SAW:4つの軽量条件で腹腔鏡手技動画を制御生成する外科ワールドモデルへの一歩
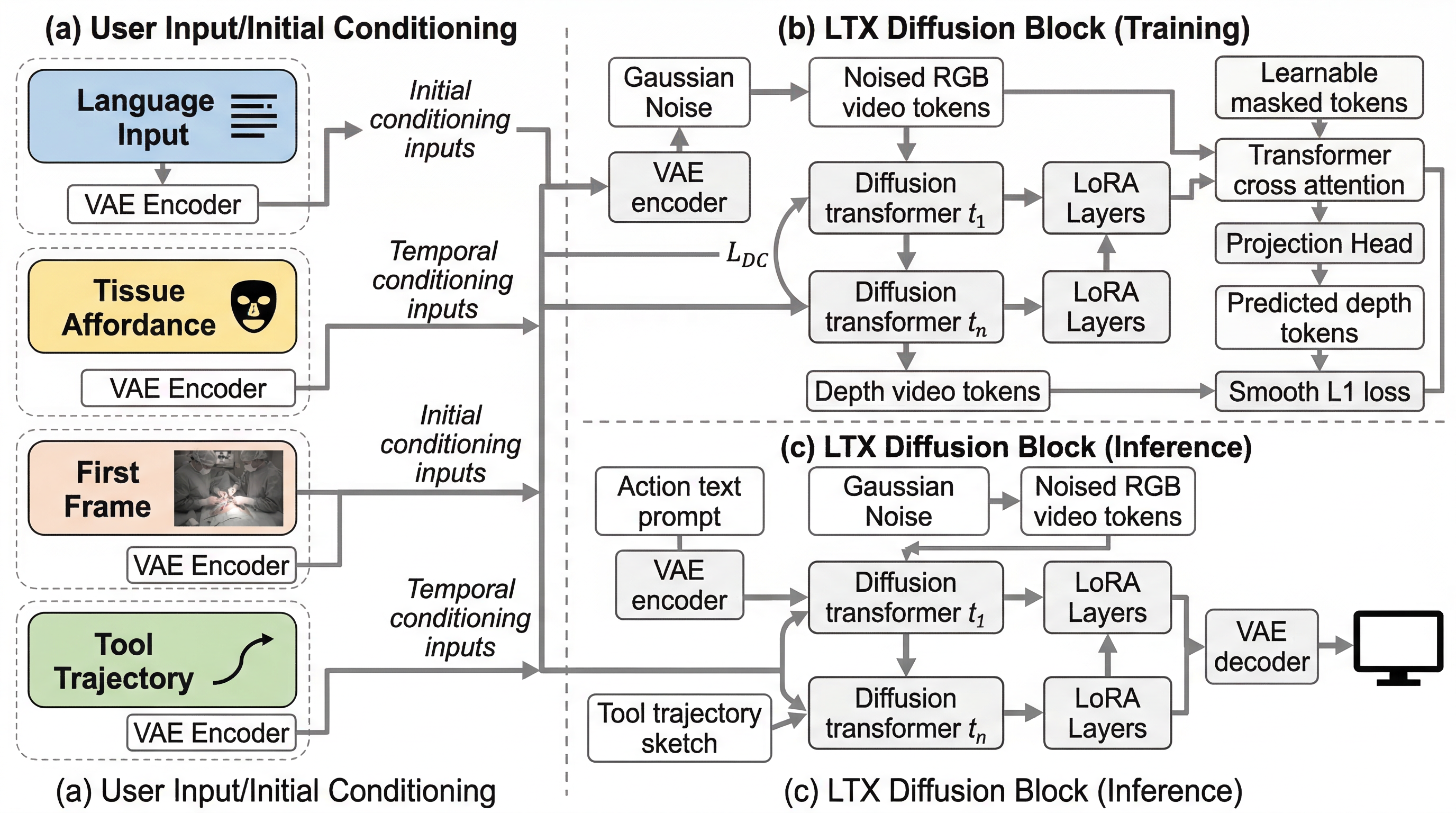
外科AIでは、まれな手技の学習データ不足と、現実に近いシミュレーション不足が同時にボトルネックになっており、動画生成がその橋渡し役として期待されています。 SAWは、言語指示、最初の1フレーム、組織アフォーダンス、器具先端の2次元軌跡という4つの軽量条件だけで、腹腔鏡手技動画を制御生成する拡散モデルです。 12,044本の手技クリップで学習した結果、時間的一貫性で既存法を大きく上回り、希少手技の認識精度改善やシミュレータ由来軌跡からの映像生成にもつながることを示しました。
論文図解
TL;DR(結論)
- 外科AIでは、まれな手技の学習データ不足と、現実に近いシミュレーション不足が同時にボトルネックになっており、動画生成がその橋渡し役として期待されています。
- SAWは、言語指示、最初の1フレーム、組織アフォーダンス、器具先端の2次元軌跡という4つの軽量条件だけで、腹腔鏡手技動画を制御生成する拡散モデルです。
- 12,044本の手技クリップで学習した結果、時間的一貫性で既存法を大きく上回り、希少手技の認識精度改善やシミュレータ由来軌跡からの映像生成にもつながることを示しました。
なぜこの問題か
腹腔鏡手術のAIでは、映像理解とシミュレーションの両方で「ほしいデータが足りない」という問題が重くのしかかります。まず認識側では、切開やクリッピングのような重要だが出現頻度の低い行為は、学習データが極端に少なくなりがちです。多数派の剥離や把持に比べて標本数が少ないため、分類器は少数クラスをうまく覚えられません。しかも外科映像は、煙、血液、反射、視野移動、器具の遮蔽といった乱れが日常的に混ざるため、単に枚数を増やせば済む話でもありません。
核心:何を提案したのか
提案の中心は SAW(Surgical Action World)です。狙いは、手術映像の見た目だけを真似る生成器ではなく、器具がどこをどう動き、どの組織に作用しているのかを条件として受け取り、意図した手技動画を合成できる「外科アクション世界モデル」への第一歩を作ることにあります。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related