連合学習で「忘れさせる」を厳密にやるには:凍結基盤モデル+Ridgeヘッドで再学習と一点一致させる正確な継続的忘却
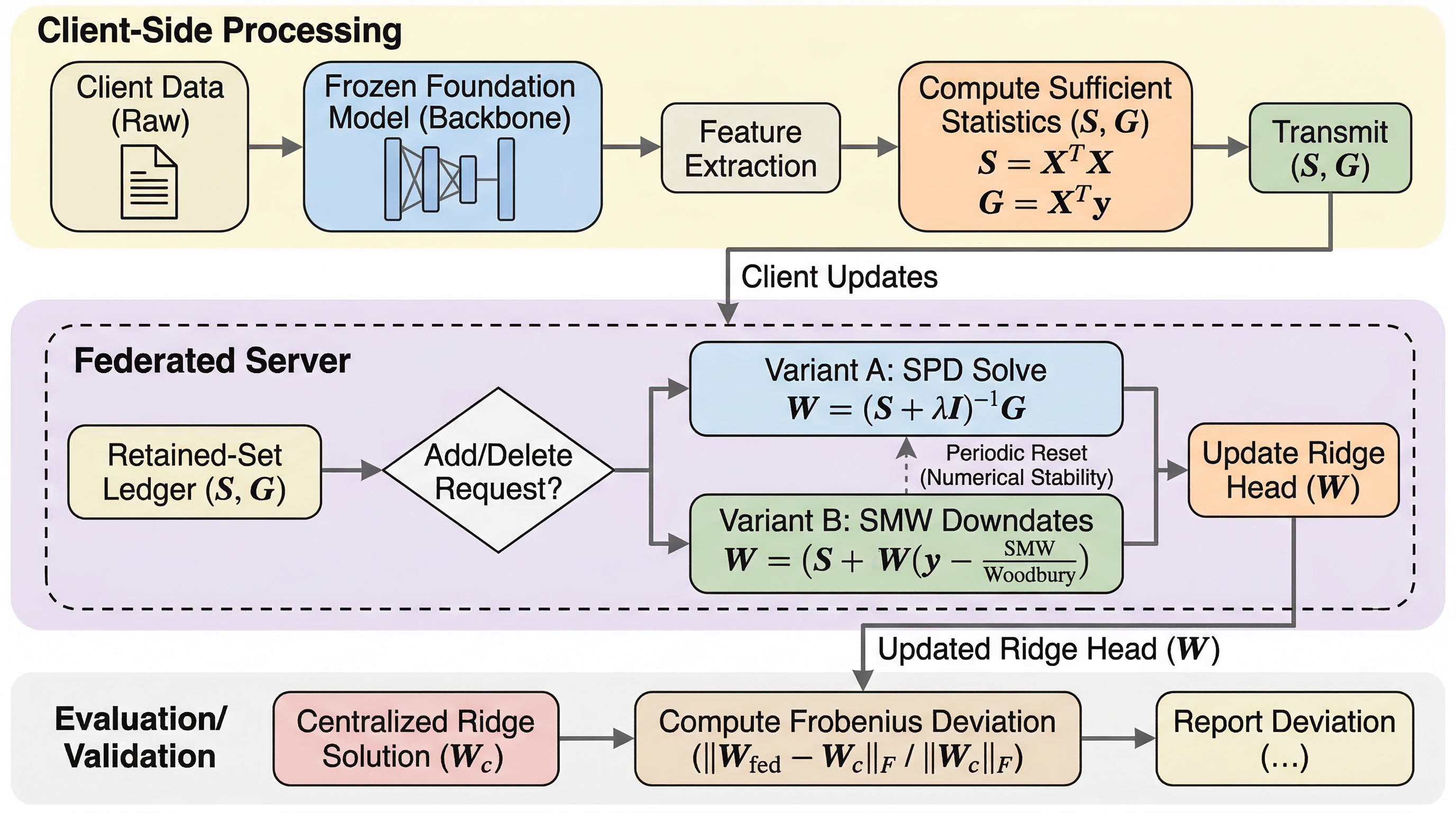
連合学習で「特定ユーザーや特定サンプルの影響だけを消したい」と言っても、通常の深層モデルでは再学習と完全一致させるのが難しく、既存法は近似や選択的再学習に頼りがちです。論文はこの問題を、凍結した基盤モデルの上に ridge 回帰ヘッドだけを載せる実務的設定へ絞ることで、厳密解まで落とし込みました。 核心は、学習結果が各サンプルの生データそのものではなく、二つの加法的十分統計量だけで決まると見抜いた点です。各クライアントは追加・削除要求を固定サイズの統計メッセージとして送り、サーバはその帳簿を更新するだけで、中央で retained data に対して最初から再学習した解と理論上完全一致するヘッドを維持できます。 実験では CIFAR-10、CIFAR-100、FeMNIST、Sentiment140 の4ベンチで、提案した2変種が中央再学習との差を相対 Frobenius 誤差 10^-9 レベルまで抑え、FedAvg 系の exact federated unlearning ベースラインより桁違いに低コストで削除要求を処理しました。つまり「忘却を厳密にやりたいなら、まず何を学習対象にするかを変えるべきだ」という論文です。
TL;DR(結論)
- 連合学習で「特定ユーザーや特定サンプルの影響だけを消したい」と言っても、通常の深層モデルでは再学習と完全一致させるのが難しく、既存法は近似や選択的再学習に頼りがちです。論文はこの問題を、凍結した基盤モデルの上に ridge 回帰ヘッドだけを載せる実務的設定へ絞ることで、厳密解まで落とし込みました。
- 核心は、学習結果が各サンプルの生データそのものではなく、二つの加法的十分統計量だけで決まると見抜いた点です。各クライアントは追加・削除要求を固定サイズの統計メッセージとして送り、サーバはその帳簿を更新するだけで、中央で retained data に対して最初から再学習した解と理論上完全一致するヘッドを維持できます。
- 実験では CIFAR-10、CIFAR-100、FeMNIST、Sentiment140 の4ベンチで、提案した2変種が中央再学習との差を相対 Frobenius 誤差 10^-9 レベルまで抑え、FedAvg 系の exact federated unlearning ベースラインより桁違いに低コストで削除要求を処理しました。つまり「忘却を厳密にやりたいなら、まず何を学習対象にするかを変えるべきだ」という論文です。
なぜこの問題か
生成AIや基盤モデルの活用が進むほど、重い本体は凍結し、上に小さなヘッドだけを載せて各組織や各ユーザーの私的データへ適応する運用が増えます。医療、金融、法務のような規制領域では特にこの形が自然で、元モデルは共有しつつ、手元の機微データで最後の判断層だけを更新する構成が実務上扱いやすいからです。
核心:何を提案したのか
提案の本体は、凍結特徴抽出器の上に ridge-regression head を置いた連合学習に対する exact federated continual unlearning プロトコルです。各クライアントは、保持されるデータの特徴行列とラベル行列から作られる二つの十分統計量、具体的には二次統計 S = F^T F と一次統計 G = F^T Y に関する add / delete 更新だけをサーバへ送ります。サーバはその帳簿を逐次更新し、(S + γI)W = G の解として現在のヘッド W を復元します。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related