Tri-Reader:スクリーニングCTにおける肺結節の一次アノテーションのためのオープンアクセスかつ多段階のAIパイプライン
肺がんスクリーニング用AIの開発において、高品質なCT画像のアノテーションには膨大な時間と専門知識、そして高額な費用が必要という課題を解決するため、複数のオープンアクセスモデルを統合した「Tri-Reader」という多段階パイプラインが開発されました。
TL;DR(結論)
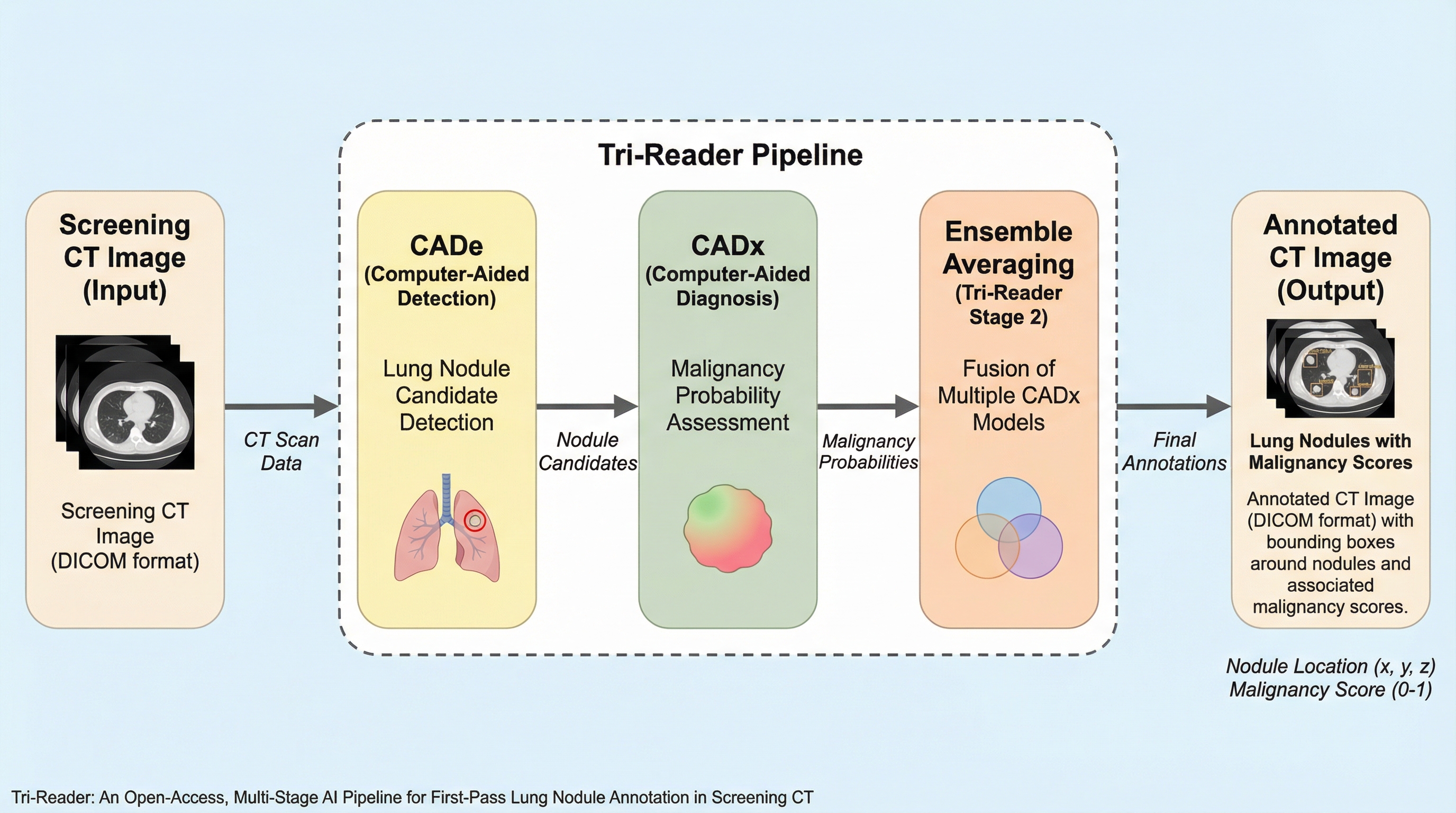
肺がんスクリーニング用AIの開発において、高品質なCT画像のアノテーションには膨大な時間と専門知識、そして高額な費用が必要という課題を解決するため、複数のオープンアクセスモデルを統合した「Tri-Reader」という多段階パイプラインが開発されました。 このシステムは、肺のセグメンテーション、結節検出、悪性度分類の3段階で構成されるワークフローにより、臨床的に重要な結節に対する高い検出感度を維持しながら、人間が確認すべき候補数を従来手法と比較して40%から55%削減することに成功しています。 米国、欧州、アジアの多様な国際的データセットを用いた検証により、異なる臨床環境やアノテーション基準においても高い汎用性と効率性が証明されており、GitHub上で公開されたコードとモデルは、研究者や開発者が高品質なデータセットを迅速に構築するための強力な支援ツールとなります。
なぜこの問題か
肺がんスクリーニングのためのAIモデルを訓練し、その精度を向上させるためには、大規模かつ多様なデータセットが必要不可欠ですが、高品質な肺結節のアノテーション(ラベル付け)を作成するプロセスは極めて手間がかかり、高コストであることが大きな障壁となっています。 現在、多くのデータセットがオープンアクセス化され、AIと人間の協力によるデータキュレーションが進んでいますが、その具体的なキュレーションプロセス自体は非公開であったり、商業的な枠組みの中に留まっていたりすることが少なくありません。 近年、肺のセグメンテーションや結節検出(CADe)、悪性度診断(CADx)のためのオープンソース実装が複数公開されるようになりましたが、これらは個別に利用されることが多く、統合されたワークフローとしては確立されていませんでした。 研究現場や臨床現場では、人間による詳細なレビューやアノテーションを行う前段階として、管理可能な数の候補を迅速に提示できる、再現可能で統合された「ファーストパス(一次選別)」パイプラインの実用的なニーズが高まっていました。…
核心:何を提案したのか
本研究では、肺のセグメンテーション、結節検出、悪性度分類を一つの統合された3段階のワークフローにまとめた、オープンアクセスのパイプライン「Tri-Reader」を提案しました。 このシステムは、特定のデータセットごとに新しいモデルを訓練し直す必要がなく、既存のオープンソース実装を組み合わせることで、アノテーションの作業効率を最大化するように設計されています。 Tri-Readerの最大の特徴は、検出感度を最優先に保ちながら、アノテーターが確認しなければならない候補の負担を減らすために、信頼度に基づいた階層的な出力(1.0、0.5、0.2)を行う点にあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related