AgentRx:実行軌跡からAIエージェントの失敗を診断する
AIエージェントが失敗したとき、「どの一手が致命傷だったのか?」を言い当てられますか? 意外に難しいのは、失敗が“最後の出力”ではなく、長い実行の途中で静かに始まっているからです。 この記事では、失敗の原因を実行軌跡から切り分ける「AgentRx / AGENTRX」が何を狙い、どう動き、何を確かめたのかを読み物として整理します。
論文図解
TL;DR(結論)
- AgentRxは、失敗したAIエージェントの実行軌跡から「最初の致命的な失敗ステップ」を特定することを目指す。 単なる“失敗理由っぽい説明”ではなく、どの時点で回復不能になったかをはっきり指すことに焦点がある。
- 115本の失敗軌跡に「致命ステップ」と「失敗カテゴリ」を付けたベンチマークを用意し、診断の土台を作った。 “成功率”ではなく“壊れた場所”を評価できるようにする、という問題設定そのものを前に進めている。
- AgentRxは、失敗したAIエージェントの実行軌跡から「最初の致命的な失敗ステップ」を特定することを目指す。
なぜこの問題か
AIエージェントの失敗は、「失敗した」という事実だけなら分かります。厄介なのは、どこで失敗が決定的になったかを局所化しにくいことです。論文はその理由として、実行が確率的で、長い手順をまたぎ、複数エージェントが絡み、さらにツール出力がノイズを含む点を挙げています。ここが重なると、同じタスクでも失敗の現れ方が揺れ、原因が“その場の一回限りの偶然”に見えてしまうのがややこしいところです。
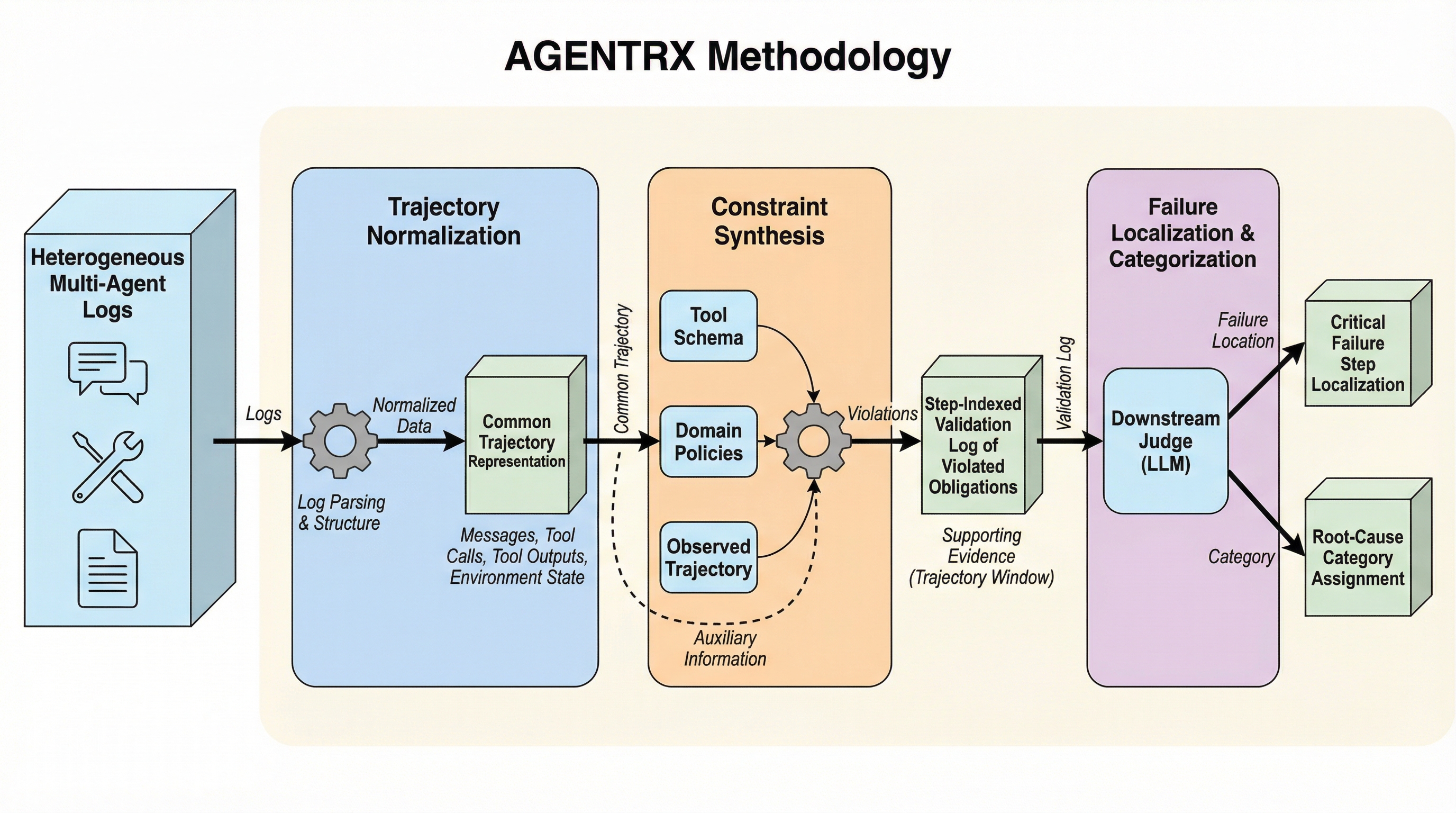
核心:何を提案したのか
提案は大きく2つです。 1つ目は、失敗した実行軌跡に手作業で注釈を付けたベンチマークです。115本の失敗軌跡を集め、各軌跡に「致命的な失敗ステップ」と、 grounded-theory に基づくクロスドメインの失敗分類(failure taxonomy)を付与した、とされています。ここで重要なのは、失敗を“まとめて一件”として扱わず、軌跡の中の一点(ステップ)に着地させる設計が、ベンチマークの段階から組み込まれていることです。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related