拡散型言語モデルの並列復号を依存関係つきで進める:自己注意から独立集合を選ぶ DAPD
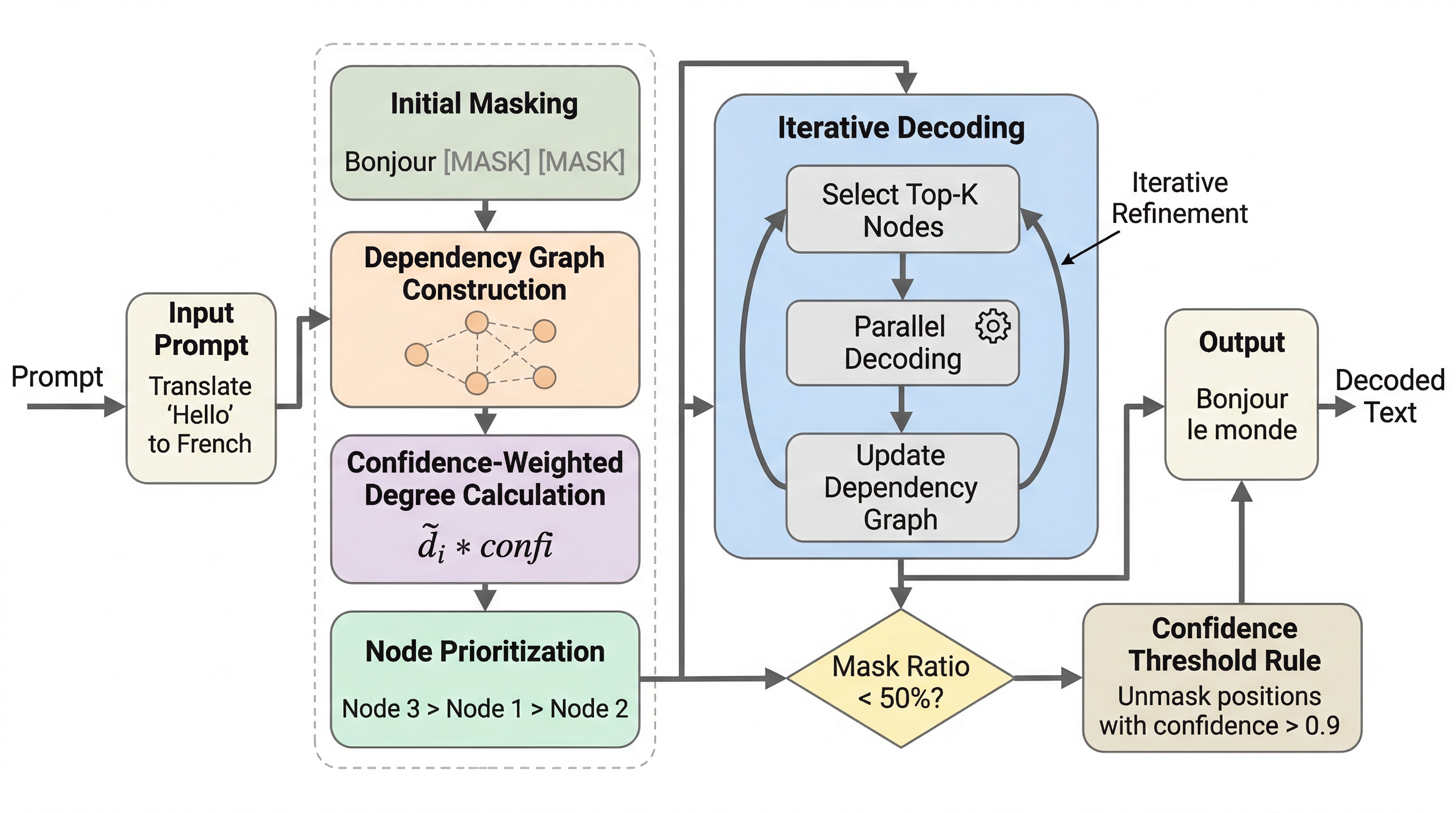
拡散型言語モデルは複数トークンを同時に埋め戻せるのが強みですが、各位置の確率だけを見て並列更新すると、互いに強く依存した語を同時に確定して全体が不整合になりやすいという弱点があります。 DAPD は、自己注意からマスク位置間の依存グラフを作り、強く結びついた位置を避けながら独立集合だけを選んで同時にマスク解除 する、追加学習不要の並列復号法です。 LLaDA と Dream で精度とステップ数の両立を改善し、ParallelBench では LLaDA の逐次生成に近い精度を保ちながら平均66.2 step まで短縮し、3.87倍の高速化を達成しました。
論文図解
TL;DR(結論)
- 拡散型言語モデルは複数トークンを同時に埋め戻せるのが強みですが、各位置の確率だけを見て並列更新すると、互いに強く依存した語を同時に確定して全体が不整合になりやすいという弱点があります。
- DAPD は、自己注意からマスク位置間の依存グラフを作り、強く結びついた位置を避けながら独立集合だけを選んで同時にマスク解除 する、追加学習不要の並列復号法です。
- LLaDA と Dream で精度とステップ数の両立を改善し、ParallelBench では LLaDA の逐次生成に近い精度を保ちながら平均66.2 step まで短縮し、3.87倍の高速化を達成しました。
なぜこの問題か
拡散型言語モデルの魅力は、自己回帰型のように左から一つずつ書くのではなく、穴埋めのように複数位置を同時に埋められる点です。理屈のうえでは、複数トークンを並列に確定できれば、順伝播の回数を減らし、推論遅延を大きく削れます。ところが実際には、それほど単純ではありません。拡散型言語モデルが各 step で返すのはマスク位置ごとの条件付き周辺分布であって、複数位置の同時分布ではないからです。
核心:何を提案したのか
提案の中心は DAPD、Dependency-Aware Parallel Decoding です。基本アイデアは明快で、マスク位置 間の依存関係をグラフとして表し、そのグラフ上で互いに隣接していない token 群、つまり独立集合を選んで並列に マスク解除 します。強く結びついた token を同じ step で確定しないので、同時更新による矛盾を減らせます。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related