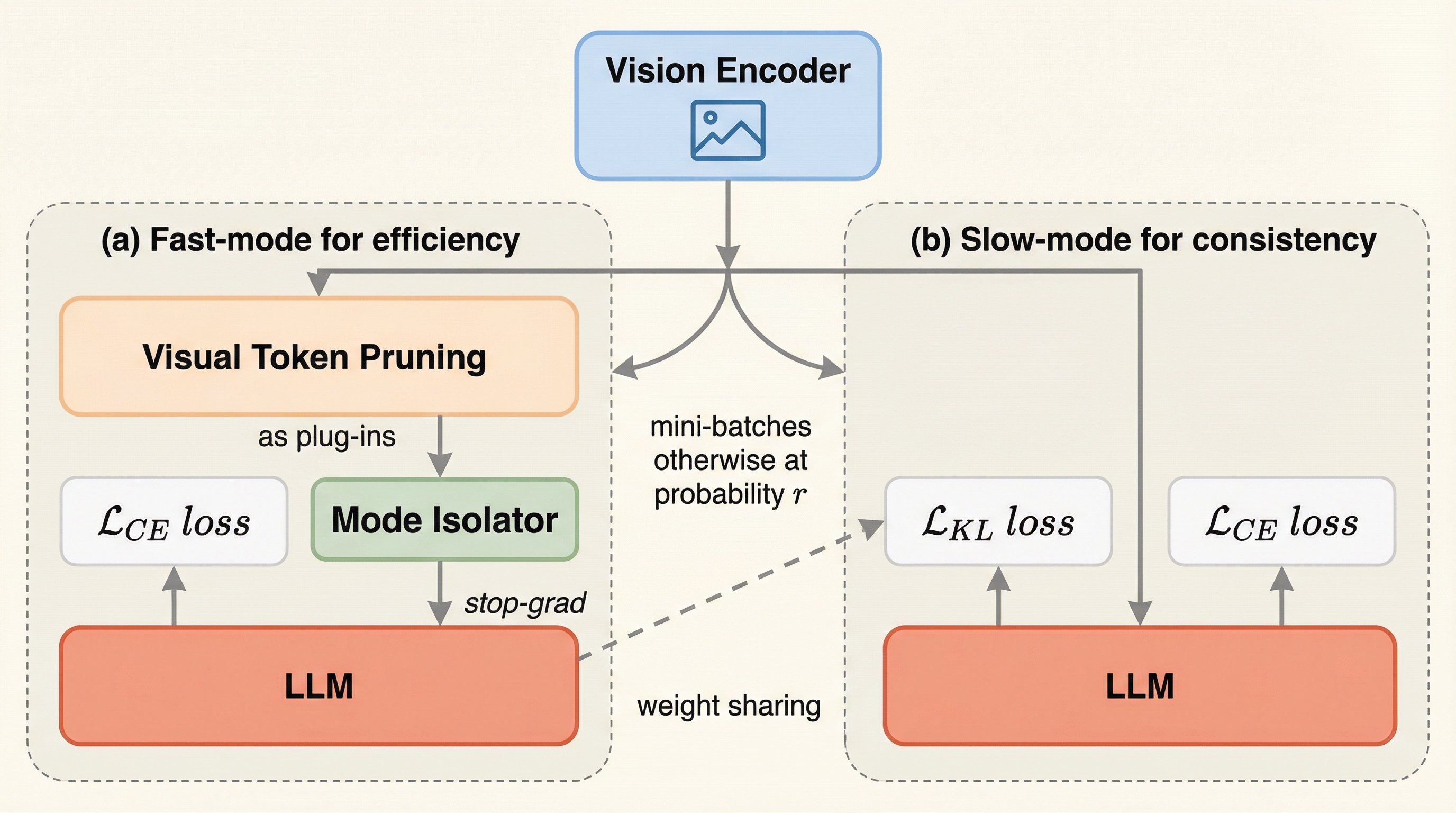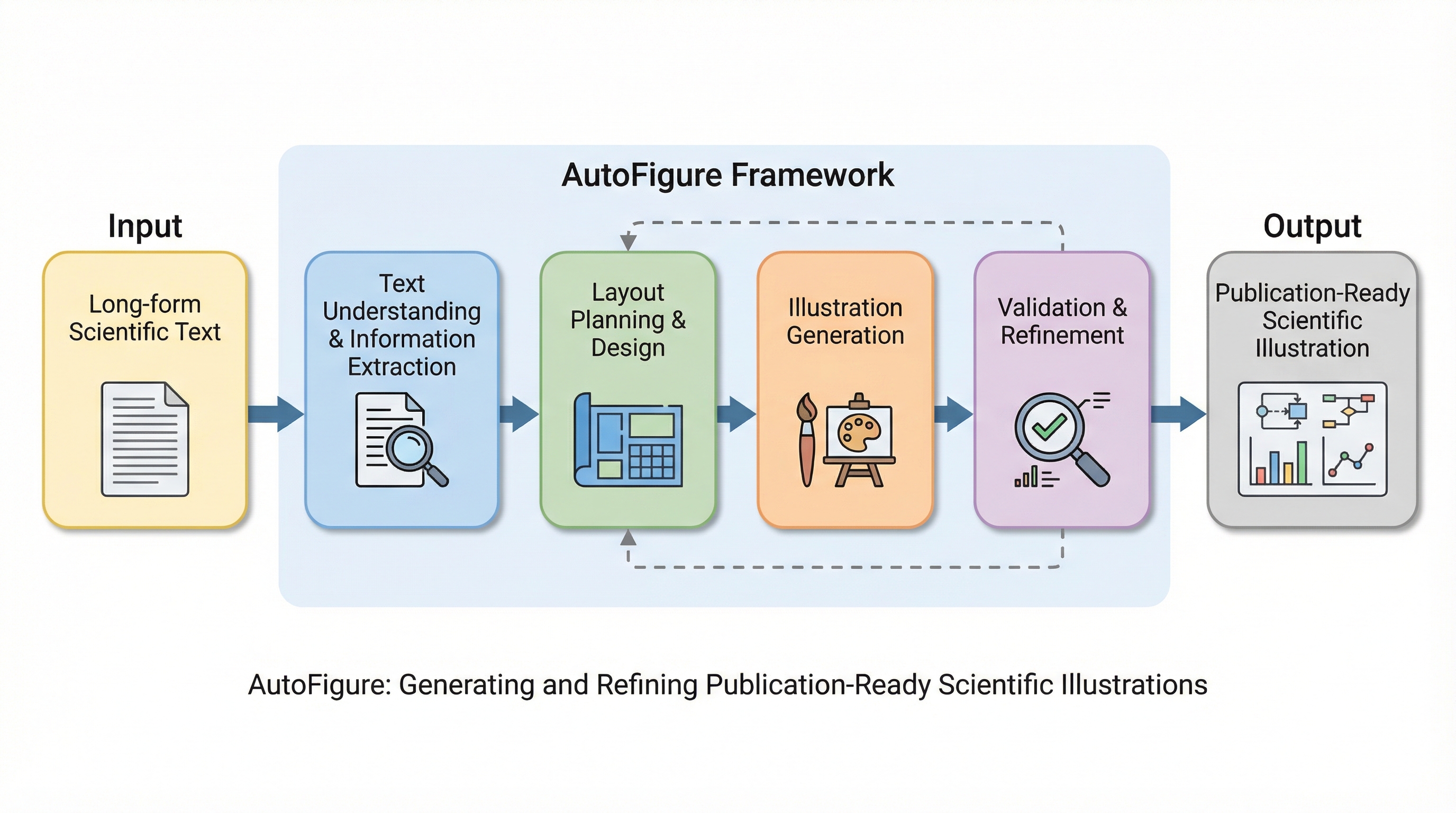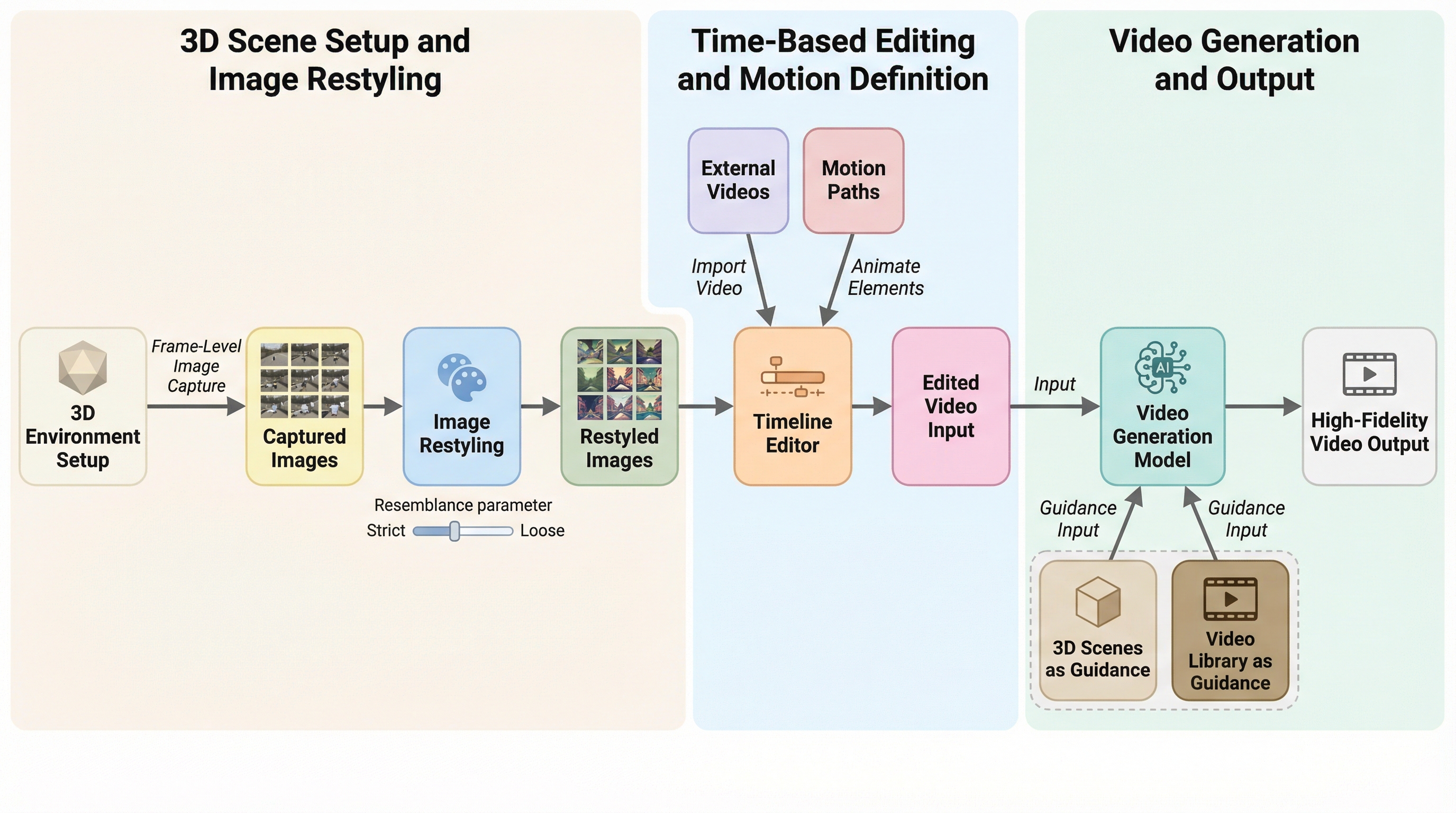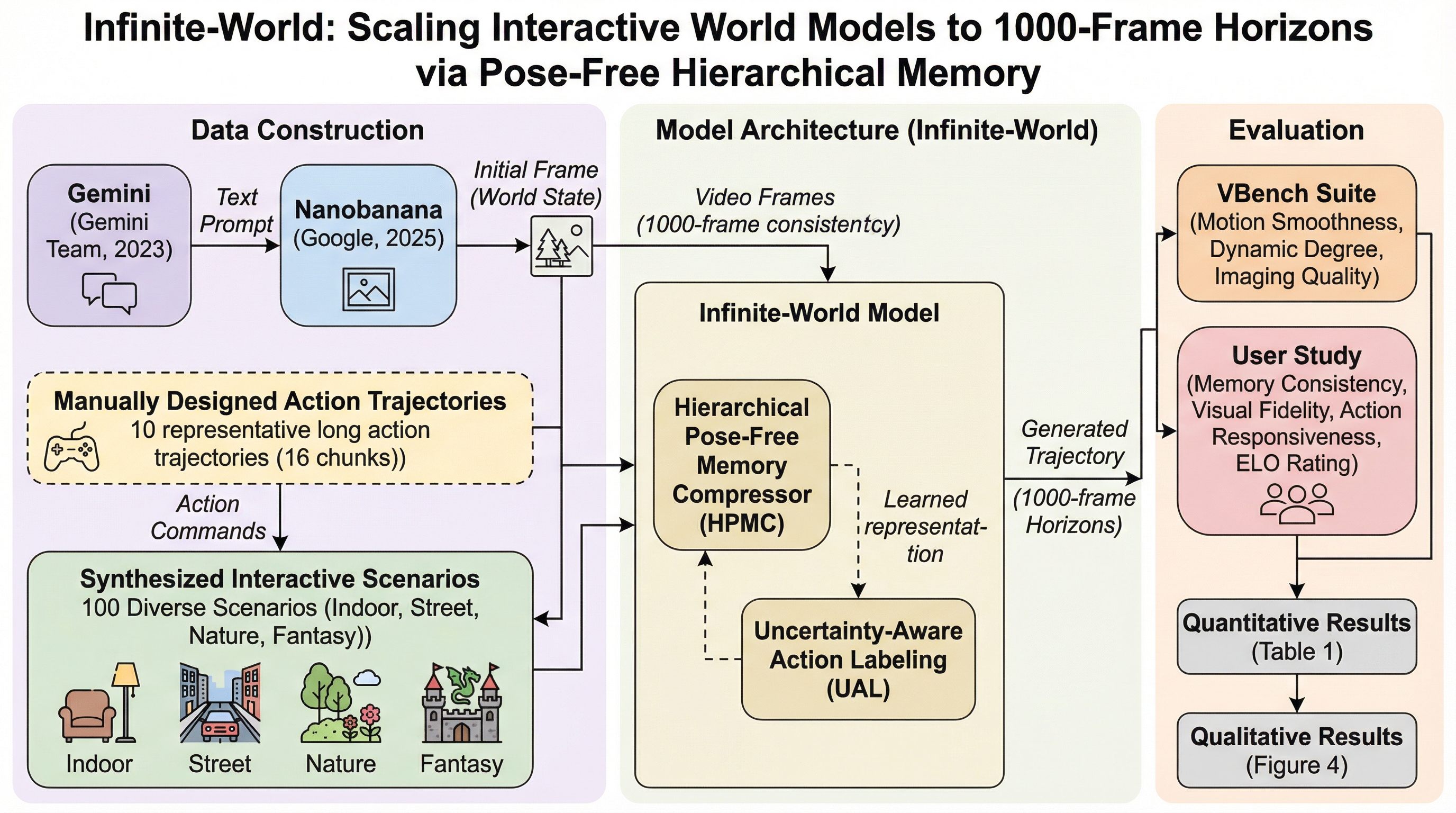
