テキストフィードバックによる強化学習の能力拡張
あなたは「一発で良い答え」を求めるのに、学習中のLLMはなぜ“やり取り”に頼りがちなのでしょうか? 実は、RLの学習信号は「正解/不正解」の1ビットに近く、豊かな改善の手がかりを捨てている可能性があります。
論文図解
TL;DR(結論)
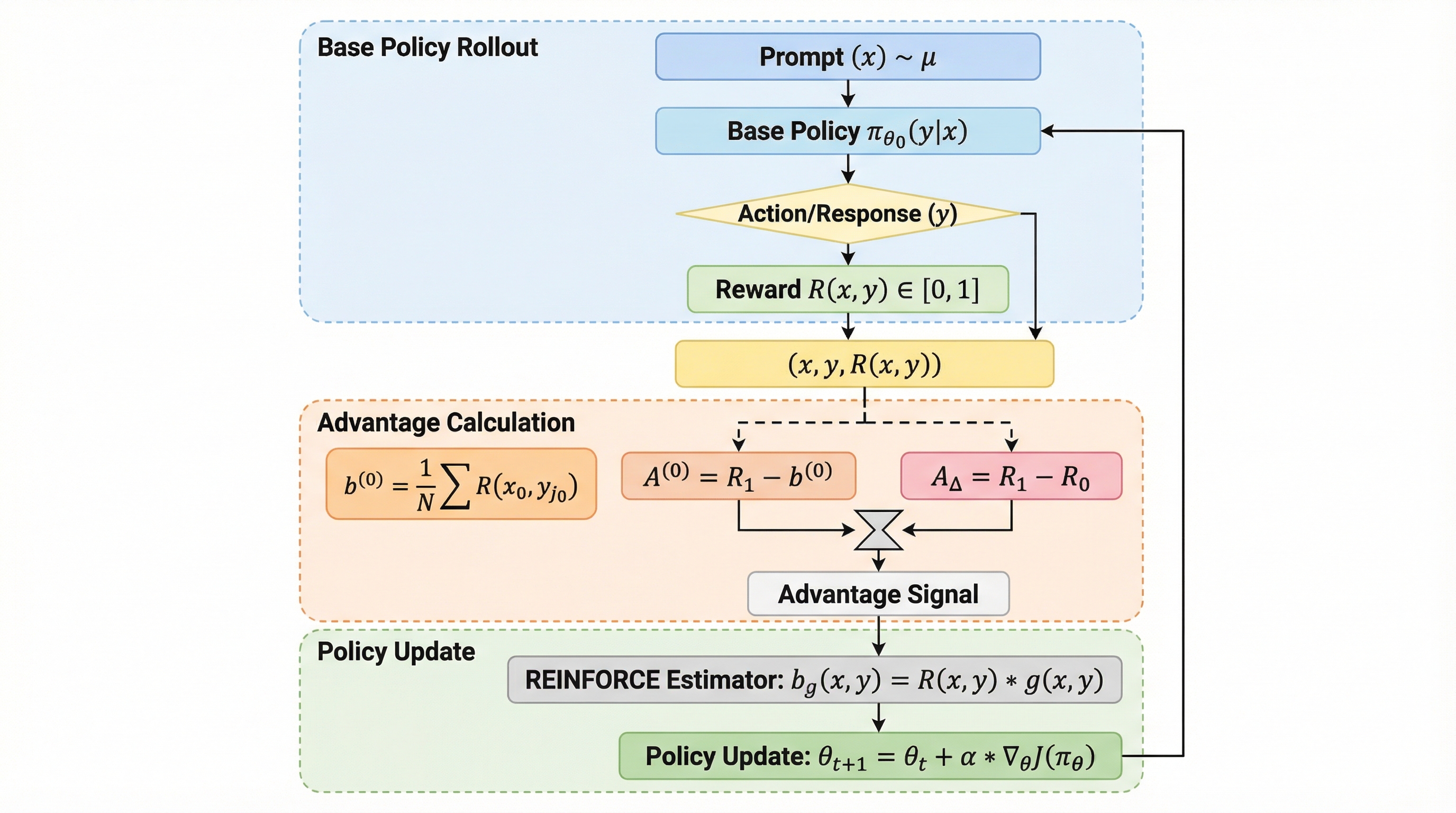
- 論文はまず、マルチターンの枠組みとして RL from Text Feedback(RLTF) を定式化します。
- ポイントはシンプルで、学習中はテキストフィードバックがあるが、推論時はない。
- RLTFの相互作用は、会話っぽい形式で進みます。
なぜこの問題か
LLMのRL後学習がうまくいく背景には、ある“極端さ”がある、と論文は言います。 それは、ロールアウトごとに得られる情報が、二値の報酬や好みラベルという「ほぼ1ビット」だという点です。見方を変えると、学習は進むのに、なぜ良くなったか・どこを直すべきかの「説明」がほとんど渡されていない、という不思議さが残ります。
核心:何を提案したのか
論文はまず、マルチターンの枠組みとして RL from Text Feedback(RLTF) を定式化します。 ポイントはシンプルで、学習中はテキストフィードバックがあるが、推論時はない。だからモデルは、改善の手がかりを「次ターンの入力」ではなく「パラメータ側」に取り込まなければならない。言い換えると、“後から直す力”を“最初から出す力”へ変換することが、この設定の中心目標になります。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related