視覚トークン圧縮下における大規模視覚言語モデルの敵対的堅牢性について
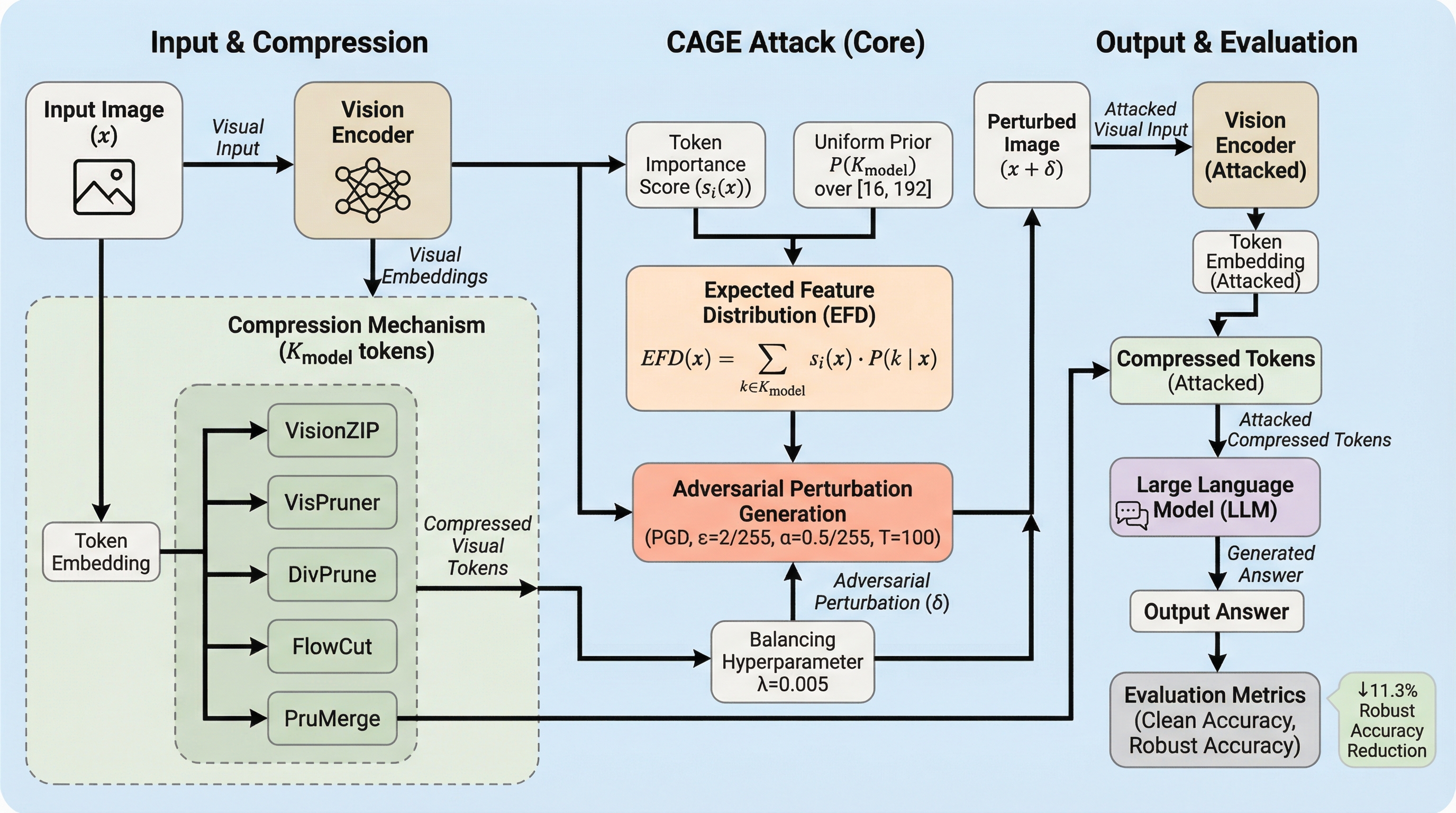
大規模視覚言語モデル(LVLM)の効率化に不可欠な視覚トークン圧縮技術は、敵対的攻撃による歪みを重要なトークンに集中させる「歪み濃縮器」として機能し、既存の評価手法ではモデルの脆弱性を過小評価してしまう問題を明らかにした。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模視覚言語モデル(LVLM)の効率化に不可欠な視覚トークン圧縮技術は、敵対的攻撃による歪みを重要なトークンに集中させる「歪み濃縮器」として機能し、既存の評価手法ではモデルの脆弱性を過小評価してしまう問題を明らかにした。
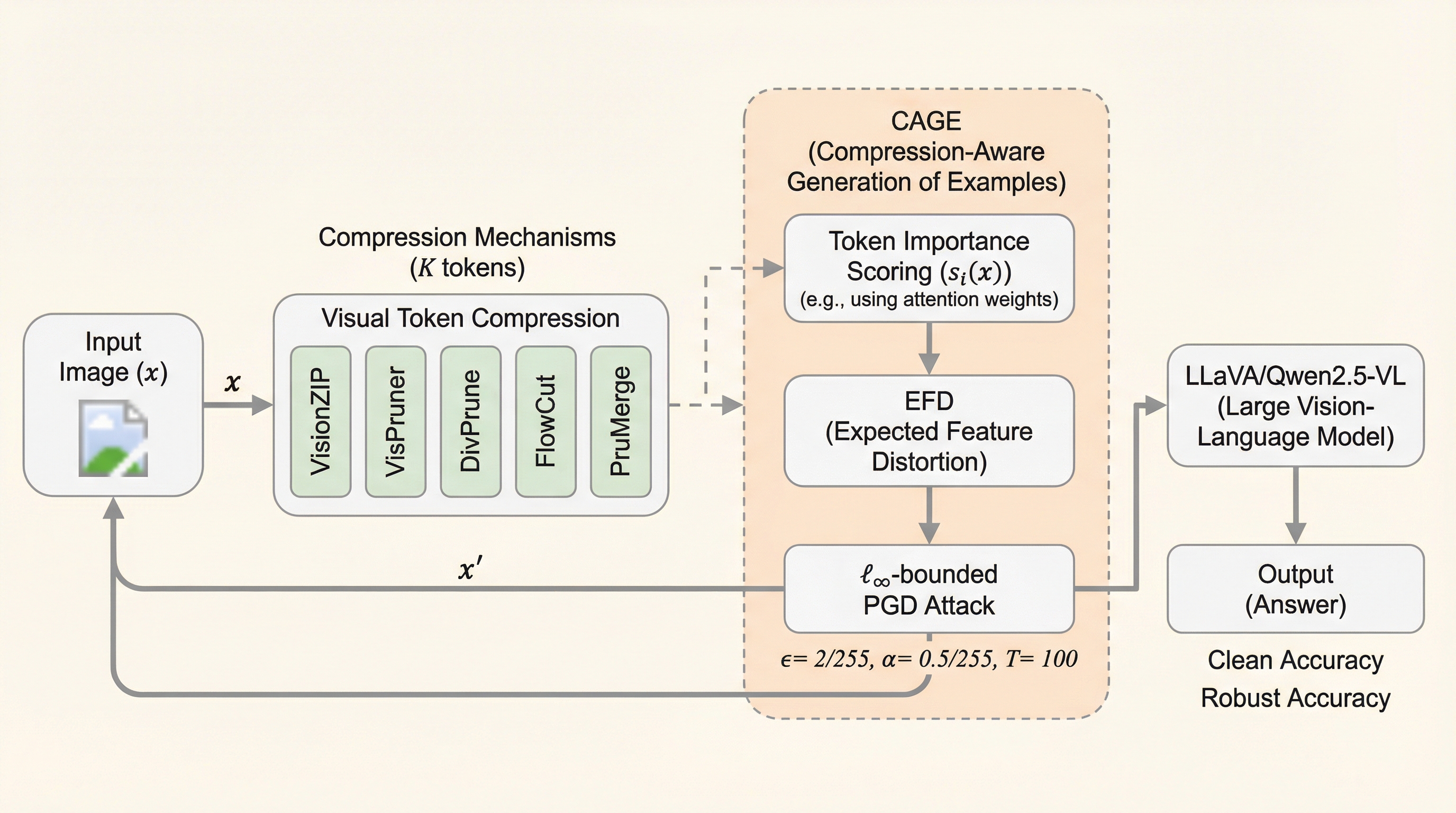
大規模視覚言語モデル(LVLM)の効率化に不可欠な視覚トークン圧縮技術が、敵対的攻撃に対する堅牢性を不当に高く見せかける「最適化と推論の不一致」を引き起こしていることを解明しました。 