ShardMemo: Masked MoEルーティングを用いたエージェント向け分散メモリ管理
エージェント型LLMシステムにおいて、メモリ量の増大と並列アクセスの増加に伴う中央集権的なインデックスのボトルネックを解消するため、3層構造の予算制約付きメモリサービスであるShardMemoが提案されました。
TL;DR(結論)
エージェント型LLMシステムにおいて、メモリ量の増大と並列アクセスの増加に伴う中央集権的なインデックスのボトルネックを解消するため、3層構造の予算制約付きメモリサービスであるShardMemoが提案されました。 このシステムは、メタデータによる権限や範囲の制約をルーティング前に適用する「Scope-before-routing」を導入し、シャード選択をMasked Mixture-of-Experts(MoE)ルーティングとして定式化することで、効率的かつ正確な証拠検索を実現しています。 検証の結果、既存の強力なベースラインであるGAMと比較してLoCoMoベンチマークで最大6.82ポイントのF1スコア向上を達成し、同時に検索時のベクトルスキャン数を20.5%削減、p95レイテンシを19ms短縮することに成功しました。
なぜこの問題か
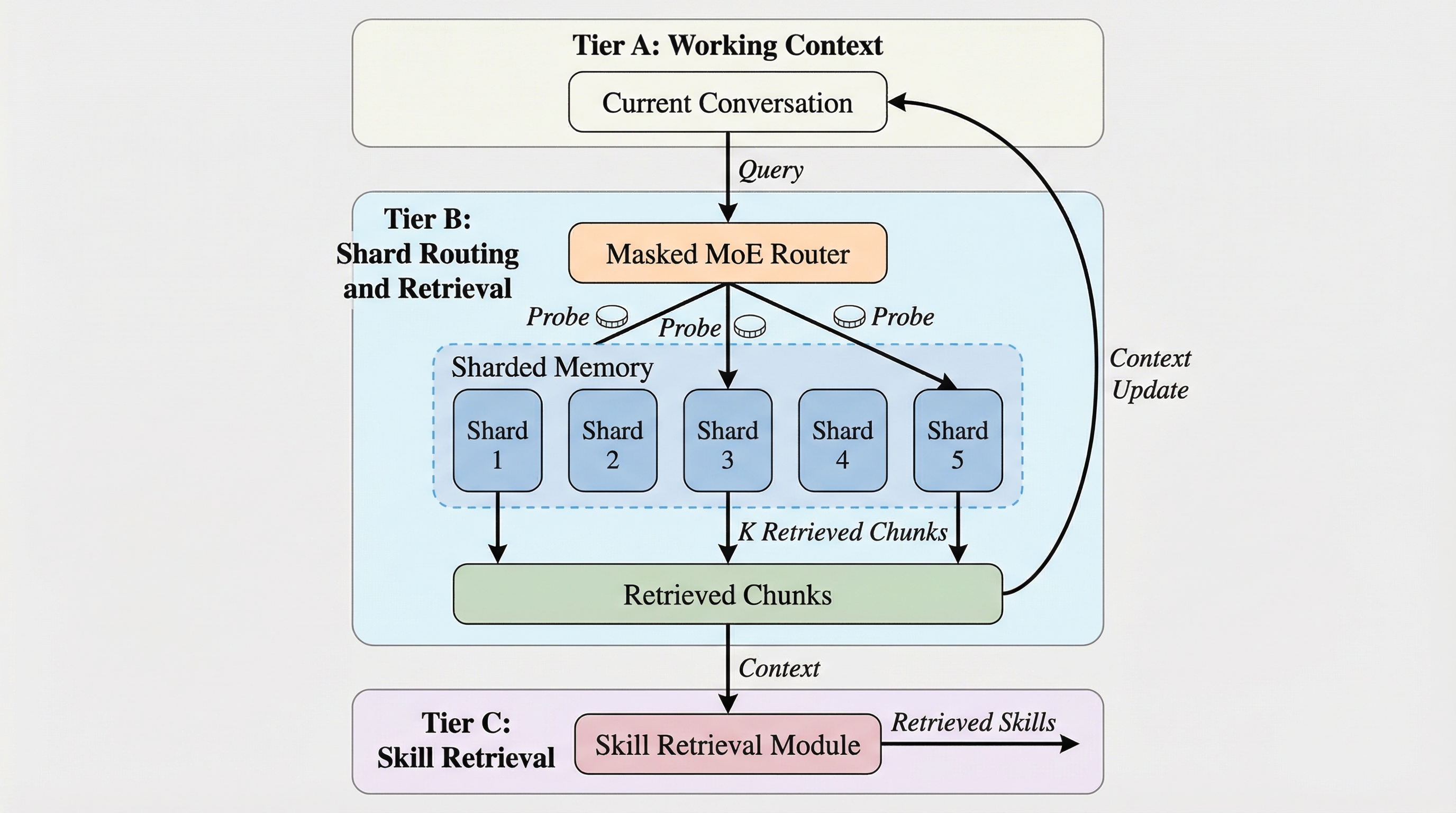
エージェント型の大規模言語モデル(LLM)システムは、長期的なタスクの実行や複数のエージェントによる同時並行的な処理を行うために、外部メモリに大きく依存しています。これらのシステムは、目標をサブタスクに分解し、ツールの呼び出しと検証を繰り返し、相互作用を通じて経験を蓄積していく長期的なプログラムとして動作します。しかし、デプロイメントの規模が拡大するにつれて、メモリへのアクセスがシステム全体のボトルネックとなる問題が顕在化しています。具体的には、コーパスのサイズが大きくなるほど検索コストが増大し、共有インデックスに対する読み取りと書き込みの競合が発生し、負荷が高まるにつれてテールレイテンシが悪化するという課題があります。 また、エージェントのワークロードにおけるメモリへのアクセスは、その内容と意図の両面において非常に異質です。多くのリクエストは長期的な対話ログから宣言的な証拠を検索することを必要としますが、一方で、以前に成功したツールの使用手順を再利用することで利益を得るリクエストもあります。これらすべてのケースを単一の検索問題として扱うことは、コンテキストへの圧迫を強め、システムの信頼性を低下させる要因となります。…
核心:何を提案したのか
本論文では、エージェント型LLMのために、スコアの正確性と予算制約を強制する階層型メモリサービス「ShardMemo」を提案しています。このシステムは、メモリを役割に応じて3つのティア(層)に分離して管理します。まず「Tier A」は、エージェントごとの作業状態を保持する層であり、短期間のコンテキストを安定させるために容量制限が設けられています。次に「Tier B」は、シャード化された証拠メモリであり、各シャードは独自の近似最近傍探索(ANN)インデックスを持つ「エキスパート」として扱われます。最後に「Tier C」は、バージョン管理されたスキルライブラリであり、再利用可能な手順を格納します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related