物理法則で視覚的な質量推定を導く:RGB画像1枚からの挑戦
物体の質量は幾何学的な体積と材料に依存する密度の積で決定されるが、これらはRGB画像の外観から直接観察することができないため、単一画像からの推定は極めて困難な不良設定問題となっている。本研究では、単一のRGB画像から単眼深度推定を用いて3次元幾何学(体積要因)を復元し、視覚言語モデル(VLM)を用いて材料のセマンティクス(密度要因)を抽出して統合する、物理的に構造化された新しいフレームワークを提案した。image2massおよびABO-500という2つの主要なデータセットを用いた検証において、提案手法は従来のRGB画像のみを用いる手法や、単純に深度情報を付加した既存の最先端手法を一貫して上回る推定精度を達成し、物理的な解釈性も向上させた。
TL;DR(結論)
物体の質量は幾何学的な体積と材料に依存する密度の積で決定されるが、これらはRGB画像の外観から直接観察することができないため、単一画像からの推定は極めて困難な不良設定問題となっている。本研究では、単一のRGB画像から単眼深度推定を用いて3次元幾何学(体積要因)を復元し、視覚言語モデル(VLM)を用いて材料のセマンティクス(密度要因)を抽出して統合する、物理的に構造化された新しいフレームワークを提案した。image2massおよびABO-500という2つの主要なデータセットを用いた検証において、提案手法は従来のRGB画像のみを用いる手法や、単純に深度情報を付加した既存の最先端手法を一貫して上回る推定精度を達成し、物理的な解釈性も向上させた。
なぜこの問題か
ロボットが物体を器用に操作するためには、単に形状や姿勢を認識するだけでは不十分であり、物体との相互作用を支配する物理的な原理を深く理解することが不可欠である。特に、質量、剛性、摩擦といった物理的特性は、物体を動かす際の慣性効果や接触の安定性、さらには操作の失敗モードに直接的な影響を与える極めて重要な要素である。物体の質量を事前に知ることは、ロボットが適切な把持力を調整し、関節にかかる過度なトルクを制限し、壊れやすい物体や精密な機械部品への損傷を避けるために決定的な役割を果たす。しかし、従来の質量推定手法の多くは、力センサーやトルクセンサーを用いた物理的な接触、例えば「テストリフト」のような探索的な動作を通じて行われてきた。このような接触ベースのアプローチは、実際に物体に触れて動かし始めるまで推定が完了しないため、リアルタイム性に欠けるだけでなく、システムや物体を安全でない力にさらすリスクを伴う。また、専用のハードウェアや複雑な探索行動を必要とするため、実用的な展開が制限されるという課題があった。…
核心:何を提案したのか
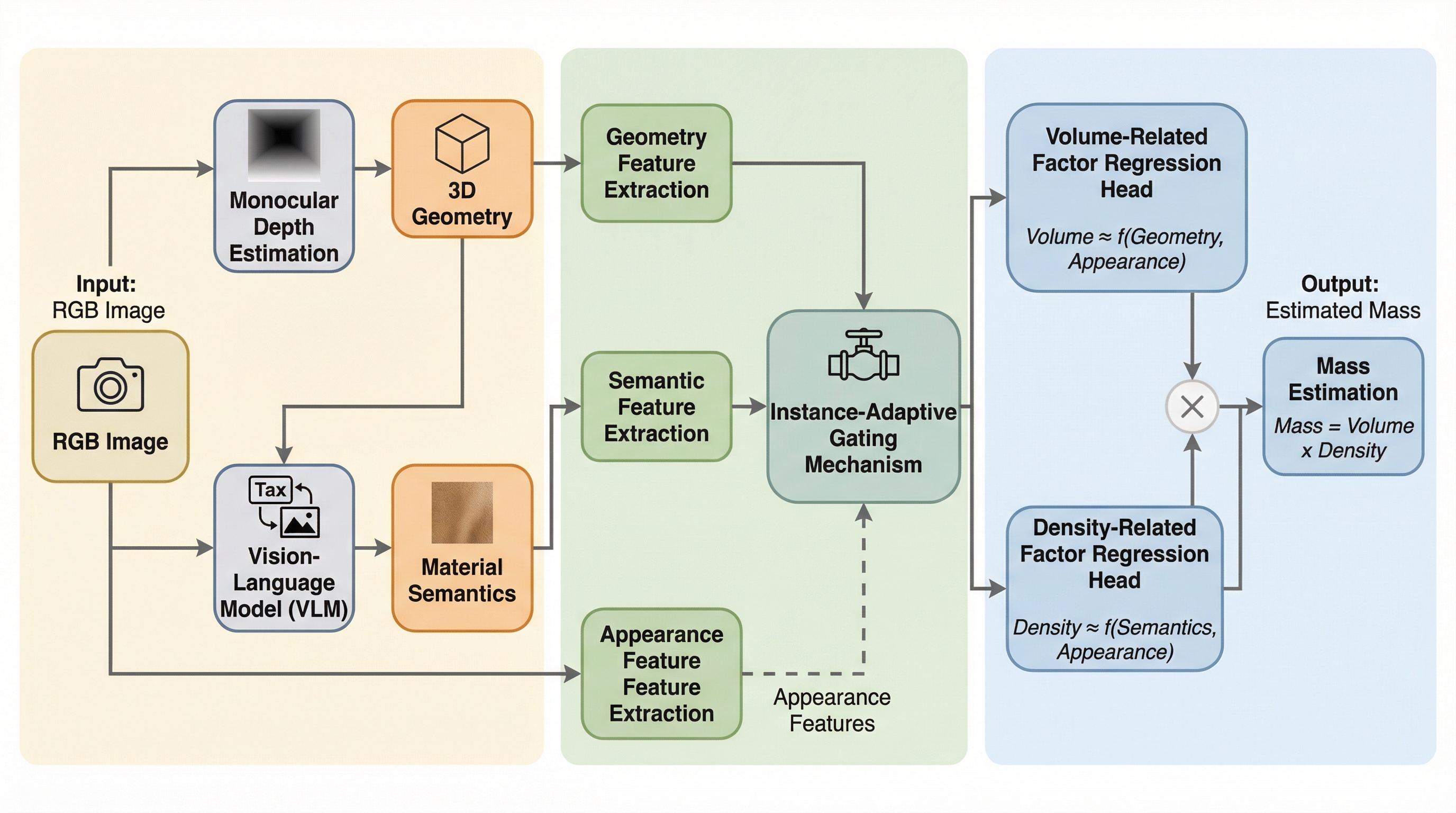
本研究の核心は、質量が体積と密度の積であるという基本的な物理的関係に基づき、視覚的な手がかりをそれぞれの物理的要因に明示的に整合させる「物理構造化フレームワーク」を提案した点にある。具体的には、単一のRGB画像から得られる情報を「外観」「幾何学」「セマンティクス」という3つの独立した要素に分解し、それらを物理的な役割に応じて統合する設計を採用した。まず、単眼深度推定を通じて得られた3次元幾何学情報を体積に関連する要因の推論に割り当て、視覚言語モデル(VLM)から得られた材料のセマンティクス情報を密度に関連する要因の推論に割り当てる。このように、各物理的要因をそれを説明するのに最も適した視覚的証拠と結びつけることで、単一画像特有の情報の曖昧さを解消しようとしている。 提案手法では、これらの幾何学的、意味的、および外観の表現を、インスタンス適応型のゲートメカニズムを介して融合する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related