この問題を解決するため、モデルの圧縮設定が未知の状態でも、生存確率に基づき重要なトークンへ歪みを集中させるEFDと、歪んだトークンを優先的に選択させるRDAを組み合わせた新手法CAGEを提案しました。 検証の結果、圧縮はノイズ除去ではなく「歪みの濃縮器」として機能しており、提案手法は既存の攻撃を大幅に上回る成功率を達成し、効率的なモデルにおける新たなセキュリティ上の脅威を浮き彫りにしました。
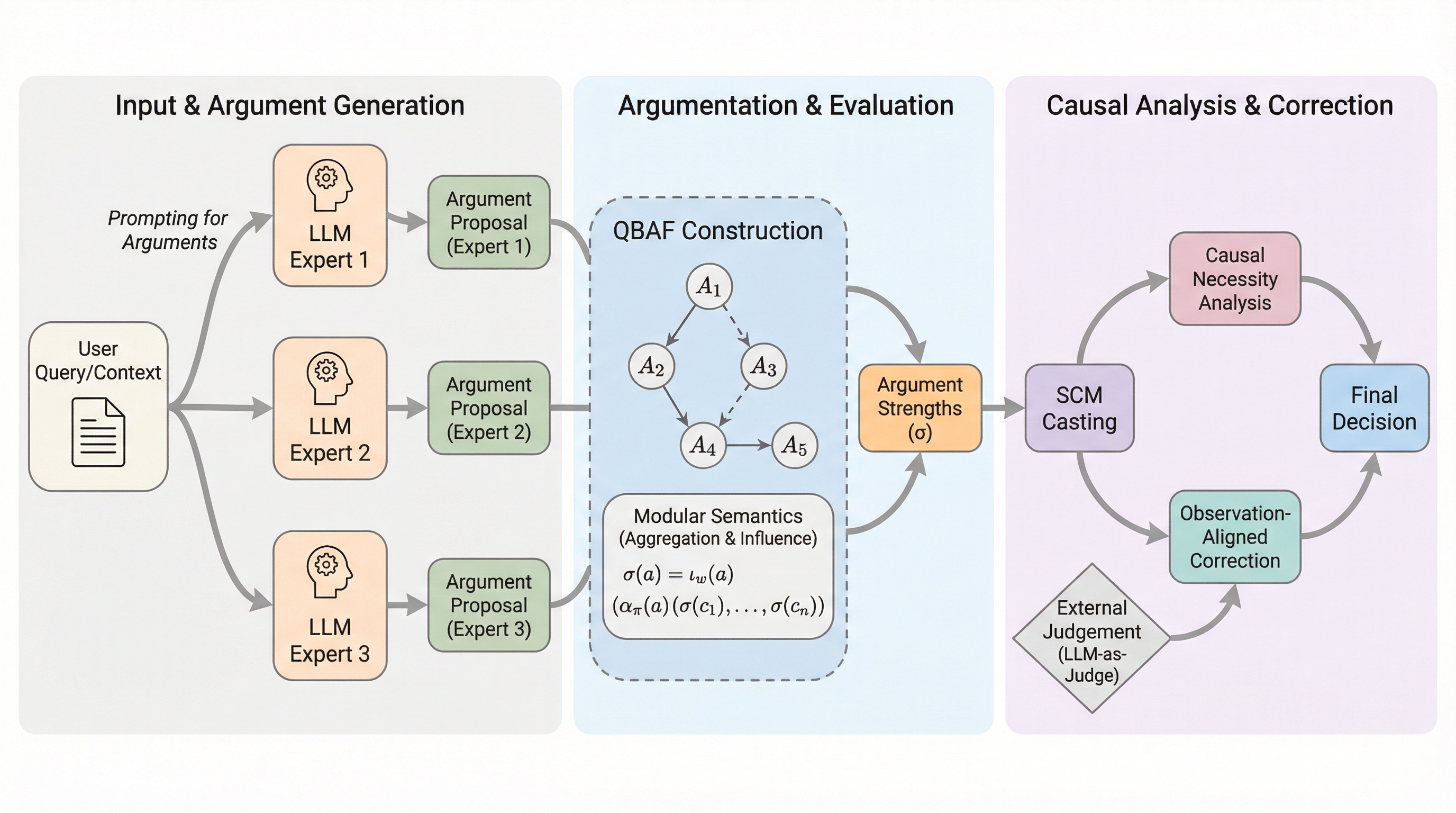
