視覚トークン圧縮下における大規模視覚言語モデルの敵対的堅牢性について
大規模視覚言語モデル(LVLM)の効率化に不可欠な視覚トークン圧縮技術は、敵対的攻撃による歪みを重要なトークンに集中させる「歪み濃縮器」として機能し、既存の評価手法ではモデルの脆弱性を過小評価してしまう問題を明らかにした。
TL;DR(結論)
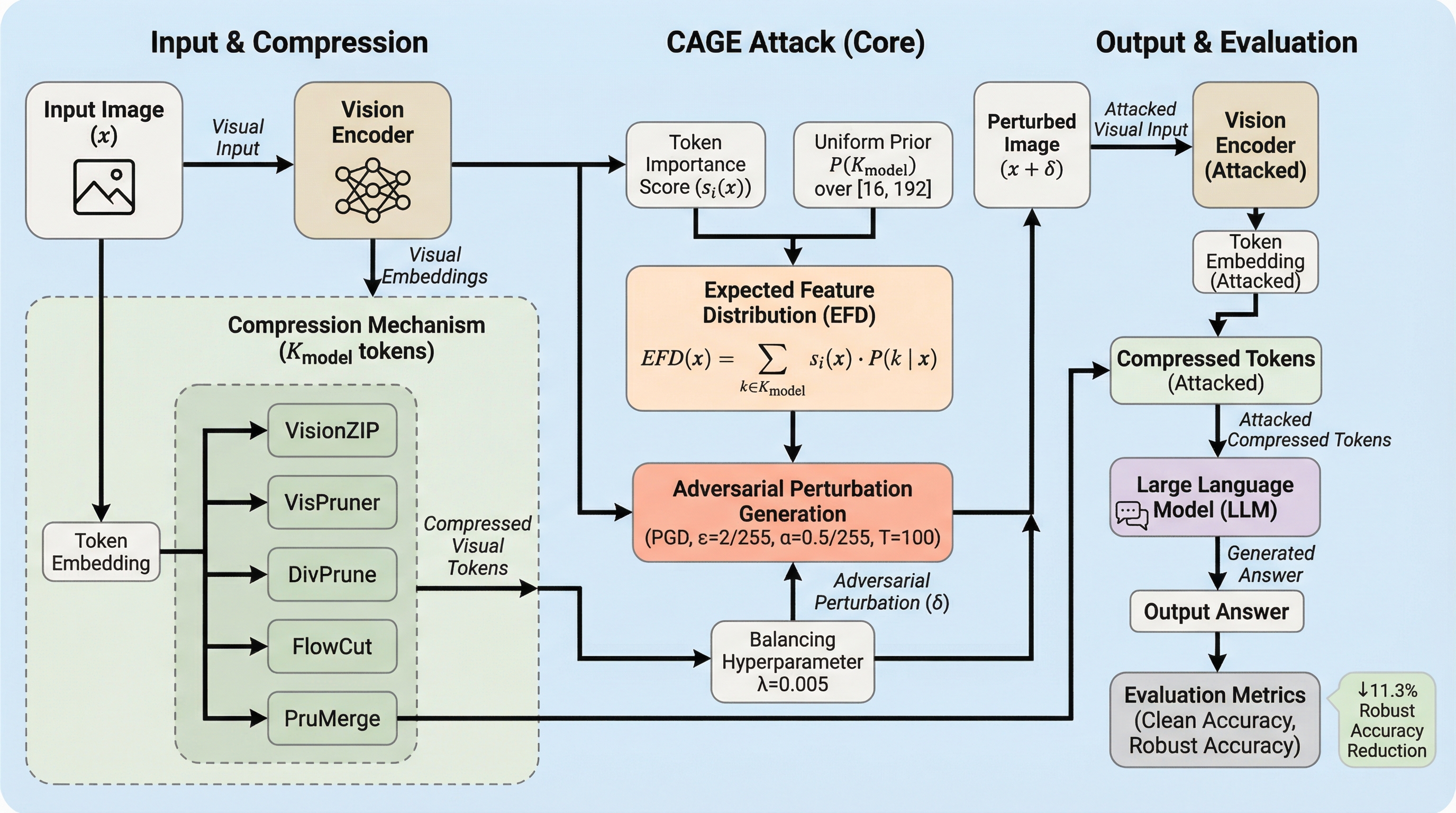
大規模視覚言語モデル(LVLM)の効率化に不可欠な視覚トークン圧縮技術は、敵対的攻撃による歪みを重要なトークンに集中させる「歪み濃縮器」として機能し、既存の評価手法ではモデルの脆弱性を過小評価してしまう問題を明らかにした。 この最適化と推論の不一致を解消するため、展開時の圧縮予算が不明な状況でも生存確率に基づき摂動を集中させる「期待特徴量破壊(EFD)」と、歪んだトークンを優先選択させる「ランク歪みアライメント(RDA)」を組み合わせた新攻撃手法CAGEを提案した。 複数の圧縮メカニズムとデータセットを用いた検証の結果、CAGEは既存手法よりも一貫して高い攻撃成功率を記録し、効率的なLVLMの安全な展開には圧縮プロセスを考慮したセキュリティ評価と新たな防御策の構築が不可欠であることを示した。
なぜこの問題か
大規模視覚言語モデル(LVLM)は、視覚的な質問応答や複雑な推論において極めて高い能力を示しているが、その計算コストの高さが実用化の大きな障壁となっている。特にLLaVA-NeXTやInternVLといった最新のモデルは、1枚の画像に対して数百から数千もの視覚トークンを生成して処理するため、モバイルエージェントのような遅延やエネルギー消費に厳しい制約がある環境では、推論速度がボトルネックとなる。この課題を解決するために、VisionZipやVisPrunerといった視覚トークン圧縮手法が急速に普及している。これらの手法は、アテンションスコアなどの重要度指標に基づいて情報量の多いトークンを選択したり、類似したトークンを統合したりすることで、精度を維持しながら計算負荷を大幅に削減する。 しかし、これらの効率化技術が導入されたLVLMの敵対的堅牢性については、これまで十分に調査されてこなかった。自動運転やロボティクスといった、安全性が極めて重視されるリアルタイムアプリケーションにおいて、トークン圧縮は不可欠な技術になりつつある。…
核心:何を提案したのか
本研究では、既存の攻撃手法と圧縮推論プロセスの間にある最適化の不一致を根本から解消するために、CAGE(CompressionAliGnEd attack)と呼ばれる新しい敵対的攻撃フレームワークを提案している。CAGEの核心は、摂動の最適化をモデルが実際に推論で使用する「圧縮後のトークン空間」に直接適合させることにある。従来の攻撃が画像全体のトークンを無差別に攻撃対象としていたのに対し、CAGEはトークン選択のボトルネックを生き残る可能性が高い特定のトークンセットに摂動エネルギーを集中させる戦略をとる。 CAGEの設計において最も困難な点は、攻撃者がモデルの展開時に実際に使用される具体的な圧縮予算(K_model)や、採用されている具体的な圧縮アルゴリズムの詳細を必ずしも把握していないという現実的な制約である。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related