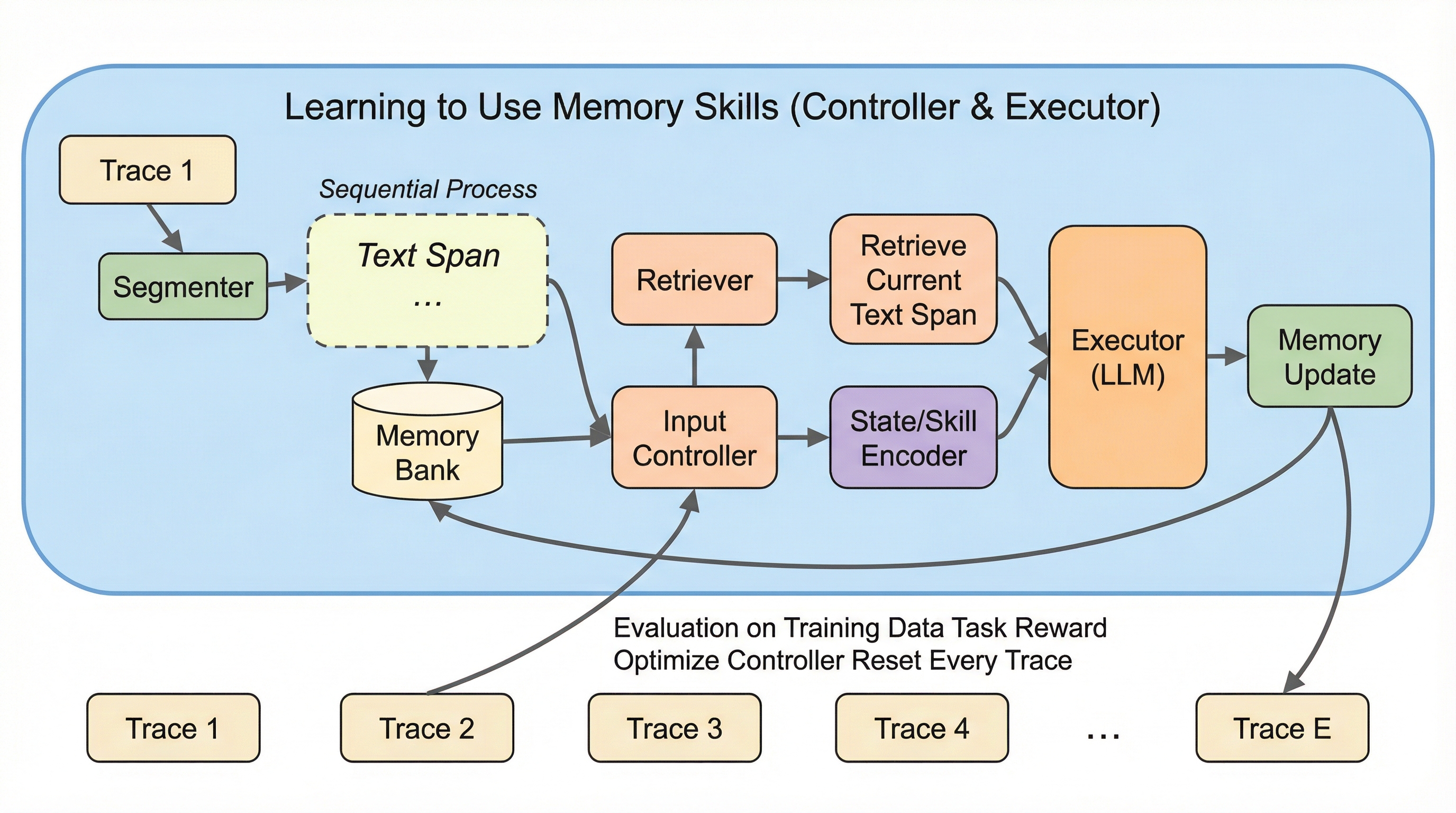
MemSkill:自己進化エージェントのためのメモリスキルの学習と進化
記憶は、LLMエージェントにとって「後から効く力」なのに、なぜ手作業のルールに縛られ続けるのか? 長い履歴を前にすると、いま役に立つ情報だけをうまく掬い上げ、不要になったものを整理し直す――その“当たり前”が、実は固定化された手順に強く依存しているからです。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