ARGORAは、複数のLLM専門家による議論を「定量的双極議論フレームワーク(QBAF)」としてグラフ構造化し、それを「構造的因果モデル(SCM)」として解釈することで、数学的な因果関係に基づいた意思決定を可能にする新しいフレームワークです。
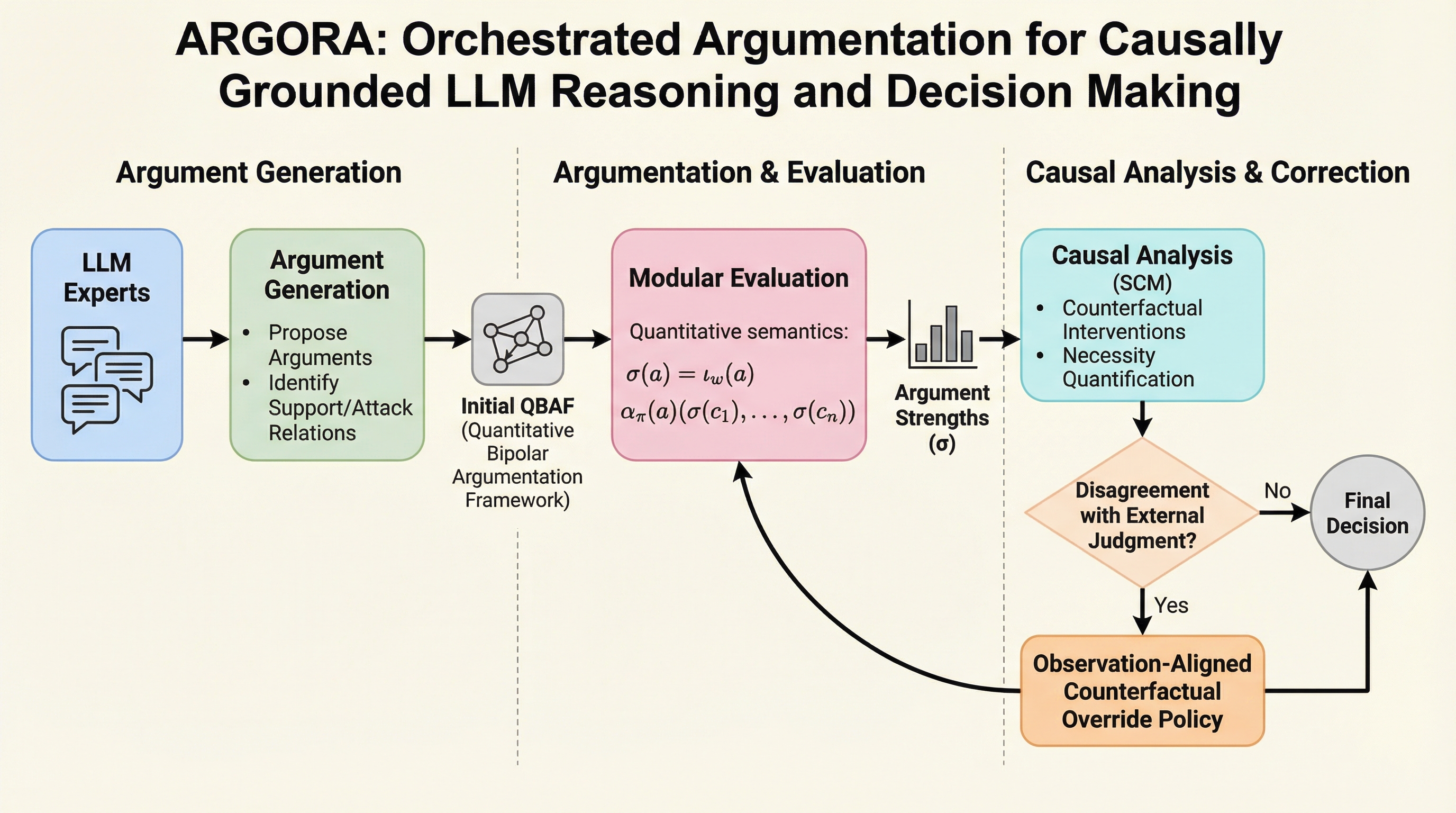
ARGORAは、複数の大規模言語モデルによる議論を「定量的双極議論フレームワーク(QBAF)」という明示的なグラフ構造に整理し、どの主張が最終的な意思決定に寄与したかを特定する新しいフレームワークです。