ELIQ:進化するAI生成画像のためのラベルフリーな品質評価フレームワーク
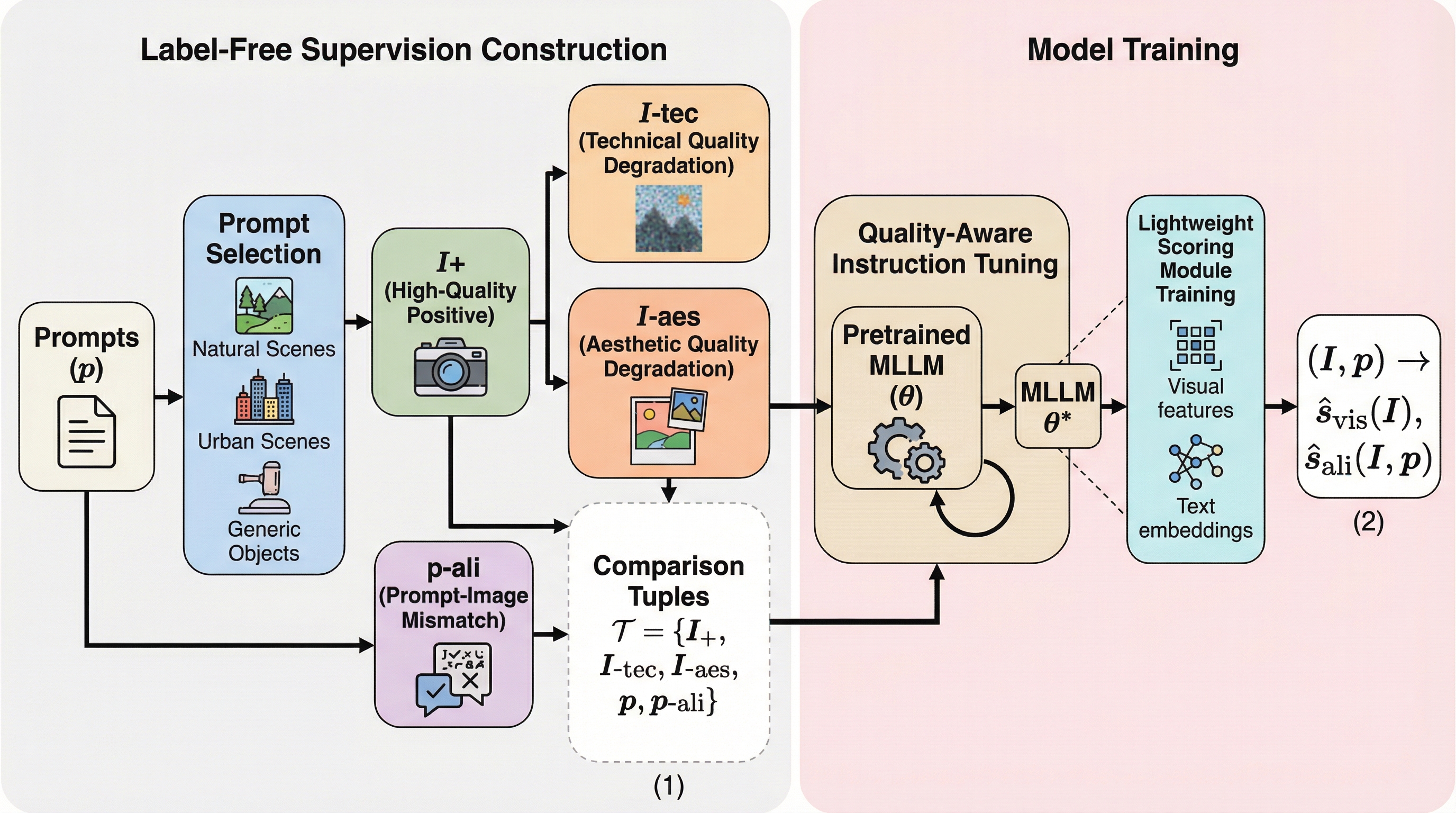
画像生成AIの急速な進化は、従来の人間による評価スコア(MOS)を「知覚的ドリフト」によって急速に陳腐化させ、再評価に膨大なコストを強いるという課題を生んでいる。本研究が提案するELIQは、人間の注釈を一切介さず、最新の生成モデルを用いた高品質な正例と、意図的に劣化させた負例のペアを自動構築することで、視覚的品質とプロンプト整合性の両面からAI生成画像を評価する革新的なラベルフリー・フレームワークである。 命令チューニングを施したマルチモーダル言語モデル(MLLM)を「品質に敏感な批評家」として適応させ、さらに軽量なQuality Query Transformer(QQT)とゲート付き融合メカニズムを組み合わせることで、単一画像からの高精度な品質予測を実現している。 複数のベンチマークにおける検証の結果、ELIQは既存のラベルフリー手法を大幅に凌駕し、教師あり学習モデルに迫る性能を示した。さらに、AI生成画像(AIGC)だけでなくユーザー生成コンテンツ(UGC)にもそのまま適用可能な高い汎用性を持ち、生成モデルの進化に合わせて評価基準を動的に更新できるスケーラブルな評価基盤としての有効性が証明されている。