記憶は、LLMエージェントにとって「後から効く力」なのに、なぜ手作業のルールに縛られ続けるのか? 長い履歴を前にすると、いま役に立つ情報だけをうまく掬い上げ、不要になったものを整理し直す――その“当たり前”が、実は固定化された手順に強く依存しているからです。
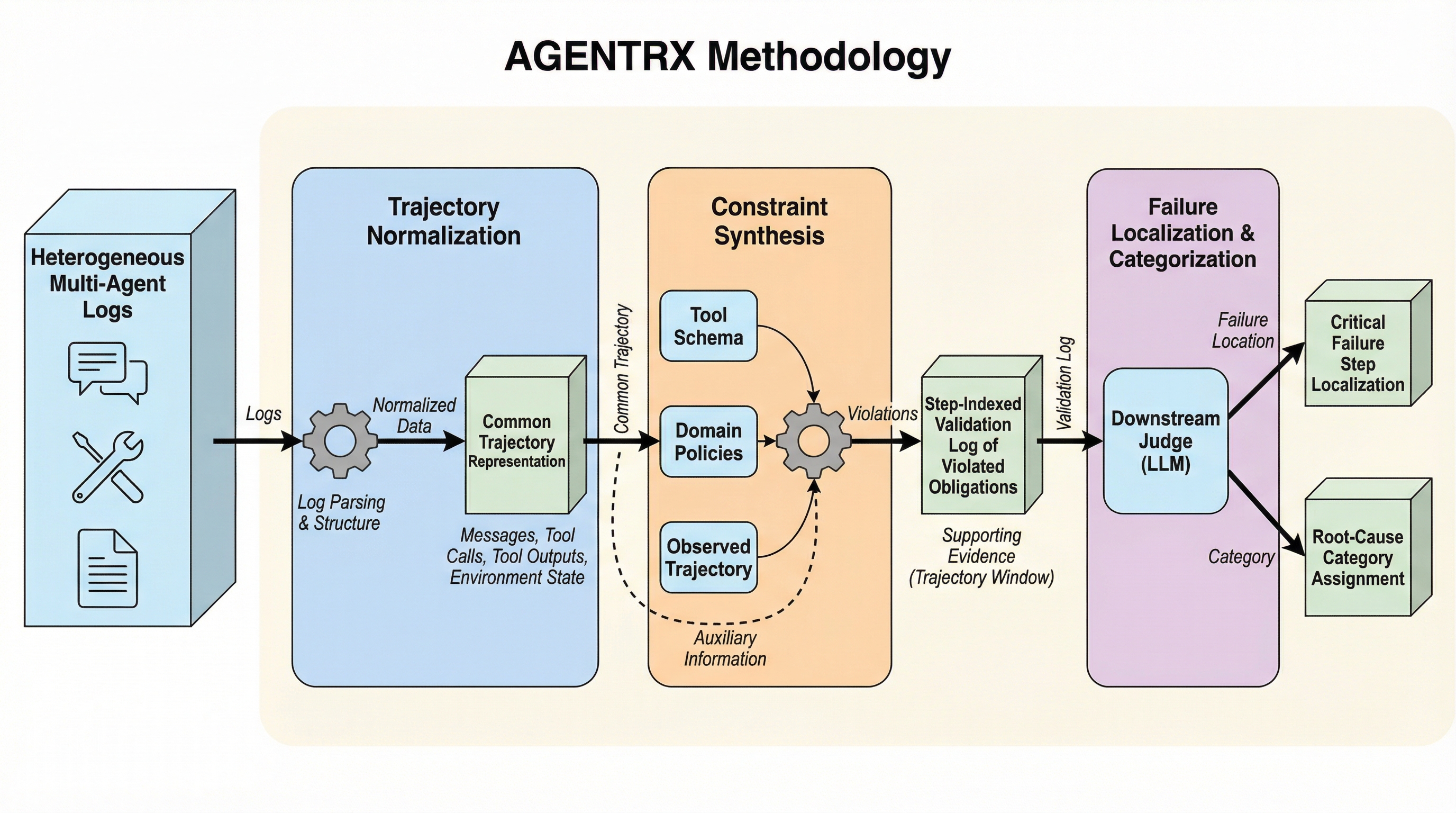
AIエージェントが失敗したとき、「どの一手が致命傷だったのか?」を言い当てられますか? 意外に難しいのは、失敗が“最後の出力”ではなく、長い実行の途中で静かに始まっているからです。 この記事では、失敗の原因を実行軌跡から切り分ける「AgentRx / AGENTRX」が何を狙い、どう動き、何を確かめたのかを読み物として整理します。