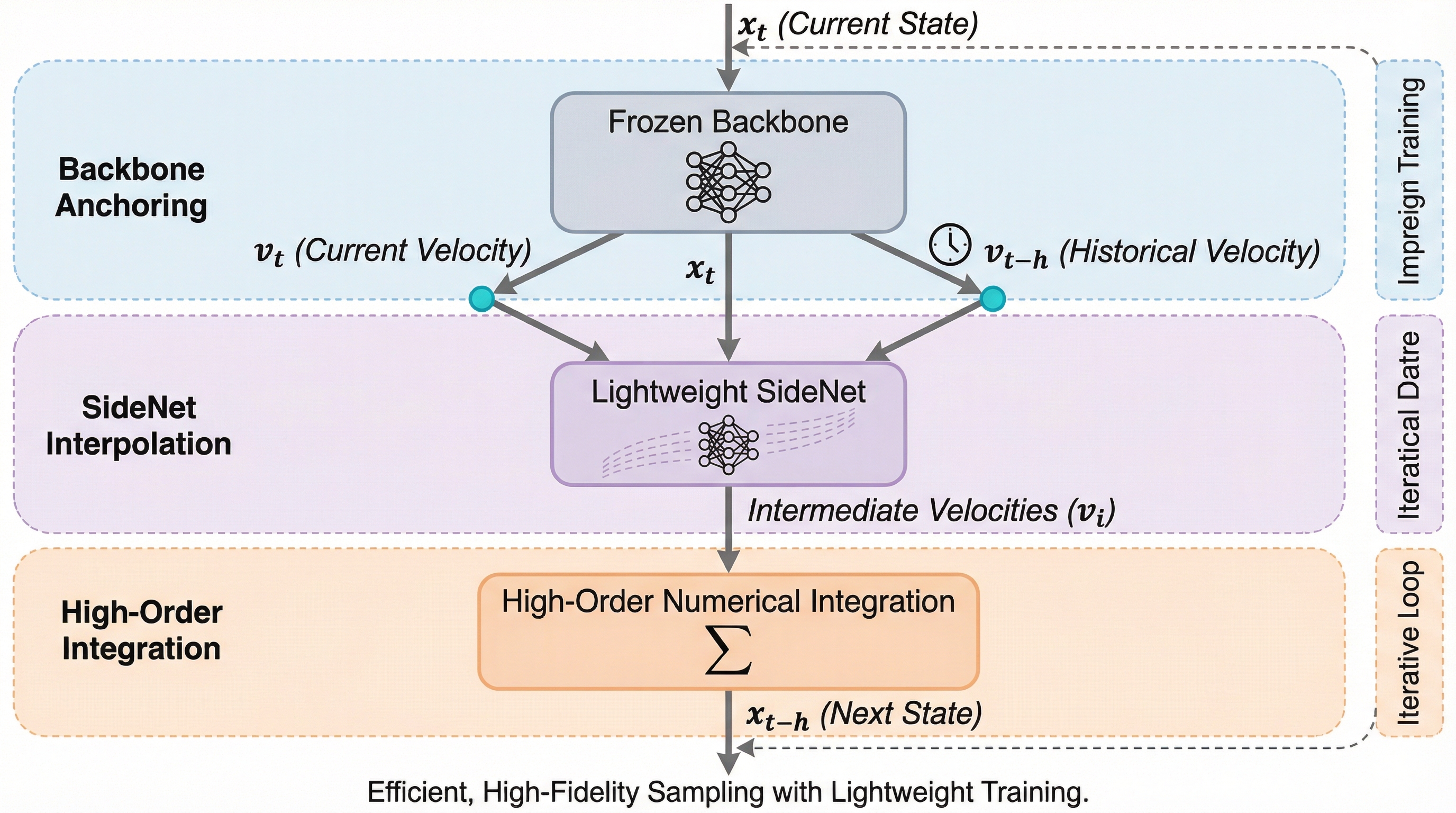
Flow Matching(FM)モデルの生成速度を劇的に向上させるため、巨大なバックボーンを凍結したまま、わずか1〜2%のサイズである軽量なSideNetを追加して高精度な軌道補間を行う「BA-solver」が提案されました。
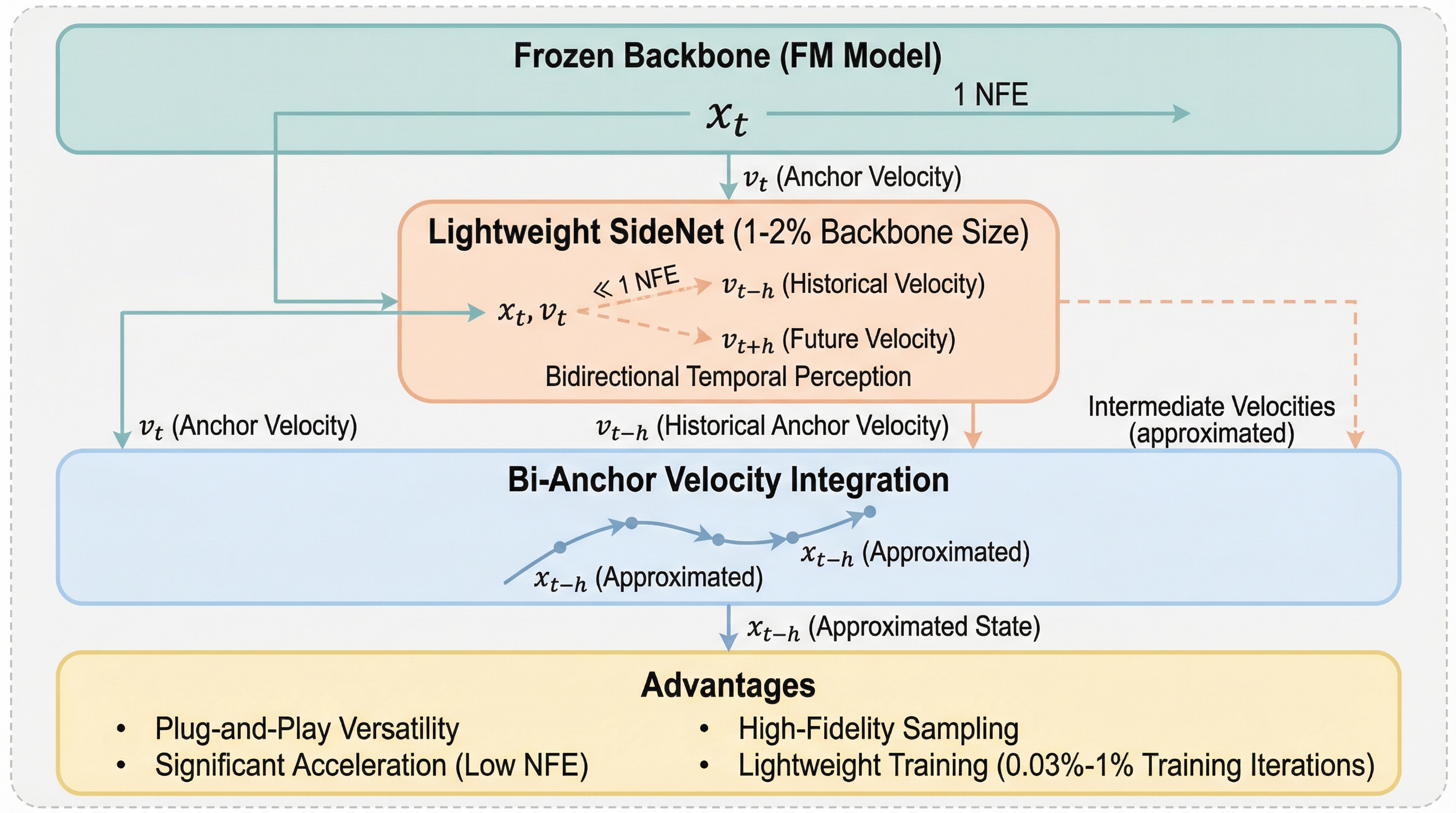
Flow Matching(FM)モデルの生成速度を向上させるため、既存の巨大なバックボーンモデルを凍結したまま、その1〜2%程度