KVSlimmer:非対称KVマージを理論化し、長文脈推論のメモリ負荷を下げる
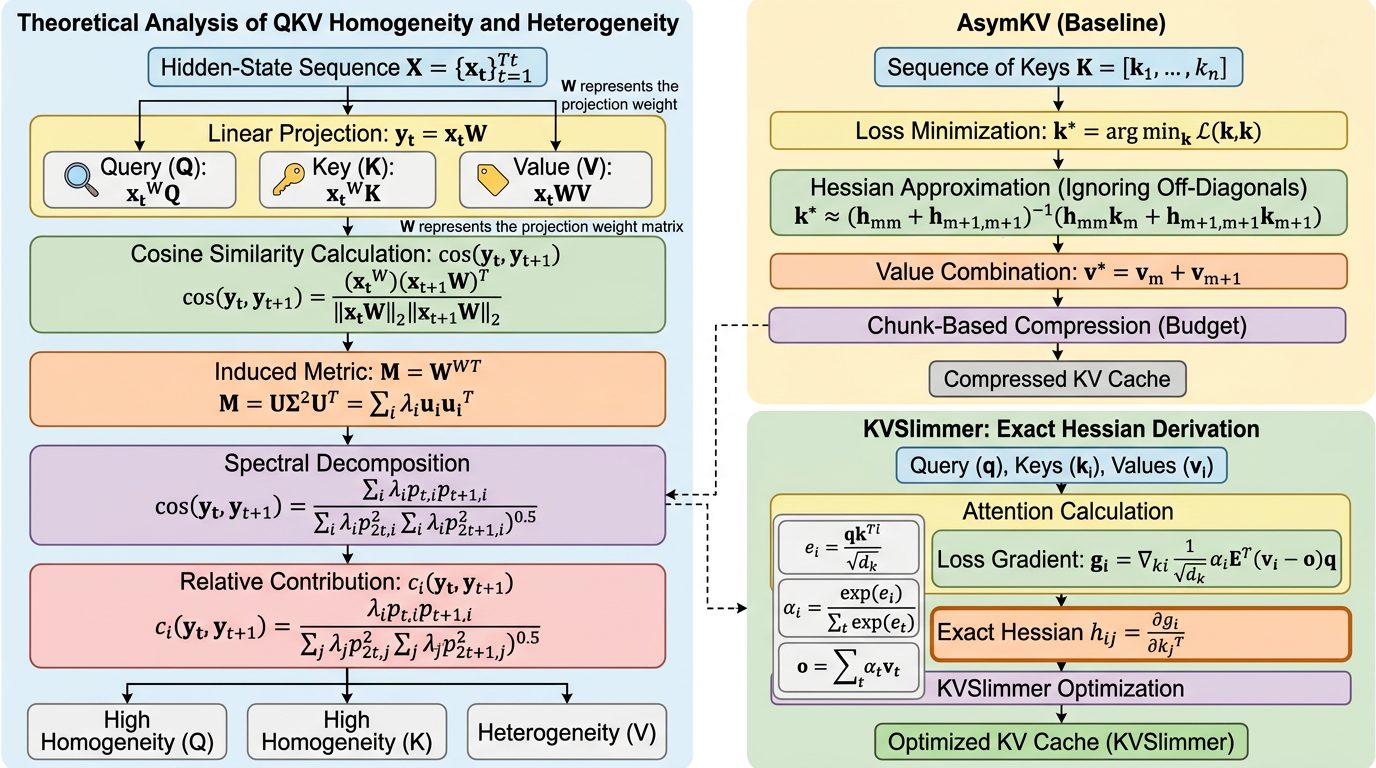
KVSlimmer は、KV キャッシュ圧縮で経験則として語られてきた「Key は似やすく、Value は似にくい」という非対称性を、投影重みのスペクトルエネルギー分布から理論的に説明し、その性質に沿って圧縮を行う手法です。 既存法のような勾配ベース近似ではなく、前向き計算だけから exact Hessian を扱える閉形式へ落とし込み、gradient-free でメモリ効率と速度の両方を改善します。 Llama3.1-8B-Instruct では LongBench 平均を 0.92 改善しつつ、メモリ 29%、レイテンシ 28% を削減しており、KV キャッシュ削減が「安くなる代わりに性能が落ちる」という固定観念をかなり崩しています。
論文図解
TL;DR(結論)
- KVSlimmer は、KV キャッシュ圧縮で経験則として語られてきた「Key は似やすく、Value は似にくい」という非対称性を、投影重みのスペクトルエネルギー分布から理論的に説明し、その性質に沿って圧縮を行う手法です。
- 既存法のような勾配ベース近似ではなく、前向き計算だけから exact Hessian を扱える閉形式へ落とし込み、gradient-free でメモリ効率と速度の両方を改善します。
- Llama3.1-8B-Instruct では LongBench 平均を 0.92 改善しつつ、メモリ 29%、レイテンシ 28% を削減しており、KV キャッシュ削減が「安くなる代わりに性能が落ちる」という固定観念をかなり崩しています。
なぜこの問題か
KV キャッシュは、自己回帰生成のたびに蓄積される過去トークンの表現です。長文脈になるほどここが巨大化し、特に大きなモデルでは「計算はまだ回るがメモリが持たない」という状態が起きやすくなります。実際、論文でも単一 H100 で Llama 系の長文脈条件を回す際、AdamW ベースの学習や勾配を伴う近似法は厳しい制約に直面しています。
核心:何を提案したのか
提案の核心は二段構えです。第一に、Q/K 投影と V 投影のスペクトルエネルギー分布の違いが、隣接トークン表現の同質性・異質性を生むという理論枠組みを与えています。Q/K のスペクトルが集中していると、特徴は似通いやすくなり、隣接 Key はまとめやすい。一方で V はスペクトルが分散しており、情報が多様に残るので、同じようにまとめると情報損失が大きくなりやすい、という説明です。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related