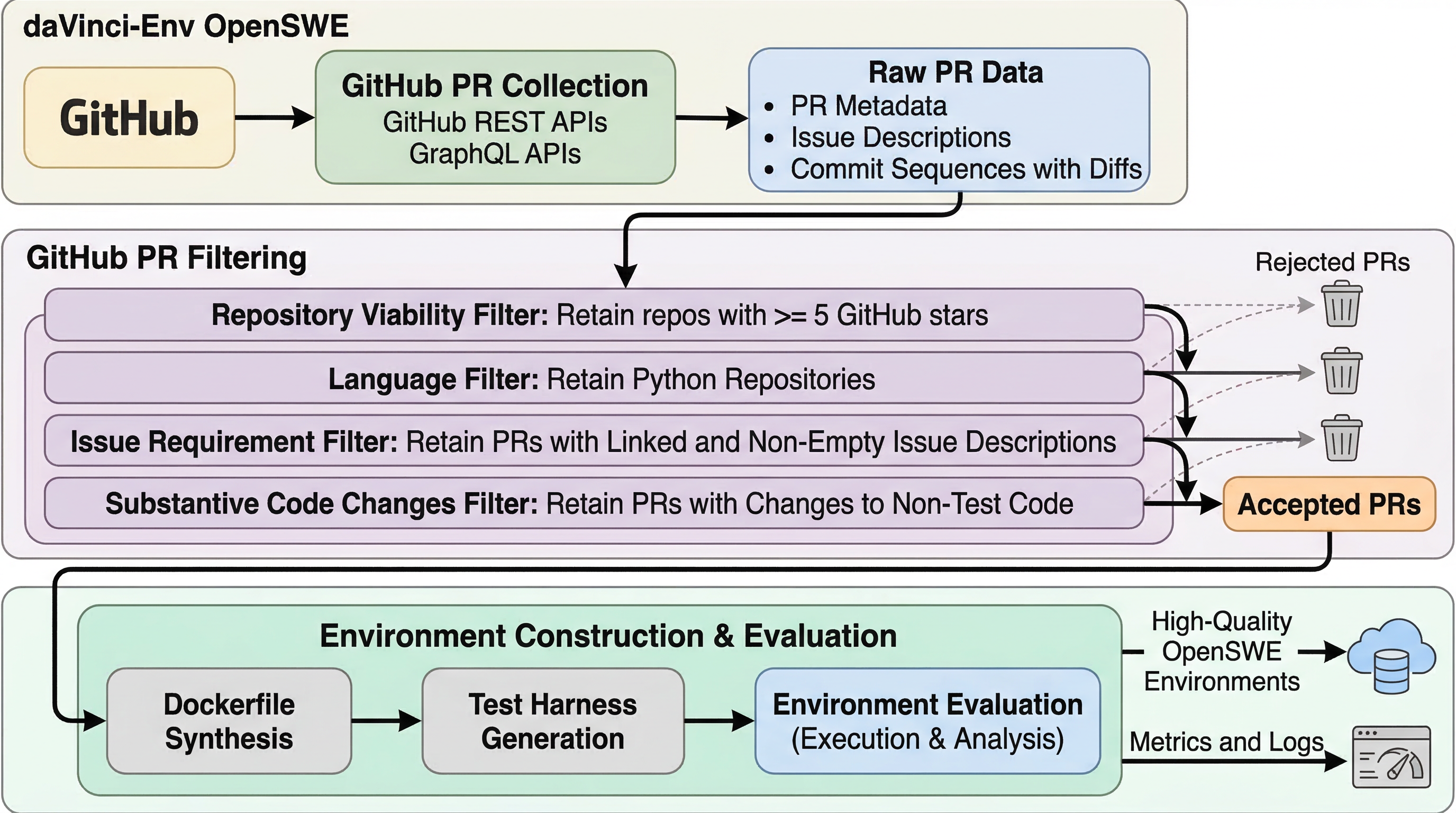
OpenSWEは何を変えたのか:SWEエージェント訓練を支える4.5万件の実行環境と難度キュレーション
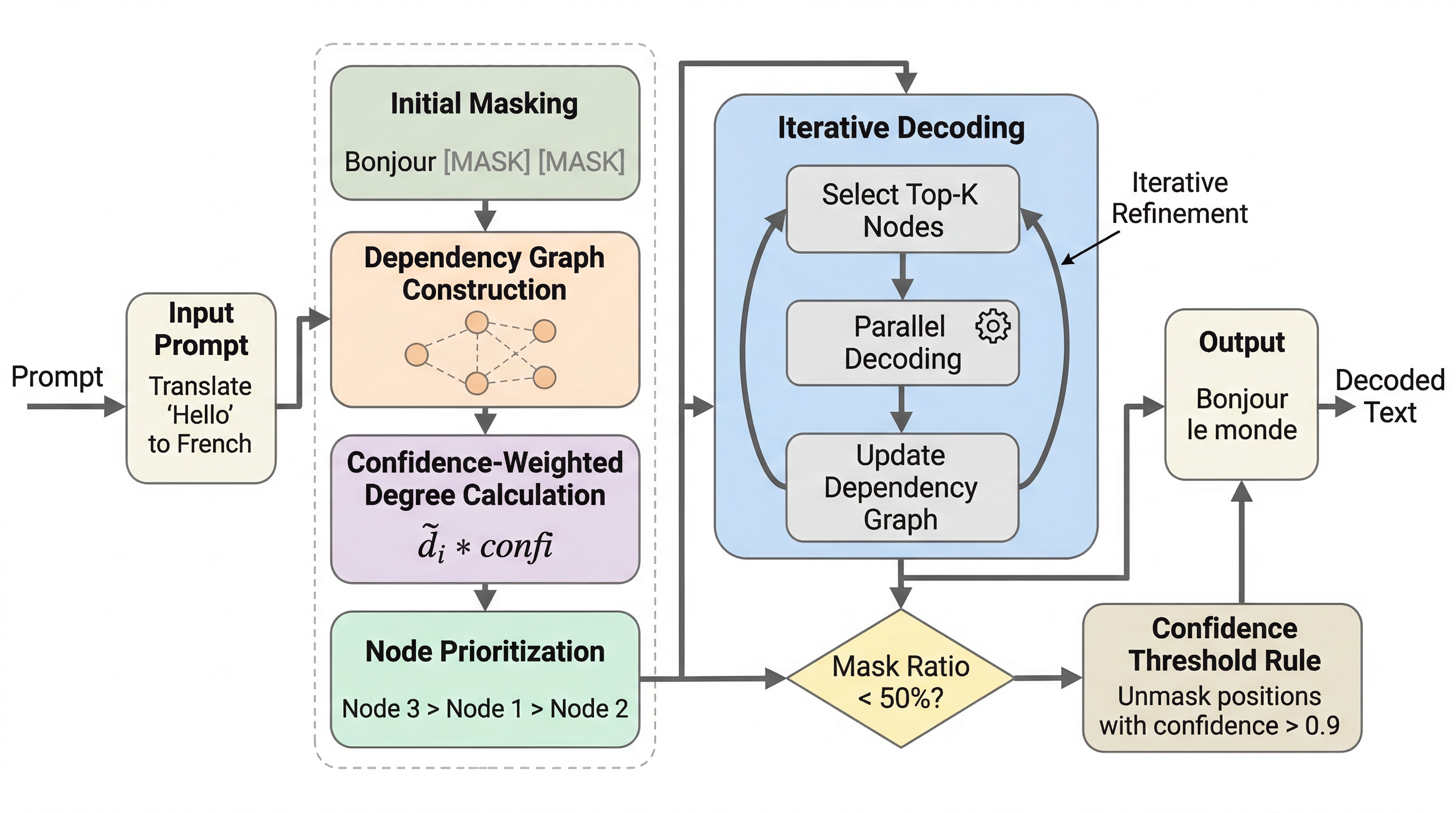
ソフトウェアエージェントの学習で本当に足りていないのは、コード断片ではなく、テスト実行と修正の反復を伴う「動く環境」です。OpenSWEは12.8kリポジトリから45,320件の実行可能Docker環境を公開し、その生成インフラまで含めて透明化しました。 狙いは規模の誇示だけではありません。PRとIssueの不整合や、説明文を読めば答えがほぼ分かる trivial な課題を除き、「学習信号としてちょうどよい難しさ」の環境だけを残す difficulty-aware filtering が核心です。 その結果、OpenSWEで訓練した32B/72BモデルはSWE-bench Verifiedで62.4%/66.0%を達成し、同系統の既存データより強く、しかも数学推論で最大12点、科学ベンチで最大5点の外部改善まで示しました。