Divide-and-Conquer推論のためのLLM学習がテスト時スケーラビリティを高める
難問に挑むとき、長いチェーン・オブ・ソート(CoT)を伸ばすだけで本当に足りる? 意外にも、分割統治(Divide-and-Conquer)を“推論時に足す”だけでは、多くのモデルでうまく噛み合わない。
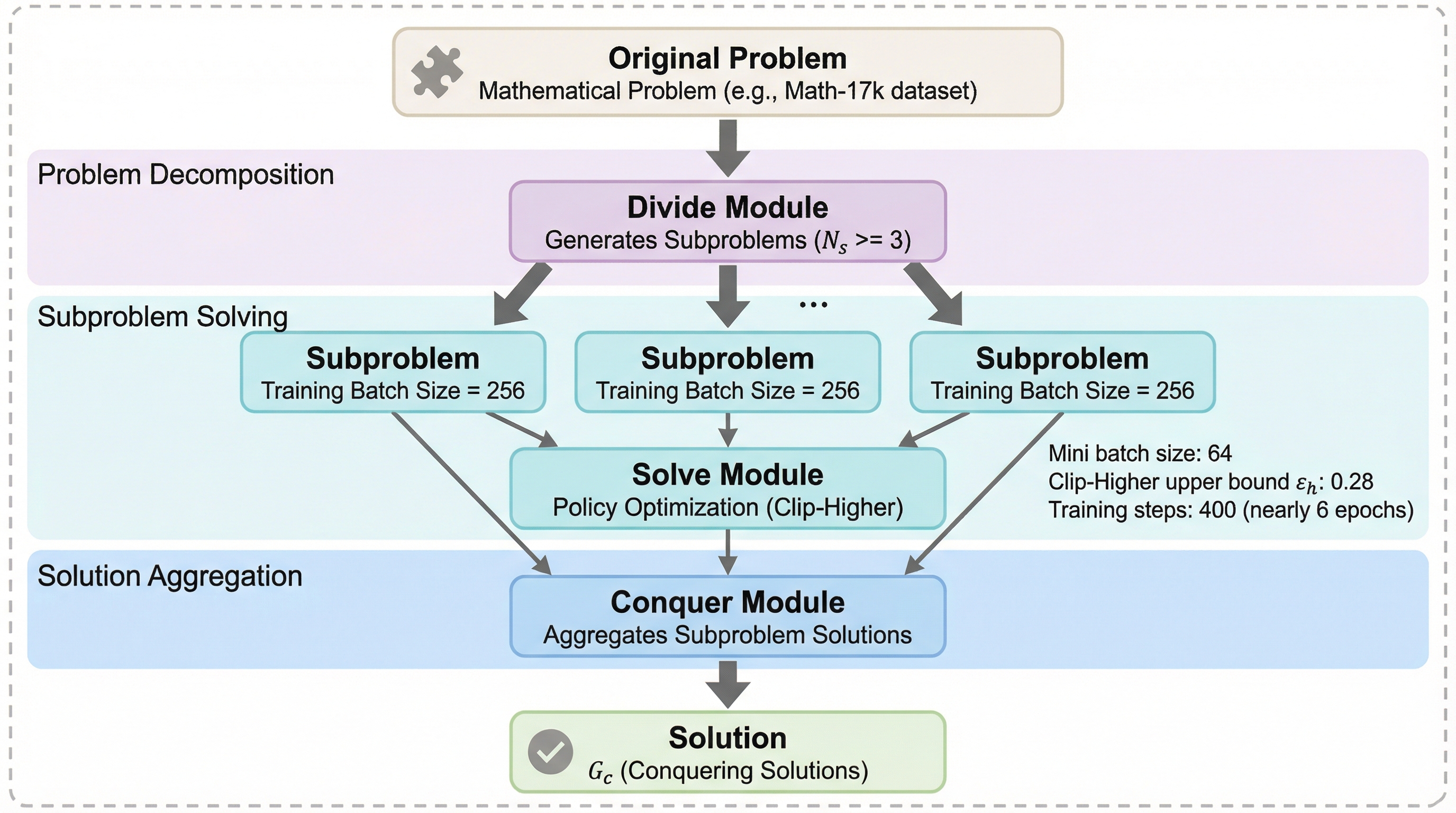
論文図解
TL;DR(結論)
- CoTは強力だが、能力限界では不十分になりやすく、逐次性がテスト時のスケールも縛る。できることが増えるほど手順が長くなり、長さを足しても伸び方が頭打ちになりやすい、という問題設定が置かれている。
- 提案はDAC-RL:分割(division)と解決(conquering)を一体化して強化学習で鍛え、DAC推論に“噛み合う学習”を作る。推論時の工夫を後付けするのではなく、推論の流儀そのものを訓練の中に入れて整合させる。
なぜこの問題か
LLMの推論力を語るとき、まず出てくるのがステップバイステップのCoTです。実際、CoTは「考えを順に積み上げる」ことで強い推論を見せてきましたし、推論の見通しを良くする手段としても広く扱われてきました。問題の途中経過がテキストとして残るため、モデルがどこで詰まったか、どの前提に寄りかかったかも見えやすい、という利点もあります。
核心:何を提案したのか
提案は DAC-RL。分割統治型の推論を、推論時の小技ではなく「学習で身につける対象」にしてしまう、統一的な強化学習(RL)フレームワークです。ここでのポイントは、DACを“手続き”として導入するだけで終わらせず、その手続きを前提とした行動が報酬設計と一緒に最適化されるように組むことにあります。推論の型が変わるなら、型に合わせて学習も変えるべきだ、という立場が貫かれます。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related