視覚トークン圧縮下における大規模視覚言語モデルの敵対的堅牢性について
大規模視覚言語モデル(LVLM)の効率化に不可欠な視覚トークン圧縮技術が、敵対的攻撃に対する堅牢性を不当に高く見せかける「最適化と推論の不一致」を引き起こしていることを解明しました。 この問題を解決するため、モデルの圧縮設定が未知の状態でも、生存確率に基づき重要なトークンへ歪みを集中させるEFDと、歪んだトークンを優先的に選択させるRDAを組み合わせた新手法CAGEを提案しました。 検証の結果、圧縮はノイズ除去ではなく「歪みの濃縮器」として機能しており、提案手法は既存の攻撃を大幅に上回る成功率を達成し、効率的なモデルにおける新たなセキュリティ上の脅威を浮き彫りにしました。
TL;DR(結論)
大規模視覚言語モデル(LVLM)の効率化に不可欠な視覚トークン圧縮技術が、敵対的攻撃に対する堅牢性を不当に高く見せかける「最適化と推論の不一致」を引き起こしていることを解明しました。 この問題を解決するため、モデルの圧縮設定が未知の状態でも、生存確率に基づき重要なトークンへ歪みを集中させるEFDと、歪んだトークンを優先的に選択させるRDAを組み合わせた新手法CAGEを提案しました。 検証の結果、圧縮はノイズ除去ではなく「歪みの濃縮器」として機能しており、提案手法は既存の攻撃を大幅に上回る成功率を達成し、効率的なモデルにおける新たなセキュリティ上の脅威を浮き彫りにしました。
なぜこの問題か
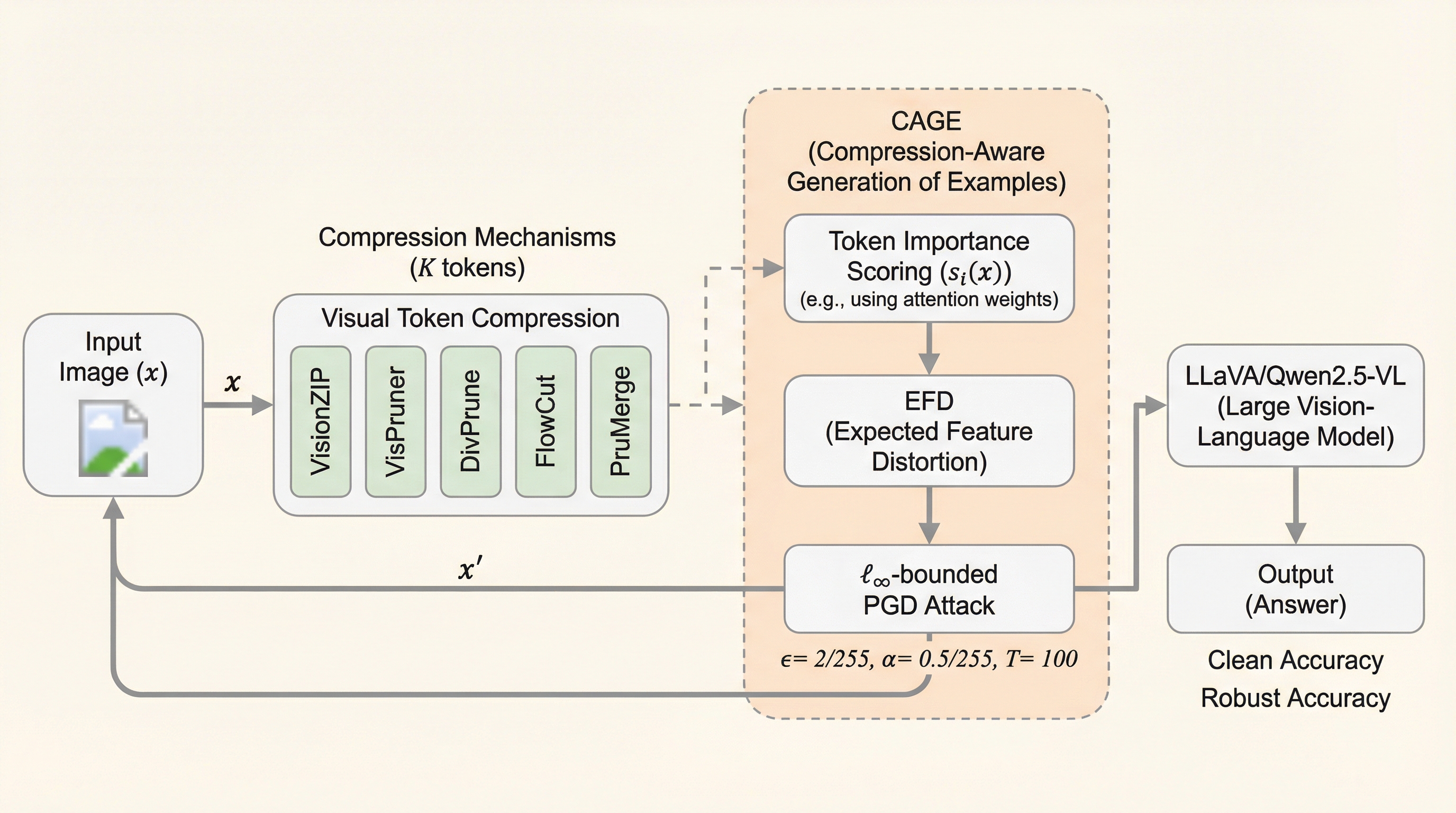
大規模視覚言語モデル(LVLM)は、画像理解や複雑な推論において驚異的な能力を発揮していますが、その計算コストの高さが実用化の大きな壁となっています。特にLLaVA-NeXTやInternVLといった最新のモデルは、1枚の画像から数百から数千もの視覚トークンを生成するため、モバイルデバイスやリアルタイム性が求められるエージェント環境では、遅延やエネルギー消費が深刻な問題となります。この課題を解決するために、VisionZipやVisPrunerといった「視覚トークン圧縮」技術が導入され、アテンションスコアなどを用いて重要なトークンのみを選択・統合することで、精度を維持しつつ計算量を削減しています。しかし、これらの効率化技術がモデルの「敵対的堅牢性」にどのような影響を与えるかは、これまで十分に調査されてきませんでした。 本研究が指摘する最大の懸念は、既存の堅牢性評価手法が、圧縮されたモデルの安全性を過大評価している可能性です。従来の攻撃手法は、画像エンコーダが出力する「全トークン」に対して一様に摂動を加えるように最適化されます。…
核心:何を提案したのか
本研究は、視覚トークン圧縮下にあるLVLMの脆弱性を正確に評価するための新しい攻撃フレームワーク「CAGE(Compression-Aligned Attack)」を提案しました。CAGEの核心的なアイデアは、攻撃の最適化プロセスを、モデルが実際に推論で使用する「圧縮後の特徴空間」に直接整合させることにあります。特筆すべきは、この手法が「グレーボックス」設定、すなわち展開されている圧縮手法の具体的なアルゴリズムや、削減されるトークンの数(トークン予算)が攻撃者にとって未知であるという、極めて現実的で厳しい条件下でも機能するように設計されている点です。 CAGEは、未知の圧縮プロセスを確率的にモデル化することで、この不確実性を克服しています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related