OpenSWEは何を変えたのか:SWEエージェント訓練を支える4.5万件の実行環境と難度キュレーション
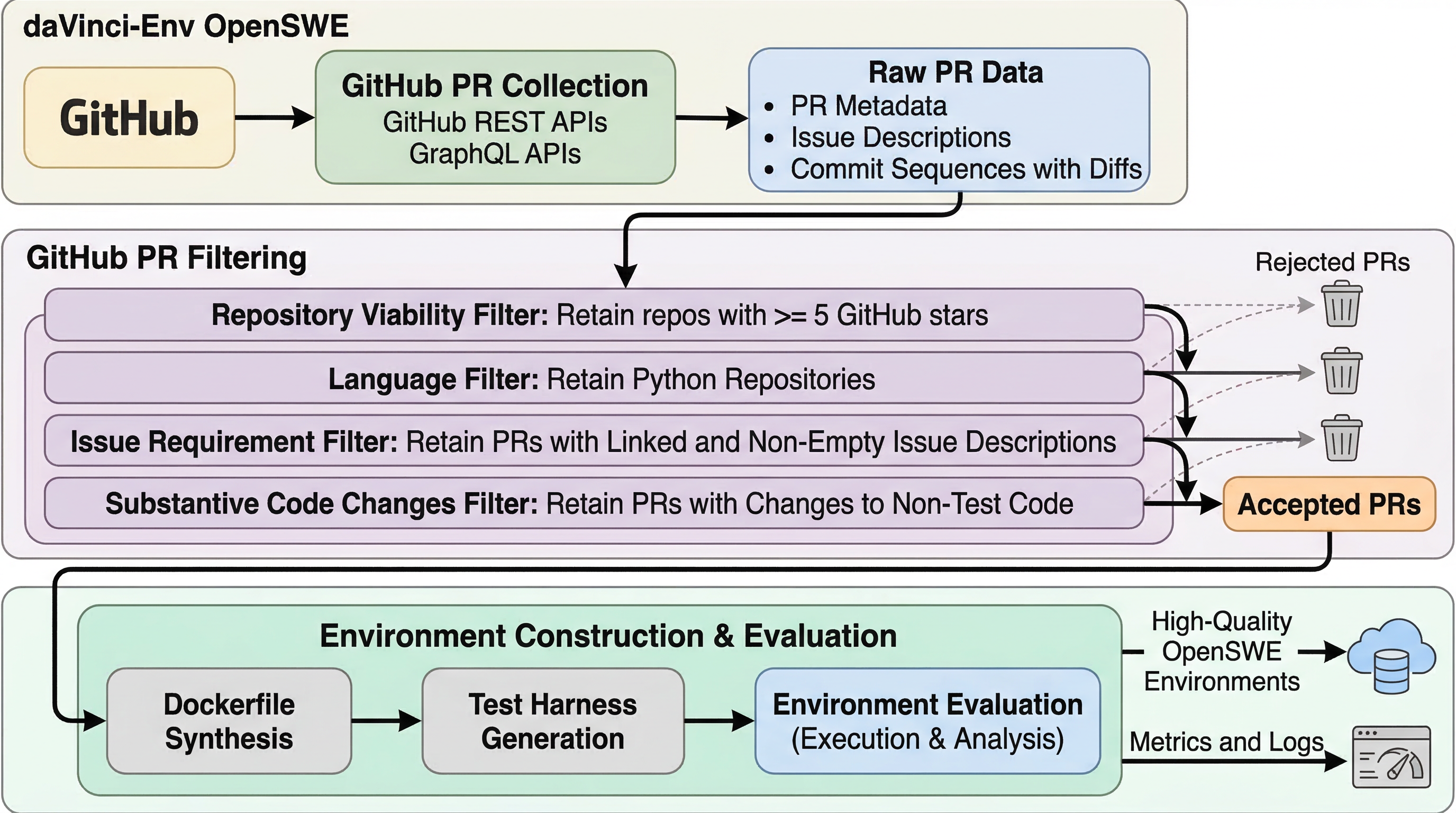
ソフトウェアエージェントの学習で本当に足りていないのは、コード断片ではなく、テスト実行と修正の反復を伴う「動く環境」です。OpenSWEは12.8kリポジトリから45,320件の実行可能Docker環境を公開し、その生成インフラまで含めて透明化しました。 狙いは規模の誇示だけではありません。PRとIssueの不整合や、説明文を読めば答えがほぼ分かる trivial な課題を除き、「学習信号としてちょうどよい難しさ」の環境だけを残す difficulty-aware filtering が核心です。 その結果、OpenSWEで訓練した32B/72BモデルはSWE-bench Verifiedで62.4%/66.0%を達成し、同系統の既存データより強く、しかも数学推論で最大12点、科学ベンチで最大5点の外部改善まで示しました。
TL;DR(結論)
- ソフトウェアエージェントの学習で本当に足りていないのは、コード断片ではなく、テスト実行と修正の反復を伴う「動く環境」です。OpenSWEは12.8kリポジトリから45,320件の実行可能Docker環境を公開し、その生成インフラまで含めて透明化しました。
- 狙いは規模の誇示だけではありません。PRとIssueの不整合や、説明文を読めば答えがほぼ分かる trivial な課題を除き、「学習信号としてちょうどよい難しさ」の環境だけを残す difficulty-aware filtering が核心です。
- その結果、OpenSWEで訓練した32B/72BモデルはSWE-bench Verifiedで62.4%/66.0%を達成し、同系統の既存データより強く、しかも数学推論で最大12点、科学ベンチで最大5点の外部改善まで示しました。
なぜこの問題か
SWEエージェントを本気で鍛えるには、ただ正解コードを見せるだけでは足りません。大規模言語モデルに必要なのは、巨大なリポジトリを読み、依存関係を解き、コードを書き換え、テストを実行し、その失敗ログから次の手を決めるという反復の場です。つまり、実行可能で、検証可能で、失敗から学べる環境そのものが学習資源になります。
核心:何を提案したのか
提案の中核はOpenSWEです。PythonのSWEエージェント訓練向けに、45,320件の executable Docker environment を12.8kリポジトリから合成し、Dockerfile、評価スクリプト、分散構築インフラまで公開する fully transparent framework として設計されています。単なる最終成果物ではなく、どうやってその環境を合成したかまで含めて公開する点が特徴です。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related