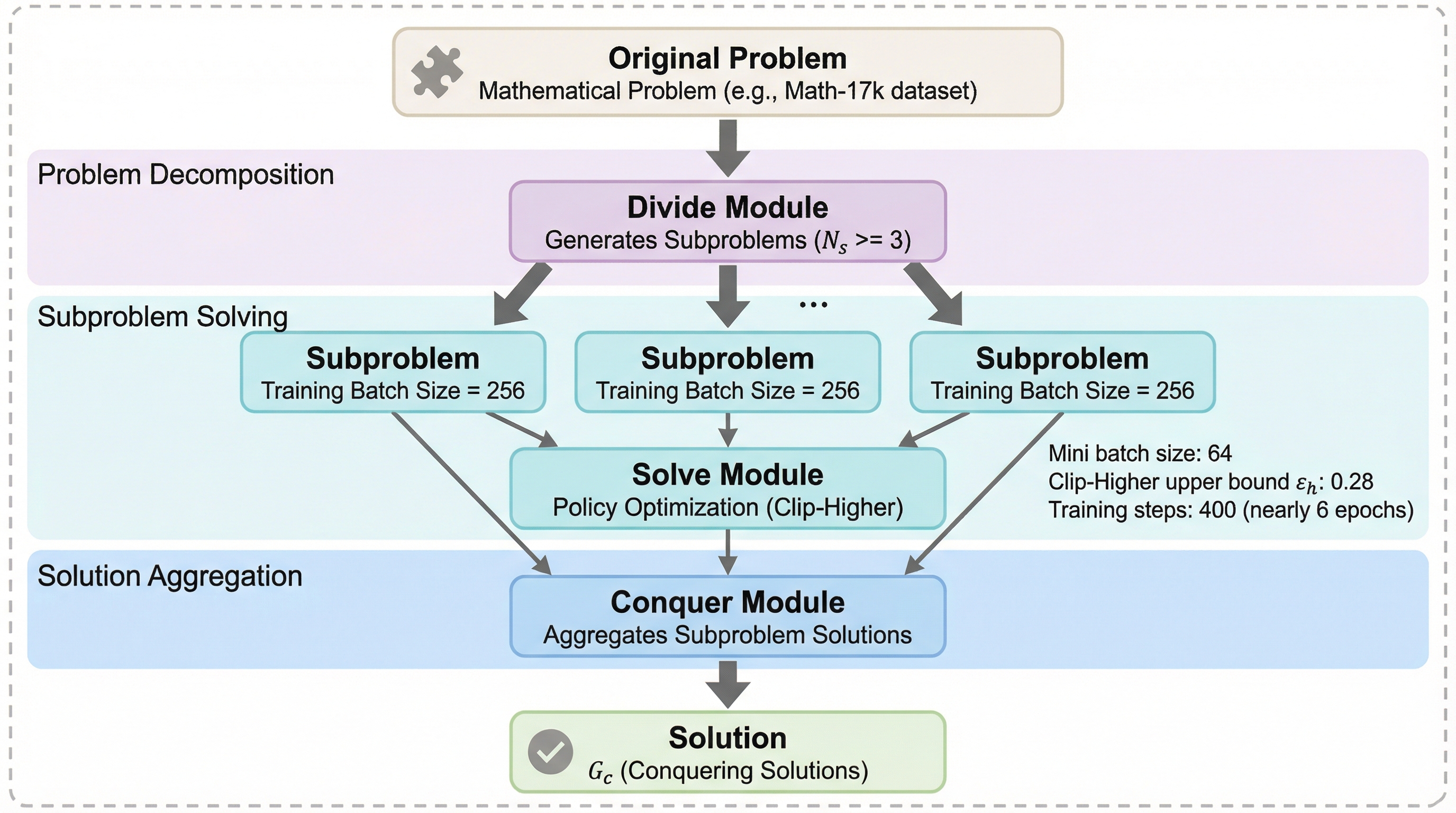
難問に挑むとき、長いチェーン・オブ・ソート(CoT)を伸ばすだけで本当に足りる? 意外にも、分割統治(Divide-and-Conquer)を“推論時に足す”だけでは、多くのモデルでうまく噛み合わない。
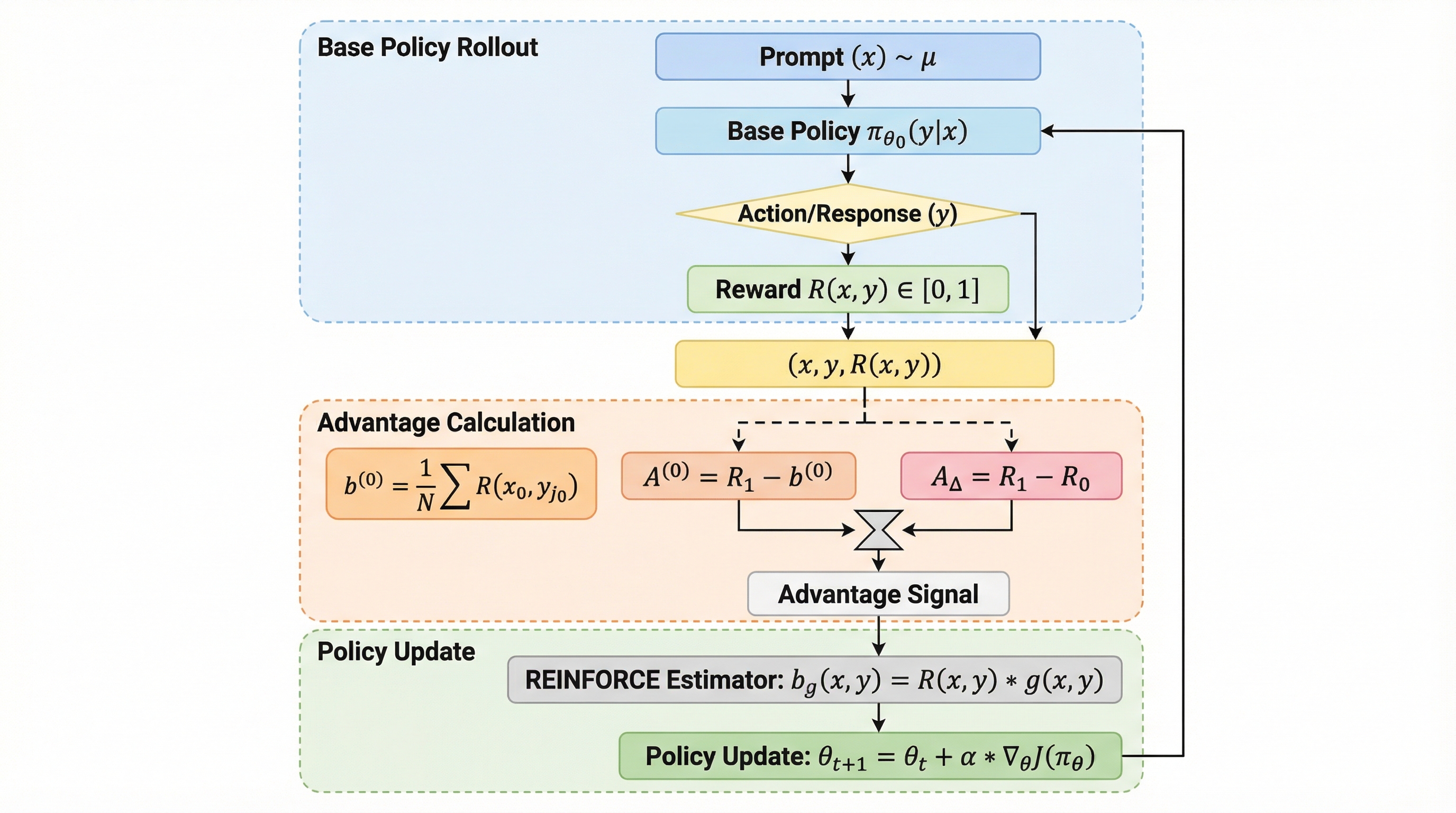
あなたは「一発で良い答え」を求めるのに、学習中のLLMはなぜ“やり取り”に頼りがちなのでしょうか? 実は、RLの学習信号は「正解/不正解」の1ビットに近く、豊かな改善の手がかりを捨てている可能性があります。