の極めて軽量な「SideNet」を追加して双方向の時間を知覚させる「BA-solver」が提案されました。
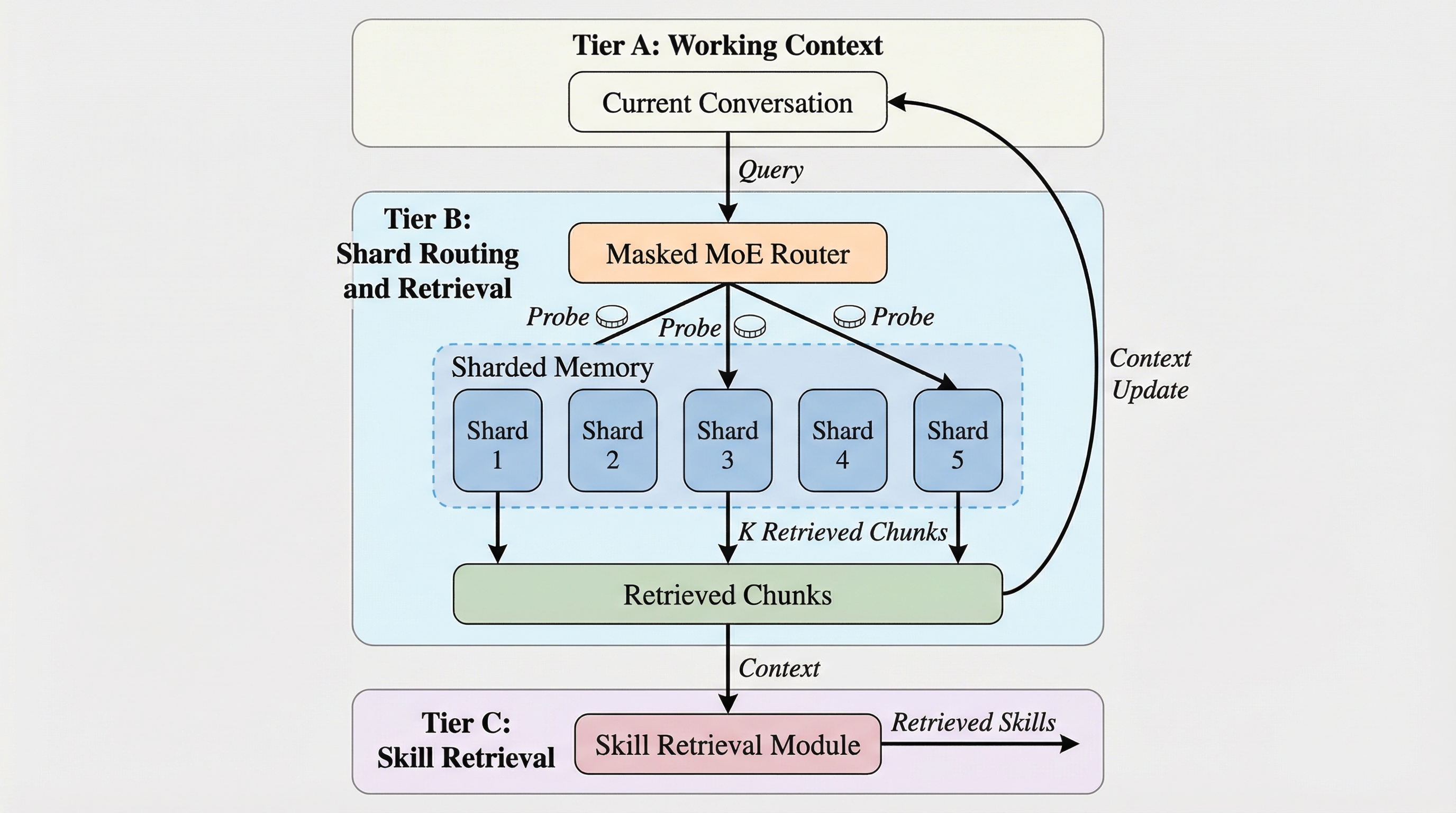
エージェント型LLMシステムにおいて、メモリ量の増大と並列アクセスの増加に伴う中央集権的なインデックスのボトルネックを解消するため、3層構造の予算制約付きメモリサービスであるShardMemoが提案されました。
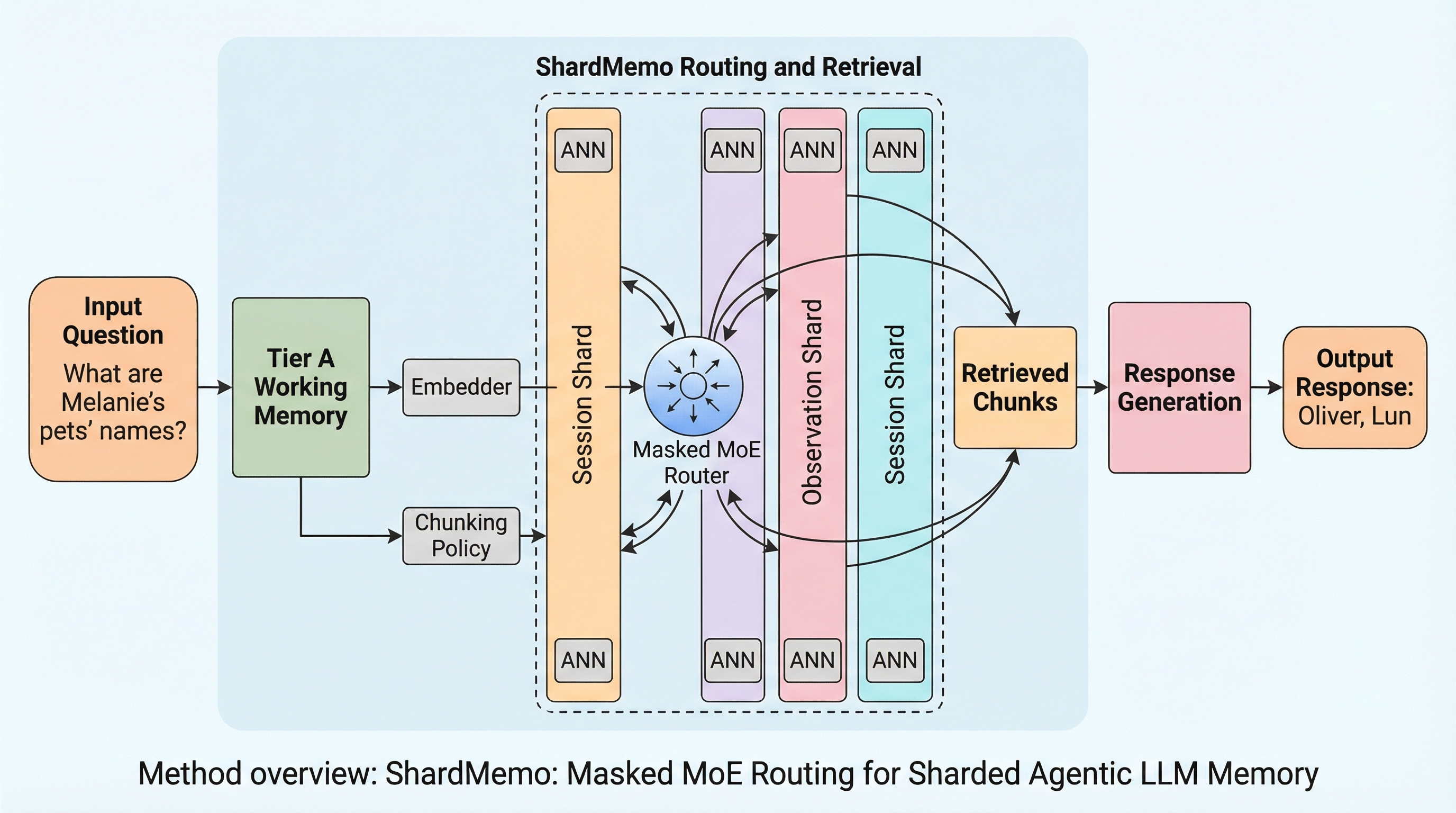
