FedBPrompt:背景の紛れと視点ずれを、身体分布を意識した視覚プロンプトで抑える連合ドメイン汎化ReID
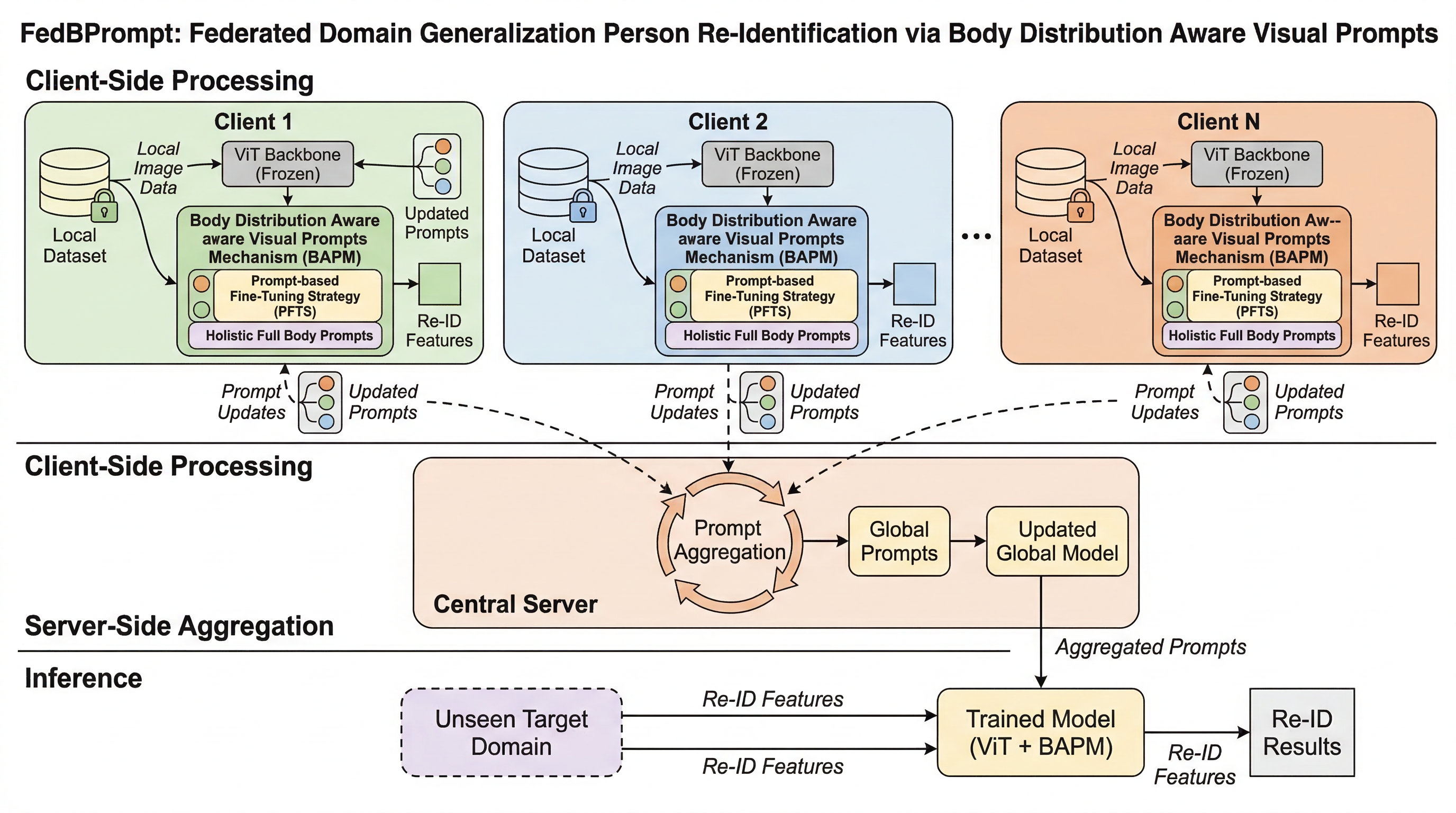
FedDG-ReID では、クライアントごとに背景や視点の分布が大きく違うため、ViT の全体注意だけでは「背景に引っ張られる誤一致」と「同一人物でも体の部位がずれて似なくなる失敗」が起きやすくなります。 FedBPrompt は、全身を見る Holistic Full Body Prompts と、上半身・中胴・下半身を合わせる Body Part Alignment Prompts を組み合わせた BAPM と、プロンプトだけを更新する PFTS で、この二つの失敗を同時に抑えます。 強いベースライン SSCU に対しても平均で mAP を 3.3%、Rank-1 を 4.9% 改善し、送信パラメータは全モデルの約 1% まで削減でき、少ない集約ラウンドでも効果が出ます。
TL;DR(結論)
- FedDG-ReID では、クライアントごとに背景や視点の分布が大きく違うため、ViT の全体注意だけでは「背景に引っ張られる誤一致」と「同一人物でも体の部位がずれて似なくなる失敗」が起きやすくなります。
- FedBPrompt は、全身を見る Holistic Full Body Prompts と、上半身・中胴・下半身を合わせる Body Part Alignment Prompts を組み合わせた BAPM と、プロンプトだけを更新する PFTS で、この二つの失敗を同時に抑えます。
- 強いベースライン SSCU に対しても平均で mAP を 3.3%、Rank-1 を 4.9% 改善し、送信パラメータは全モデルの約 1% まで削減でき、少ない集約ラウンドでも効果が出ます。
なぜこの問題か
人物再識別は、防犯、都市インフラ、マルチカメラ追跡の基盤となる技術です。難しさは、同じ人物でもカメラが変われば見え方が大きく変わること、逆に違う人物でも背景や服装条件が似ていれば見間違えやすいことにあります。そのため近年は、学習時に見ていないドメインでも通用する Domain Generalization Person Re-identification が重視されてきました。
核心:何を提案したのか
提案の中心は FedBPrompt です。名前の通り、Federated Body Distribution Aware Visual Prompt という発想で、ViT へ learnable visual prompts を差し込み、人中心の領域へ注意を寄せるよう誘導します。ただし、単にプロンプトを足すだけではありません。身体のどこを見るべきか、どの程度全身を見るべきかを分けて設計した Body Distribution Aware Visual Prompts Mechanism、略して BAPM が核です。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related