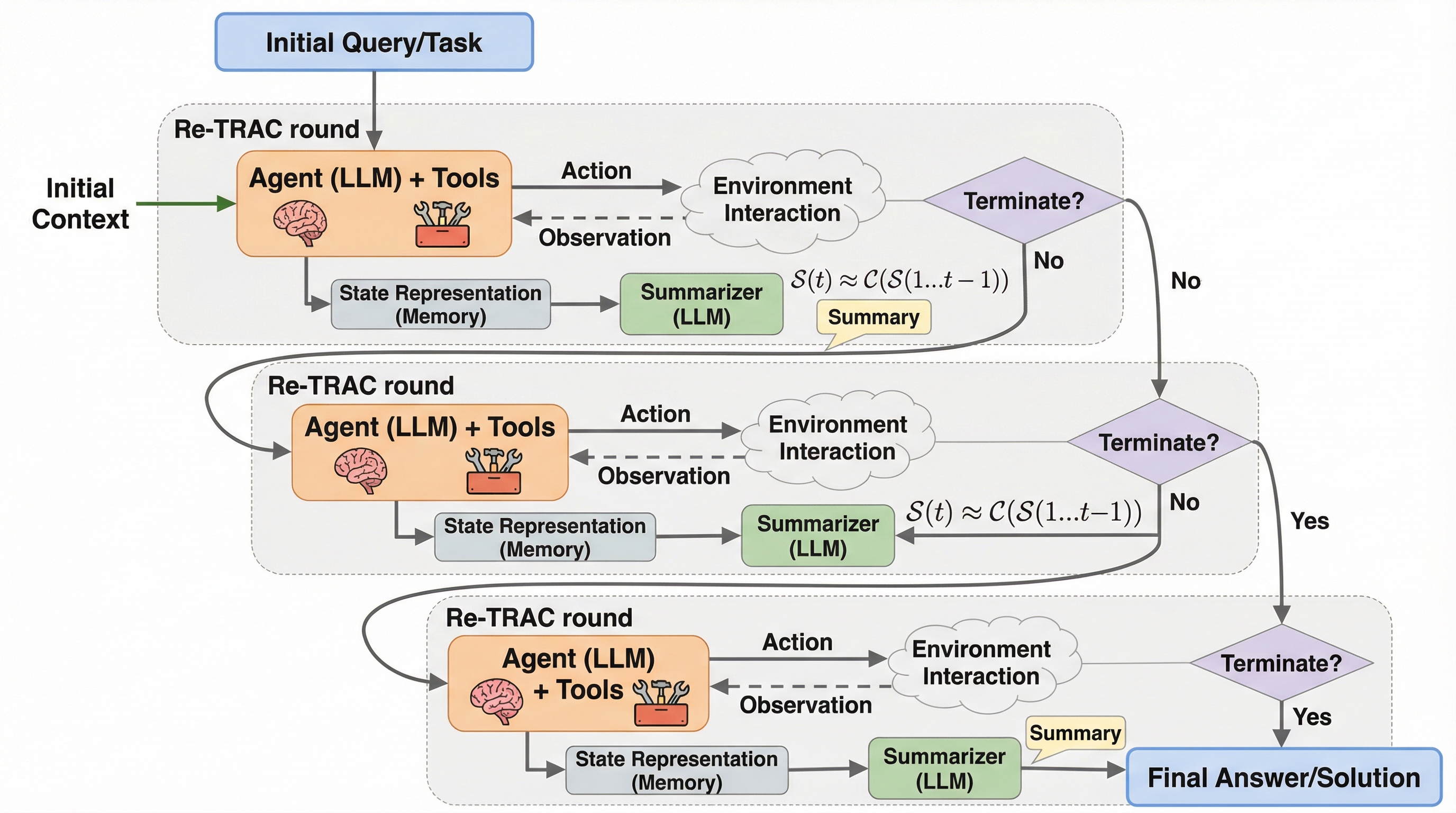
研究エージェントは、なぜ「同じところをぐるぐる回る」のでしょうか? 原因は推論能力ではなく、“探索の形”にある――というのが本論文の出発点です。 この記事では、ReActの直線的な探索を「再帰的に折りたたむ」Re-TRACの狙いと効きどころを、読み物として整理します。
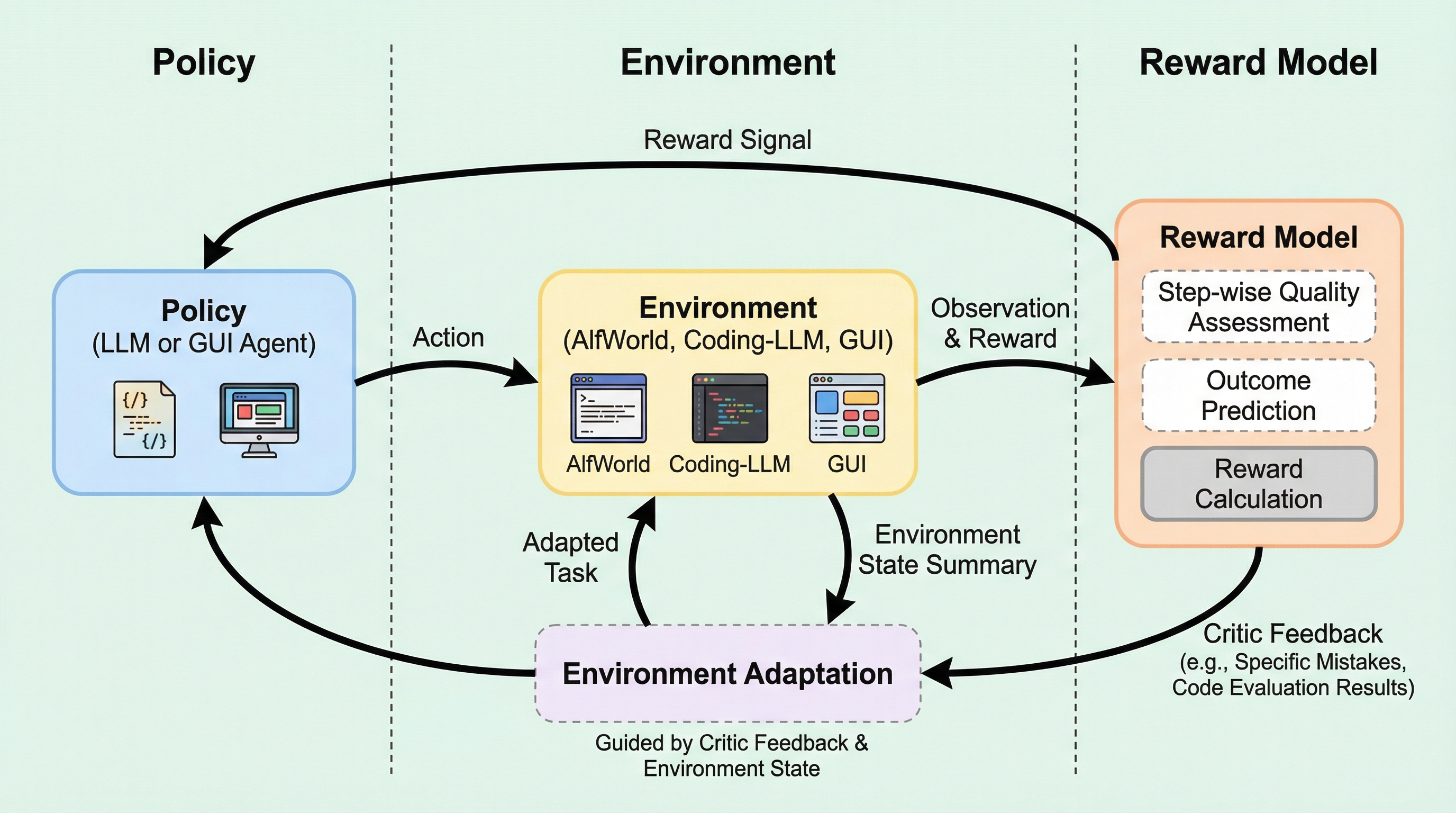
自然言語で動くエージェントは、なぜ「最後の正解・不正解」だけでは育ちにくいのか? 