ShardMemoは、エージェント型LLMのために設計された階層型メモリサービスであり、作業状態(Tier A)、シャード化された証拠(Tier B)、スキルライブラリ(Tier C)の3層構造によって、大規模なメモリへの効率的なアクセスを実現します。
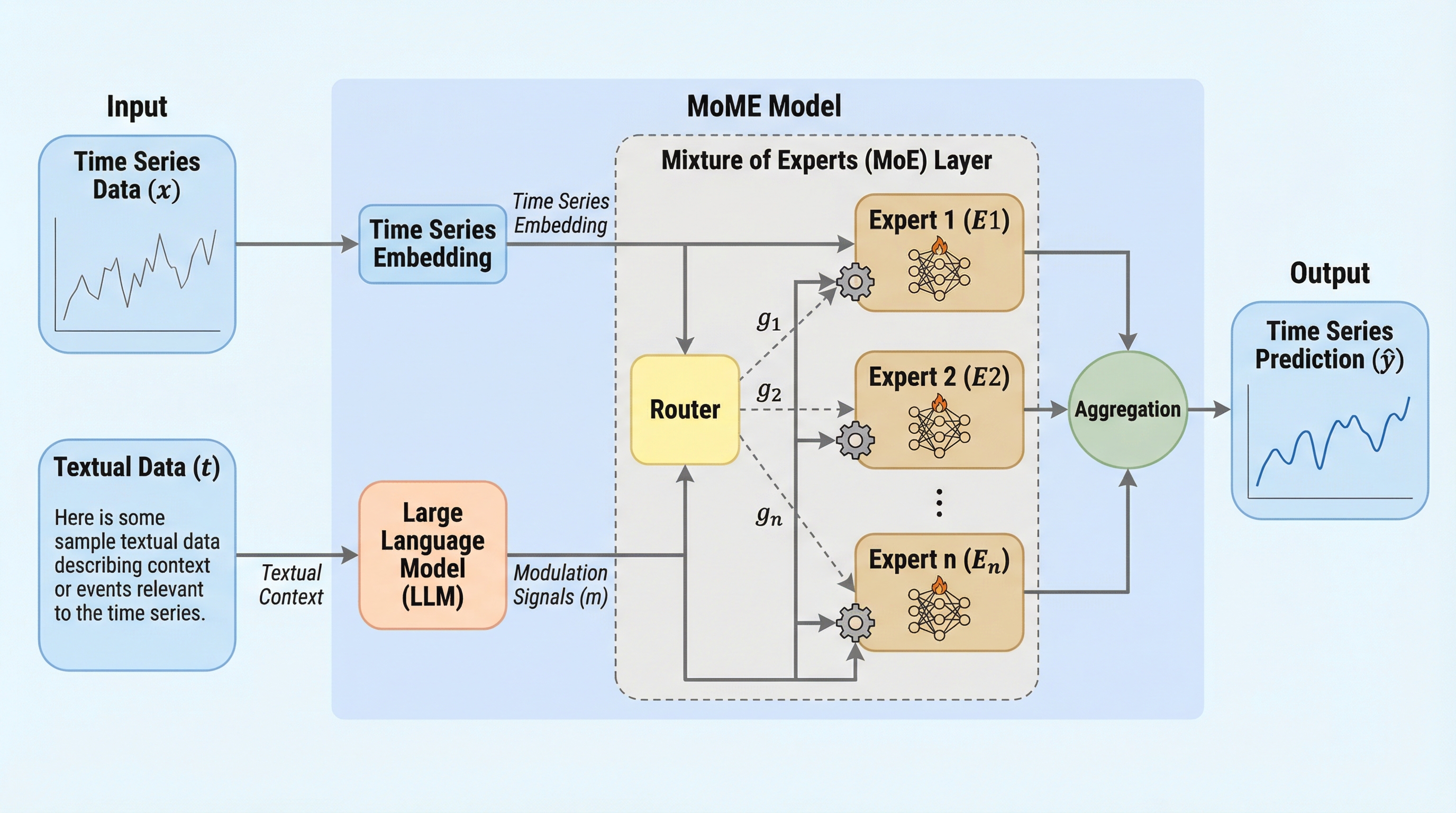
従来のマルチモーダル時系列予測で主流だった、数値データとテキストデータを共通の潜在空間で直接混ぜ合わせる「トークンレベルの融合」に代わり、テキスト情報を用いて時系列エキスパートの計算とルーティングを直接制御する「エキスパート変調(Expert