答えは、長い軌跡を進むほど“途中の学びの手がかり”が痩せていくからです。 この記事では、環境・方策・報酬モデルを閉ループで鍛え合う「RLAnything」が何を狙い、どう効いたのかを、読み物としてほどきます。
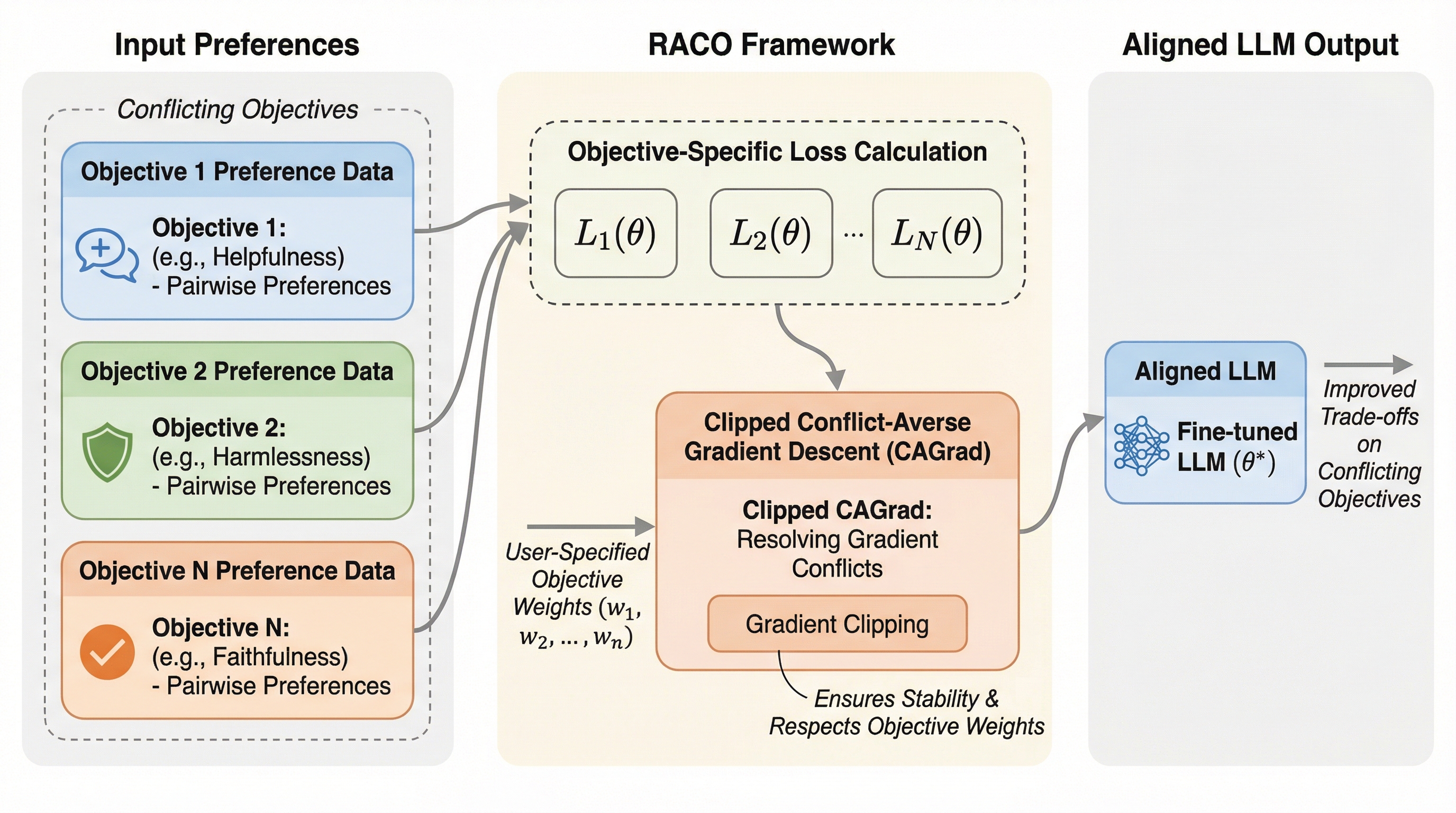
大規模言語モデルを「安全にしつつ、役にも立つ」ように整えるには、結局どこで折り合いをつけるべき? 実はその折り合いは、目的を足し算した瞬間に崩れやすい——学習が不安定になり、トレードオフも悪化しうる。 この記事では、報酬モデルなしで“衝突する目的”をさばく提案「RACO」が何を変えるのかを、筋道立てて追いかけます。
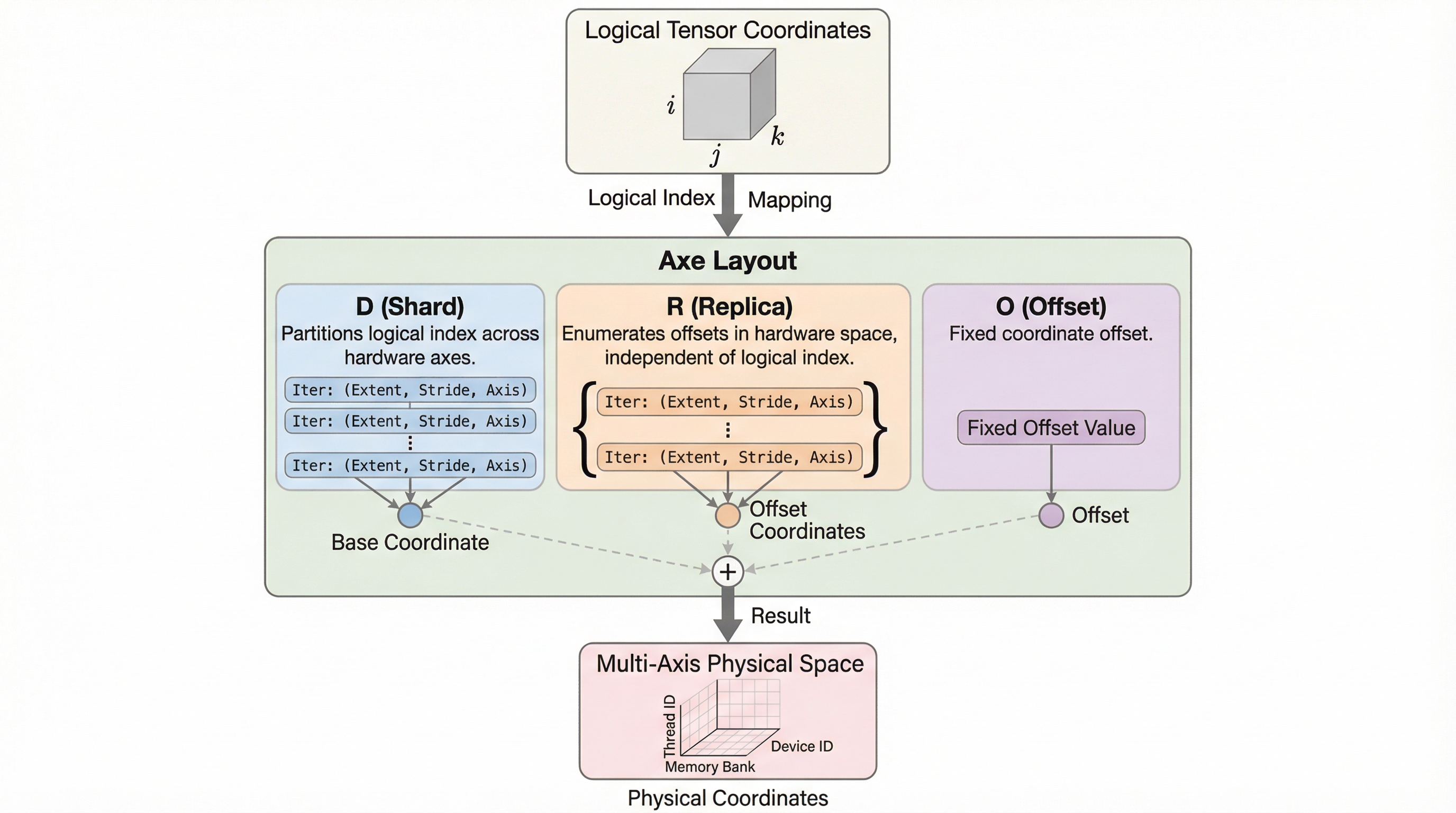
モデルの「分散」と「カーネル最適化」は、同じ言葉で語れないまま別々に進化してきたのでは? 分散はデバイスメッシュの上で語られ、カーネルはスレッドやメモリ階層の上で語られる──その“距離”が、最適化の議論そのものを難しくしているようにも見えます。
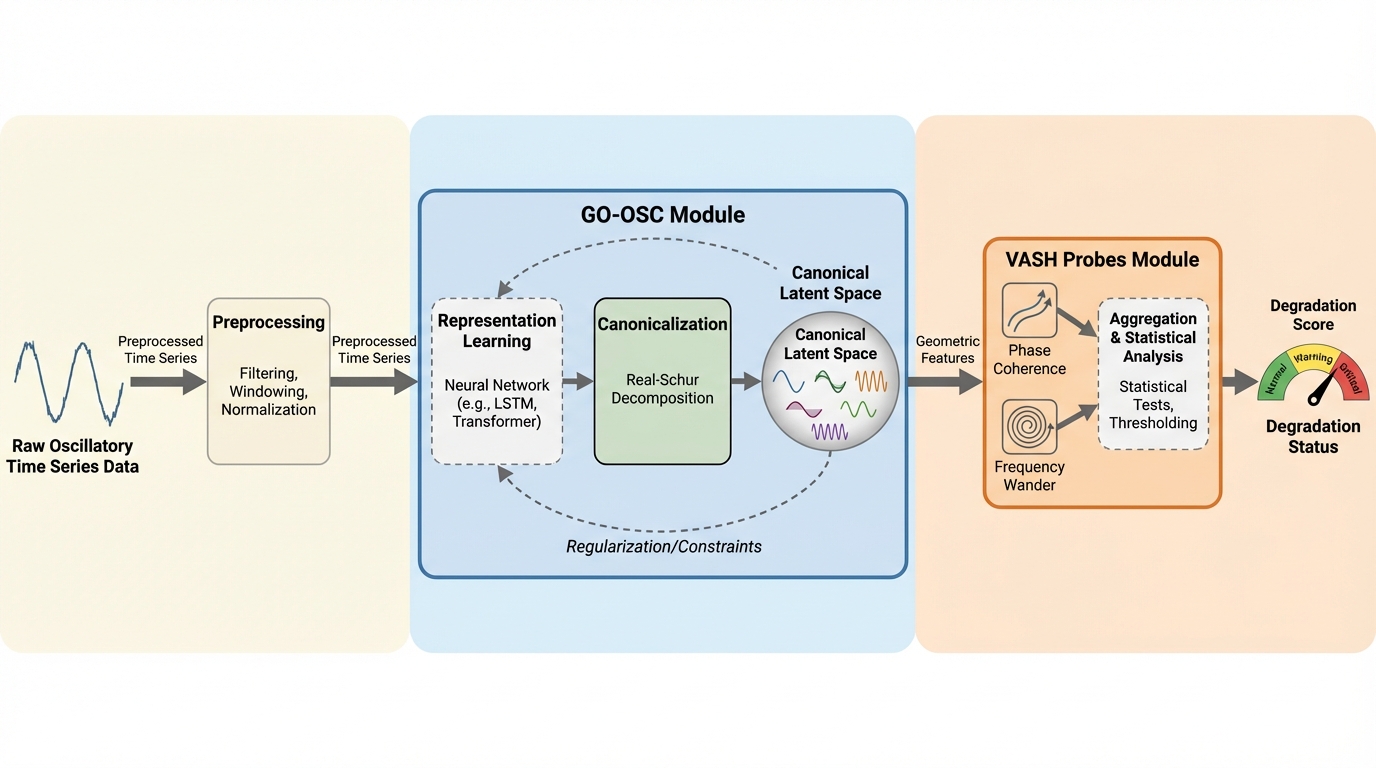
回転機械や電力網などの振動システムにおける初期劣化は、信号エネルギーの変化として現れるよりもずっと前に、位相ジッター、周波数ドリフト、コヒーレンスの喪失といった「ダイナミクスの幾何学的歪み」として発生しますが、従来のエネルギーベースの指標や制約のない学習表現ではこれらを構造的に検知できず、検知の遅れや不安定さを招いていました。 本研究が提案する「GO-OSC」は、潜在空間に「実シュア振動ゲージ」という正準的な幾何学的制約を課すことで、潜在状態空間モデルに固有の相似変換の曖昧さを解消し、異なる時間窓の間で一貫した比較や統計的集約が可能な「特定可能(identifiable)」な表現を学習することで、微細な位相変化を線形に捉えることを可能にします。 この正準表現に基づく幾何学的プローブ群「VASH」は、従来のエネルギー指標と比較して16倍という劇的なデータ効率の向上を達成し、さらに振幅の急激な変化といった外乱に対しても極めて高いロバスト性を維持しながら、物理システムの安全な運用に不可欠な早期故障検知を理論的かつ実践的な基盤の上に実現しました。
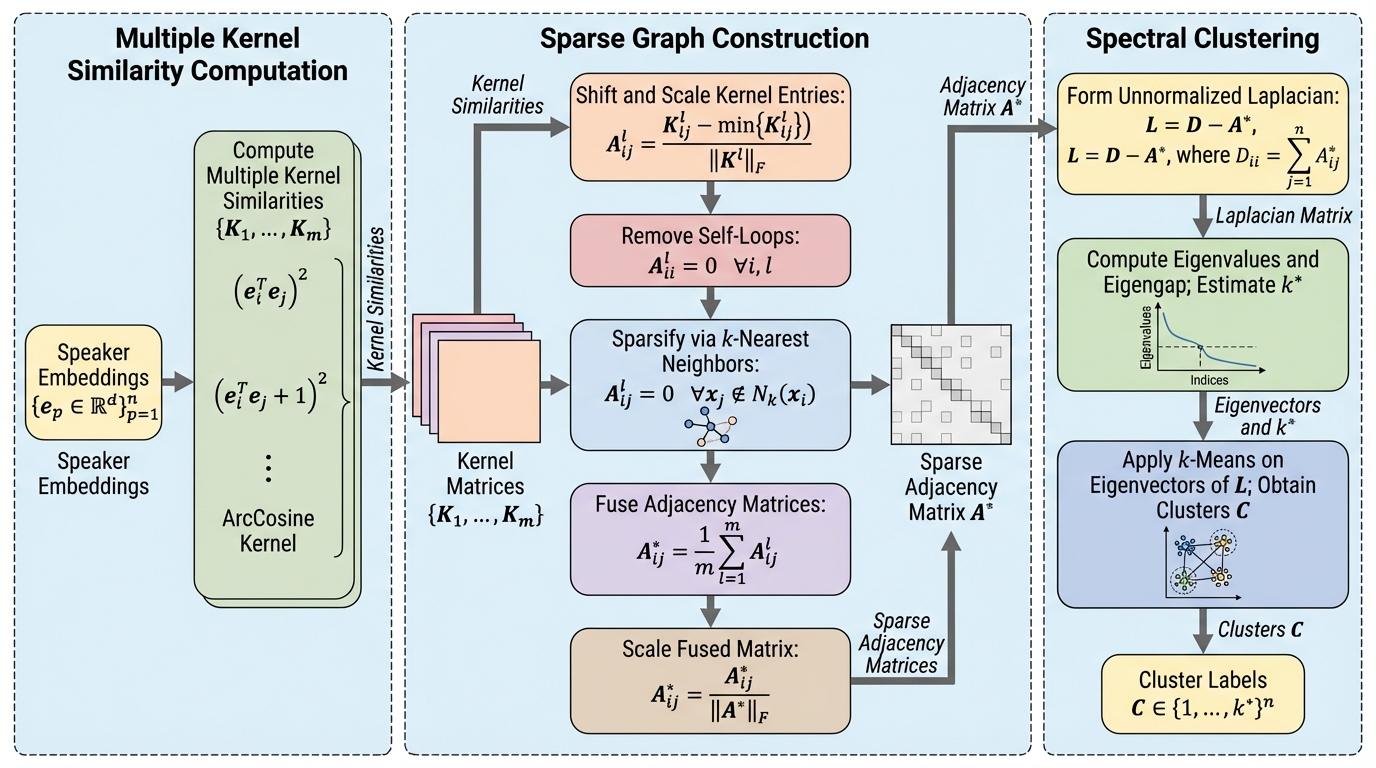
MK-SGC-SCは、4つの多項式カーネルと1つのアークコサインカーネルを統合し、話者埋め込み間の類似性を多角的に評価することで、事前学習や外部の教師情報を一切必要としない完全な教師なし設定において最高水準のダイアリゼーション精度を達成する手法である。