Modulation)」という新しいパラダイムを提案した。
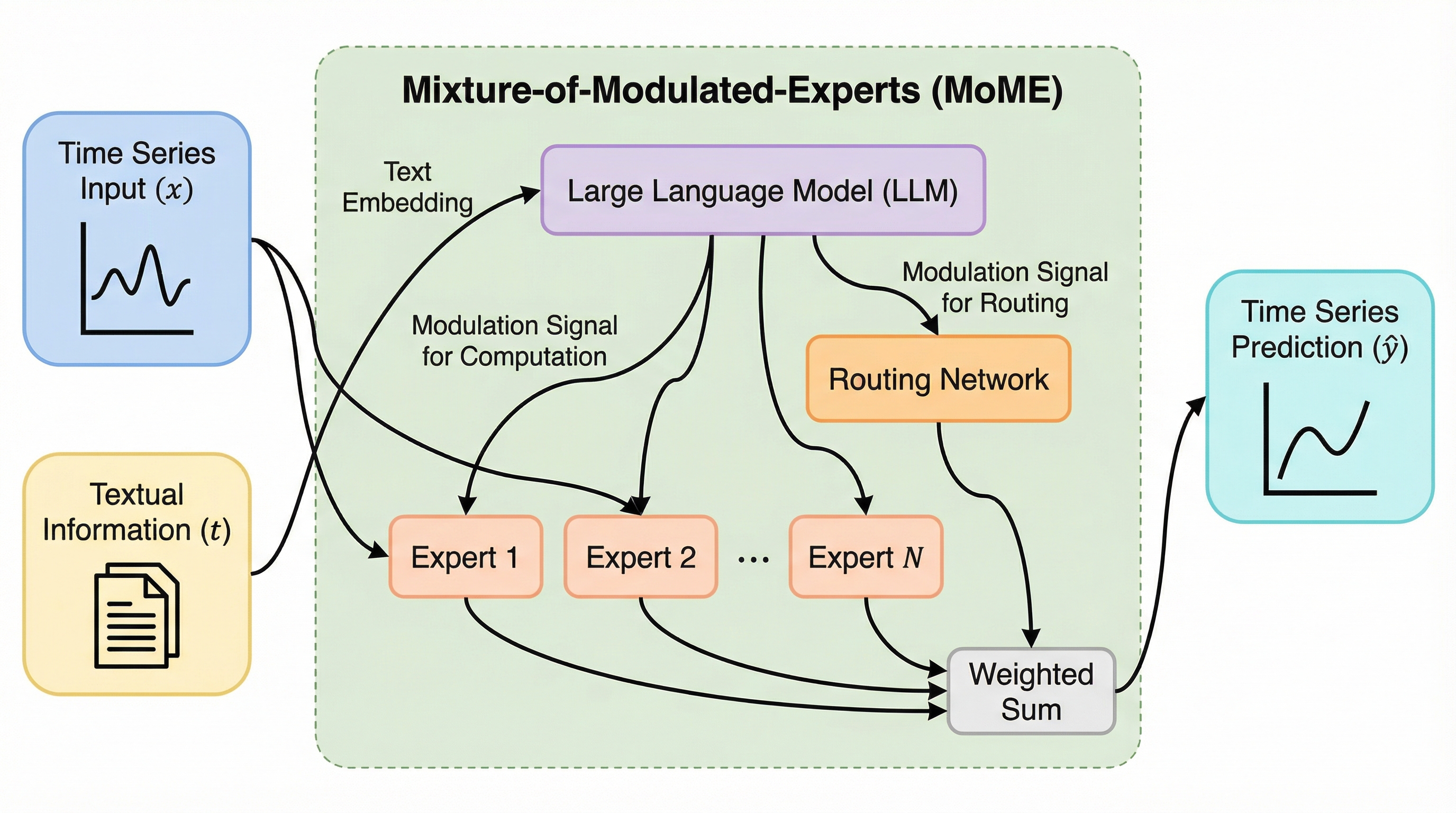
現実世界の時系列予測において、数値データとニュース等のテキスト情報を統合する際、従来のトークンレベルの融合ではノイズやデータの異質性が課題となっていたが、本研究ではテキスト信号が専門家(エキスパート)の選択と計算を直接制御する「Expert Modulation」という新しい枠組みを提案した。